组合查询
Query Context 和 Filter Context
Query Context:相关度算法
Filter Context:不需要算分,可以利用Cache,获得更好的性能
bool 组合查询
bool查询是一个或者多个查询子句的组合,一共包括4种子句。其中2种会影响算分,2种不影响算分。
相关性并不只是全文检索的专利。也适用于 yes or no 的子句,匹配的子句越多,相关性评分越高。如果多余查询子句被合并为一条复合查询语句,比如 bool 查询,则每个查询子句计算得出的评分将被合并到总的相关性评分中。
| bool查询子句 | 说明 |
|---|---|
| must | 必须匹配,贡献算分 |
| should | 选择性匹配,贡献算分 |
| must_not | Filter Context。查询句子,必须不能匹配 |
| filter | Filter Context。必须匹配,但是不贡献算分 |
# my_index:索引名称# query_name:查询字段# query_value: 查询关键字POST my_index/_search{"query": {"bool" : {"must": {"match" : {"query_name" : "query_value"}},"should": {"match" : {"query_name" : "query_value"}},"must_not": {"match" : {"query_name" : "query_value"}},"filter" : {"match" : {"query_name" : "query_value"}}}}}
# my_index:索引名称# query_name:查询字段# query_value: 查询关键字POST my_index/_search{"query": {"bool" : {"must": [{"match" : {"query_name" : "query_value"}},{"match" : {"query_name" : "query_value"}}],"should": [{"match" : {"query_name" : "query_value"}},{"match" : {"query_name" : "query_value"}}],"must_not": [{"match" : {"query_name" : "query_value"}},{"match" : {"query_name" : "query_value"}}],"filter" : [{"match" : {"query_name" : "query_value"}},{"match" : {"query_name" : "query_value"}}]}}}
算分控制
# my_index:索引名称# query_name:查询字段# query_value: 查询关键字POST my_index/_search{"query": {"bool" : {"must": {"match" : {"query_name" : {"query": "query_value","boost": 1.1}}}}}}
多层嵌套
Elasticsearch 支持多字符串多字段嵌套,相对于放在同一层,多层嵌套存在不同的相关度结果,这是由相关度算法方式决定的。
bool 查询运行每个 match 查询,再把评分加在一起,然后将结果与所有匹配的语句数量相乘,最后除以所有的语句数量。
在以下例子中,被嵌套的 检索值2 和 检索值3 只占总相关度的 1/3,而如果不被嵌套放在同一层,每个字段都将占总相关度的 1/4。
# my_index:索引名称# query_name:查询字段# query_value: 查询关键字POST my_index/_search{"query": {"bool" : {"should": [{"term" : {"query_name" : "query_value0"}},{"term" : {"query_name" : "query_value1"}},{"bool" : {"should": [{"query_name" : "query_value2"},{"query_name" : "query_value3"}]}}]}}}
理想与现实的差距
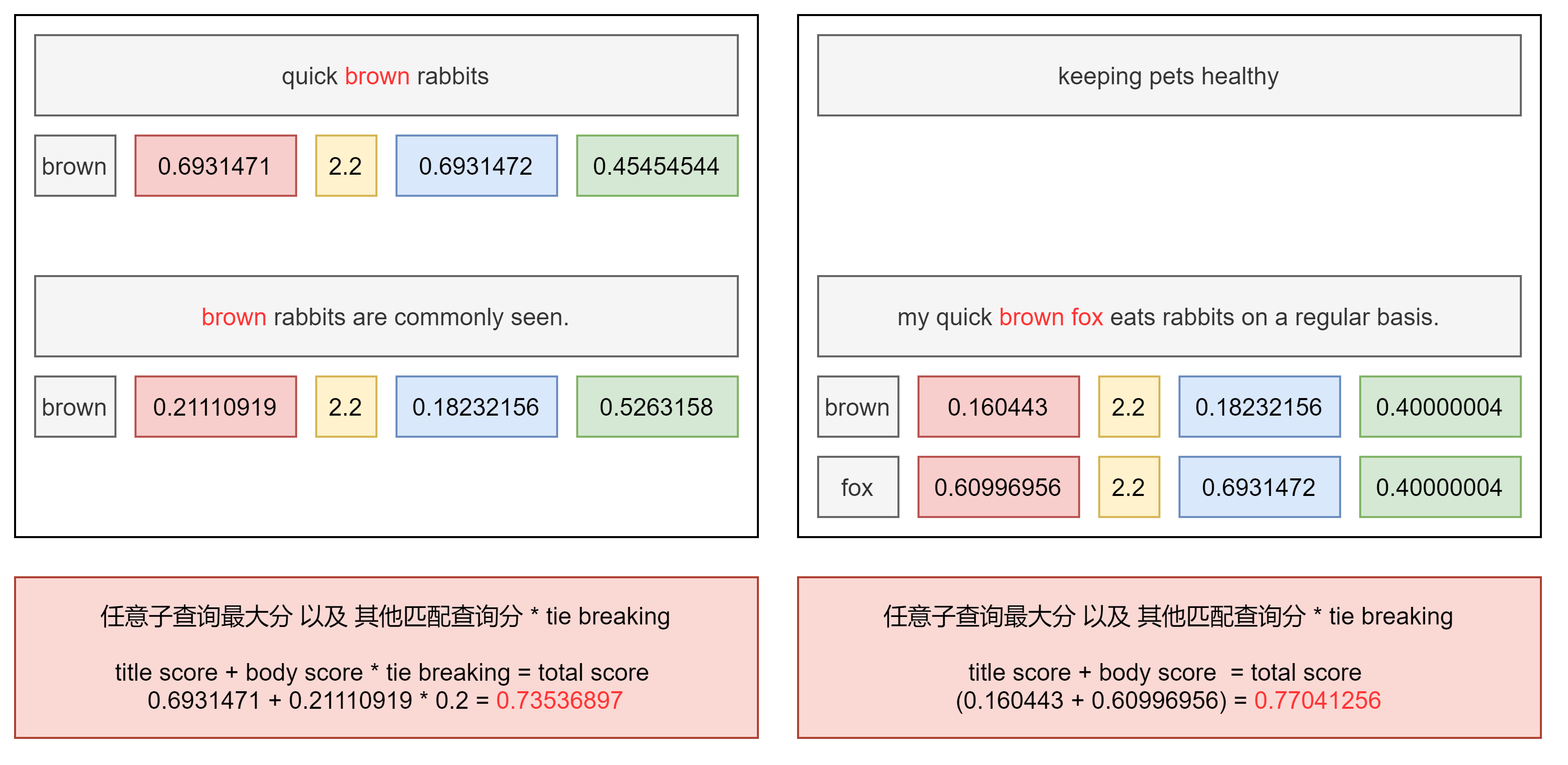
在以下的案例中,文档1标题和内容含有查询关键字中的Brown,但是其描述的内容实际与Brown fox毫不相干,而文档2内容中完整的包含了Brown fox,但标题中并无匹配。在业务场景中,我们其实更倾向于文档2排序在前面(相关度更高),但是实际上 bool 查询会将文档1排序在前面。
PUT /blogs/_doc/1{"title": "Quick brown rabbits","body": "Brown rabbits are commonly seen."}PUT /blogs/_doc/2{"title": "Keeping pets healthy","body": "My quick brown fox eats rabbits on a regular basis."}POST /blogs/_search{"query": {"bool": {"should": [{ "match": { "title": "Brown fox" }},{ "match": { "body": "Brown fox" }}]}}}
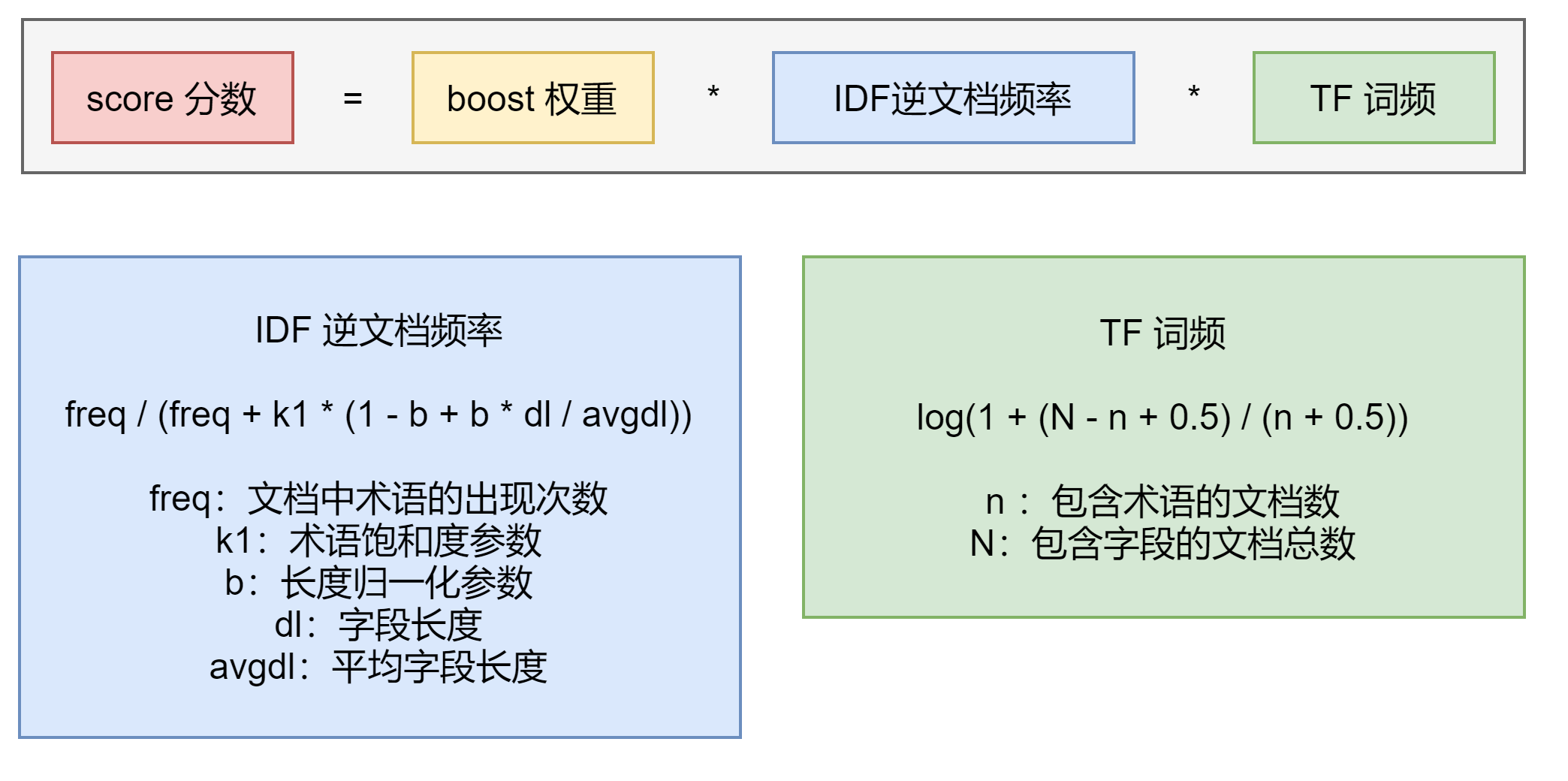
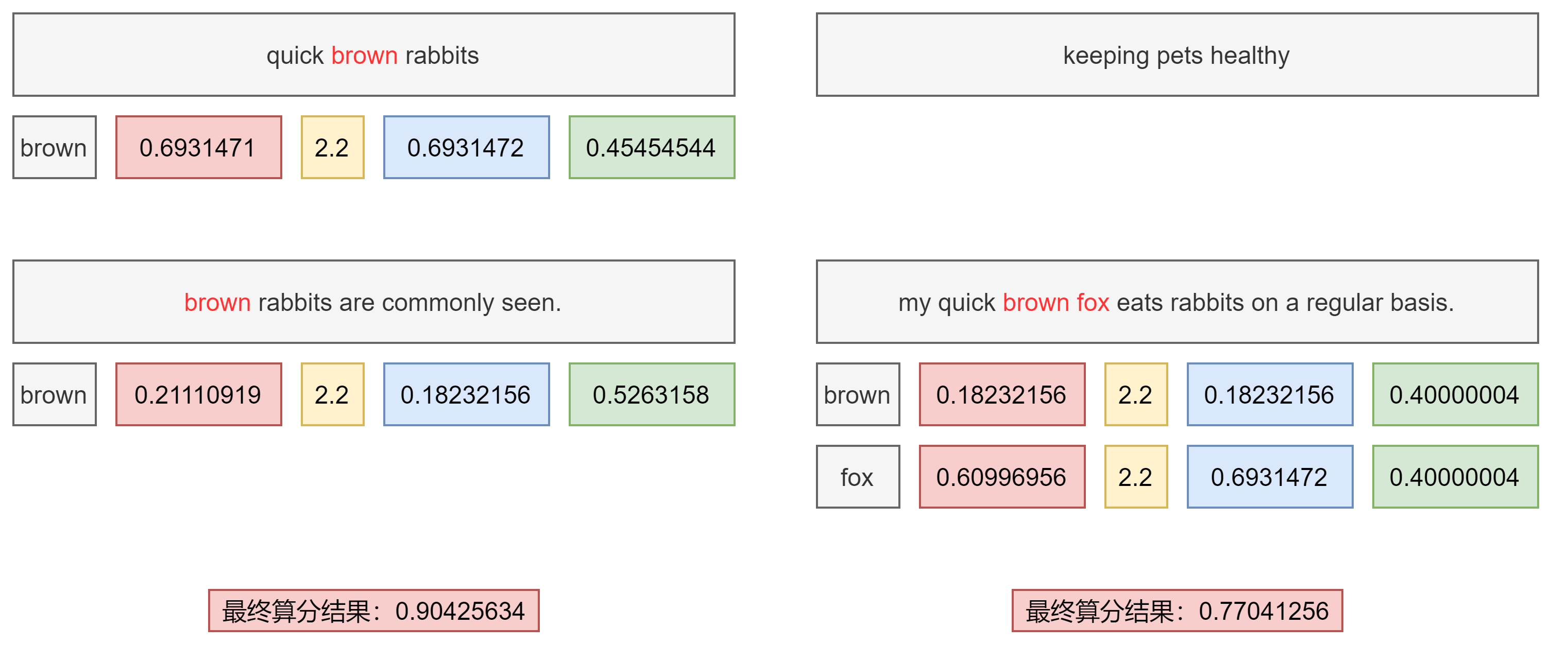
Dis Max Query 查询
此查询生成由其子查询生成的文档的并集,并为每个文档分配由任意子查询生成的该文档的最大分数,以及任何其他匹配子查询的分数增量即 tie breaking 属性。 当在具有不同增压因子的多个字段中搜索字词(使得字段不能等价地组合到单个搜索字段中)时,这是有用的。我们希望主分数是与最高提升相关联的分数,而不是字段分数的总和(如布尔查询将给出的)
# blogs:索引名称# title/body:查询字段PUT /blogs/_doc/1{"title": "Quick brown rabbits","body": "Brown rabbits are commonly seen."}PUT /blogs/_doc/2{"title": "Keeping pets healthy","body": "My quick brown fox eats rabbits on a regular basis."}POST /blogs/_search{"query": {"dis_max": {"queries": [{ "match": { "title": "Brown fox" }},{ "match": { "body": "Brown fox" }}],"tie_breaker": 0.2}}}
算分过程
- 获得最佳匹配语句的评分 score
- 将其他匹配语句的评分与 tie breaker 相乘(tier breaker 是一个介于 0-1 之间的浮点数)
- 对以上评分求和和规范化
Multi Match Query 多字段查询
# my_index:索引名称# query_name:查询字段# query_value: 查询关键字# best_fields:多字段查询的类型GET /my_index/_search{"query": {"multi_match" : {"type": "best_fields","query": "query_value","fields": [ "query_name0", "query_name1" ],"tie_breaker": 0.2}}}
# my_index:索引名称# query_name:查询字段# query_value: 查询关键字# best_fields:多字段查询的类型GET /my_index/_search{"query": {"multi_match" : {"type": "best_fields","query": "query_value","fields": [ "query_name^10" "test*"],"tie_breaker": 0.2}}}
多字段查询的类型
- best_fields: (默认) 查找与任何字段匹配的文档,使用最佳字段中的权重。 等同于Dis Max Query 查询。
- most_fields: 查找与任何字段匹配的文档,并组合每个字段的权重。在处理英文内容时,在主字段抽取词干,加入同义词,以匹配更多的文档;相同的文本,加入子字段,以提供更加精确的匹配,其他字段作为匹配文档提高相关度的信号,匹配字段越多越好。
- cross_fields: 使用相同的分析仪处理字段,就像它们是一个大字段。 在任何字段中查找每个字词。所有术语必须存在于至少一个字段中以供文档匹配。
- phrase: 对每个字段运行match_phrase查询,并合并每个字段的权重。
- phrase_prefix:对每个字段运行match_phrase_prefix查询,并合并每个字段的权重。
多语言与中文分词检索
挑战、演变与现状
混合多语言的挑战
在一些具体的多语言场景下,Elasticsearch面临则一些挑战:不同的索引使用不同的语言;同一个索引中,不同的字段使用不同的语言;一个文档的一个字段内混合不同的语言。
- 词干提取:以色列文档,包含了希伯来语,阿拉伯语,俄语和英文
- 不正确的英文频率:英文为主的文章中,德文算分高(稀有)
- 需要判断用户搜索时候使用的语言,更具语言,查询不同的索引(语言识别 Compact Language Detector)
分词的挑战
- 英文分词:You’re 分成一个还是多个?Half-baked 是否需要进行切割?
- 中文分词
- 分词标准:哈工大标准中,姓和名分开。HanLP是在一起的。具体情况需定制不同的标准。
- 歧义(组合歧义,交集型歧义,真歧义)
中文分词方法的演变
- 查字典 - 最容易想到的分词方法(北京航空大学的梁南元教授提出)
- 一个句子从左到右扫描一遍。遇到由的词就标示意出来。找到复合词,找最长的。
- 不认识的字串就切割成单字词
- 最小词数的分词理论 - 哈工大王晓龙博士把查字典的方法理论化
- 一句话英国分成数量最小的词串
- 遇到二义性的分割,无能为力(例如:“发展中国家”/“上海大学城书店”)
- 用各种文化规则来解决二义性,都并不成功
- 统计语言模型 - 1990年前后,清华大学电子工程系郭进博士
- 解决了二义性问题,将中文分词的错误率降低了一个数量级。概率问题,动态规划+利用维特比算法快速找到最佳分词
- 基于统计的机器学习算法
- 这类目前常用的算法是HMM、CRF、SVM、深度学习等。比如 Hanlp 分词工具是基于 CRF 算法以 CRF 为例,级别思路是对汉字进行标注训练,不仅考虑了词语出现的频率,还考虑了词语出现的频率,还考虑上下文,具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果。
- 随着深度学习的兴起,也出现了基于神经网络的分词器,有人尝试使用双向LSTM+CRF实现分词器,其本质上是序列标注,据报道其分词器字符准确率可达97.5%。
中文分词器现状
- 中文分词器以统计语言模型为基础,经过几十年的发展,今天级别以及可以看作是一个已经解决的问题。
- 不同分词器的好坏,主要的差别在于数据的使用和工程使用的精度
- 常见的分词器都是使用机器学习算法和词典相结合,一方面能够提高分词准确率,另一方面能够改善领域适应性。
- 目前主流的中文分词器主要有 HanLP、IK。
中文分词器的使用
| ik分词器 | | | —- | —- | | ik_max_word | 文本做最细粒度的拆分 | | ik_smart | 做最粗粒度的拆分 |POST _analyze{"analyzer": "hanlp","text": ["剑桥分析公司多位高管对卧底记者说,他们确保了唐纳德·特朗普在总统大选中获胜"]}
| hanlp 分词器 | |
|---|---|
| hanlp | 默认分词 |
| hanlp_standard | 标准分词 |
| hanlp_index | 索引分词 |
| hanlp_nlp | NLP分词 |
| hanlp_n_short | N-最短路分词 |
| hanlp_dijkstra | 最短路分词 |
| hanlp_speed | 极速词典分词 |
#PinyinPUT /artists/{"settings" : {"analysis" : {"analyzer" : {"user_name_analyzer" : {"tokenizer" : "whitespace","filter" : "pinyin_first_letter_and_full_pinyin_filter"}},"filter" : {"pinyin_first_letter_and_full_pinyin_filter" : {"type" : "pinyin","keep_first_letter" : true,"keep_full_pinyin" : false,"keep_none_chinese" : true,"keep_original" : false,"limit_first_letter_length" : 16,"lowercase" : true,"trim_whitespace" : true,"keep_none_chinese_in_first_letter" : true}}}}}GET /artists/_analyze{"text": ["刘德华 张学友 郭富城 黎明 四大天王"],"analyzer": "user_name_analyzer"}
Search Template 查询模板
通过 Search Template 可以实现职责划分,ES管理人员可以通过创建模板保证搜索的正确性,开发人员仅需要调用相应的模板即可构建相关的搜索。
# template_name:模板名称# {{q}}:占位符POST _scripts/template_name{"script": {"lang": "mustache","source": {"_source": ["title","content"],"size": 20,"query": {"multi_match": {"query": "{{q}}","fields": ["title","content"]}}}}}
# my_index:索引名称# template_name:模板名称# q:对应模板的占位符# "互联网":查询关键字POST /my_index/_search/template{"id":"template_name","params": {"q": "互联网"}}
Index Alias 索引别名
通过 Index Alias 可以给相应的索引添加指定的别名,达到零停机运维,切换指向的索引。
# my_index:索引名称# my_index_alias:索引别名称POST _aliases{"actions": [{"add": {"index": "my_index","alias": "my_index_alias"},"remove": {"index": "my_index","alias": "my_index_alias"}}]}
# my_index:索引名称# my_index_alias:索引别名称POST _aliases{"actions": [{"add": {"index": "my_index","alias": "my_index_alias","filter": {"range": {"rating": {"gte": 4}}}}}]}
Function Score Query 优化算分
在查询结束后,对每一个匹配的文档进行一系列的重新算分,根据新生成的分数进行排序。提供了几种默认的计算分值的函数:
| 修饰符 | 意义 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| weight | 为每一个文档设置一个简单而不被规范化的权重 | ||||||||
| field_value_factor | 使用该数值来修改 _score,例如将“热度”和“点赞数”作为算分的参考因素。 | ||||||||
| random_score | 为每一个用户使用一个不同的,随机算分结果 | ||||||||
| 衰弱函数 | 以某个字段的值作为标准,距离某个值越近得分越高 | ||||||||
| Script Score | 自定义脚本完全控制所需逻辑 |
Field Value Factor 按受欢迎程度提升权重
新的算分 = 老的算分 * field_value_factor 设定 field 字段值 由于算法,如果 field_value_factor 的字段值特别大或者特别小,会极大的影响权重,导致某些搜索常见失真。这个个时候我们也可以使用 Modifier 平滑曲线。

# blogs:索引名称# "popularity":查询关键字PUT /blogs/_doc/1{"title": "About popularity","content": "In this post we will talk about...","votes": 0}PUT /blogs/_doc/2{"title": "About popularity","content": "In this post we will talk about...","votes": 100}PUT /blogs/_doc/3{"title": "About popularity","content": "In this post we will talk about...","votes": 1000000}POST /blogs/_search{"query": {"function_score": {"query": {"multi_match": {"query": "popularity","fields": [ "title", "content" ]}},"field_value_factor": {"field": "votes"}}}}
Modifier 平滑曲线
# blogs:索引名称# "popularity":查询关键字POST /blogs/_search{"query": {"function_score": {"query": {"multi_match": {"query": "popularity","fields": [ "title", "content" ]}},"field_value_factor": {"field": "votes","modifier": "log1p"}}}}
| 修饰符 | 意义 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| none | 不要对字段值应用任何乘数。 | ||||||||
| log | 取字段值的常用对数。因为这个函数在0到1之间的值上使用会返回负值并导致错误,所以建议改用log1p。 | ||||||||
| log1p | 取字段值加 1 并取常用对数。 | ||||||||
| log2p | 取字段值加 2 并取常用对数。 | ||||||||
| ln | 取字段值的自然对数。因为这个函数在0到1之间的值上使用会返回负值并导致错误,所以建议改用ln1p。 | ||||||||
| ln1p | 字段值加 1 并取自然对数。 | ||||||||
| ln2p | 字段值加 2 并取自然对数。 | ||||||||
| square | 将字段值平方(乘以它自己) | ||||||||
| sqrt | 取字段值的平方根 | ||||||||
| reciprocal | 交互字段值,与字段值的 1/x 位置相同的 x |
引入 Factor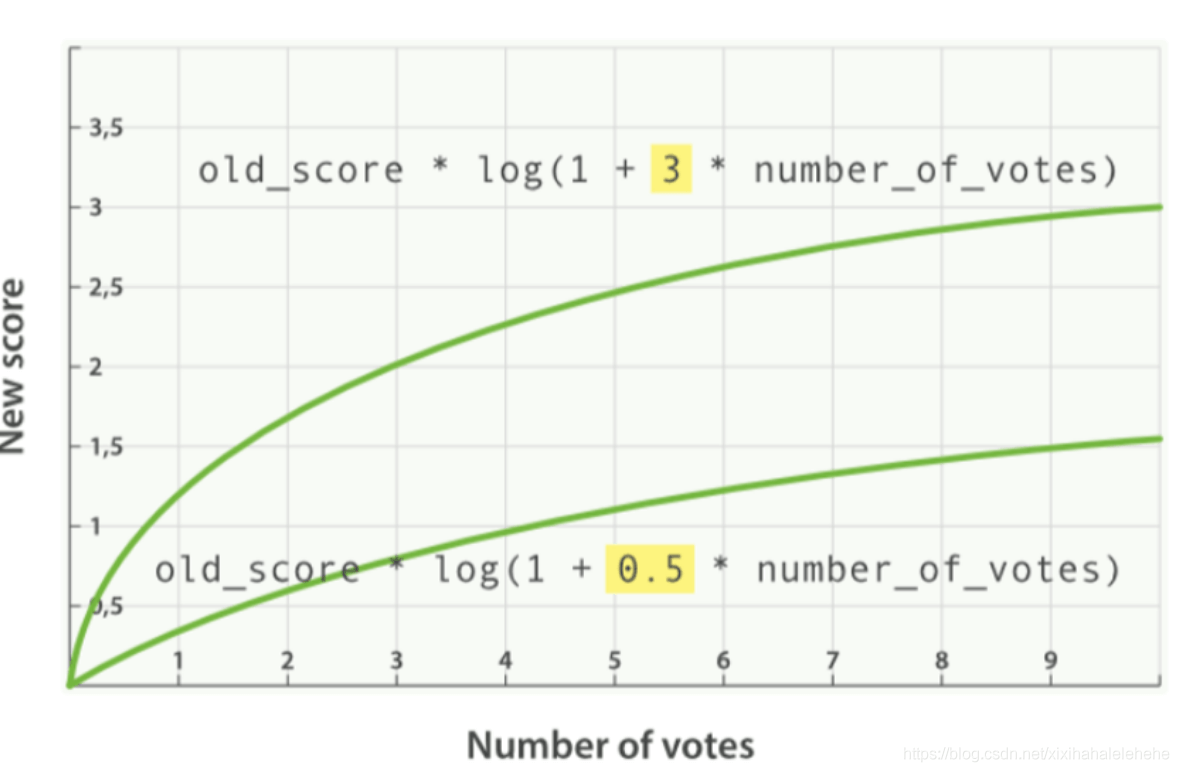
新的算分 = 老的算分 log(1 + factor field_value_factor 设定 field 字段值)
# blogs:索引名称# "popularity":查询关键字POST /blogs/_search{"query": {"function_score": {"query": {"multi_match": {"query": "popularity","fields": [ "title", "content" ]}},"field_value_factor": {"field": "votes","modifier": "log1p","factor": 0.1}}}}
Boost Mode 和 Max Boost
Boost Mode 指定如何组合计算的分数;Max Boost 可以通过设置参数来限制新的分数不超过一定的限制。
| 修饰符 | 意义 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| multiply | 分数相乘(默认) | ||||||||
| sum | 分数相加 | ||||||||
| avg | 平均分数 | ||||||||
| first | 应用具有匹配过滤器的第一个函数 | ||||||||
| max | 使用最高分 | ||||||||
| min | 使用最低分 |

# blogs:索引名称# "popularity":查询关键字POST /blogs/_search{"query": {"function_score": {"query": {"multi_match": {"query": "popularity","fields": [ "title", "content" ]}},"field_value_factor": {"field": "votes","modifier": "log1p" ,"factor": 0.1},"boost_mode": "sum","max_boost": 3}}}
Random Score 一致性随机函数
场景:让每个用户能看到不同的随机排名,但是也希望同一个用户访问时,结果相对顺序,保存一致
# blogs:索引名称# 911119:用户的唯一标识数,用于保证一致性随机POST /blogs/_search{"query": {"function_score": {"random_score": {"seed": 911119}}}}
搜索建议
- 现代搜索引擎,一般都会提供 Suggest as you type 的功能。
- 帮助用户在输入搜索的过程中,进行自动补全或者纠错。通过协助用户输入更加精准的关键词,提高后续搜索阶段文档的匹配程度。
在 google 上搜索,一开始会自动补全。当输入到一定长度,如因为单词拼写错误无法补全,就会开始提示相似的词或者句子。
Elasticsearch Suggester API
搜索引擎中类似的功能,在 Elasticsearch 中是通过 Suggester API 实现。
- 实现原理是将输入的文本分解为 Token,然后在索引字典查找相似的 Term 并返回
- 根据不同的使用场景,Elasticsearch 设计了4种类别的 Suggester:
| 选项 | 含义 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| test | suggest文本,suggest文本是必须选项,需要被设定为全局或者对每个suggestion。 | ||||||||
| suggest_mode | 该选项控制什么场景下,建议应该被提出 - missing:如果索引中已经存在,就补提供建议 - popular:推荐出现频率更高的词 - always:无论是否存在,都提供建议 |
||||||||
| field | 从中获取候选建议的字段 | ||||||||
| prefix_length | 不能没模糊化的初始字符数 |
Term Suggestion
# articles:索引名称# term-suggestion:建议名称,用于返回结果POST /articles/_search{"suggest": {"term-suggestion": {"text": "lucen rock","term": {"suggest_mode": "missing","field": "body","prefix_length":0,"sort": "frequency"}}}}
Phrase Suggester
Phrase Suggester 在 Term Suggester 的基础上增加了一些额外的逻辑。
| 选项 | 含义 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| max_errors | 最多可以拼写错误的 Terms 数, 默认值设置为1.0。将其设置过高可能会对性能产生负面影响。 推荐使用低值,例如1或2。 | ||||||||
| collate | 限制返回结果数,默认为1 | ||||||||
| highlight | 设置suggestion高亮显示 |
# articles:索引名称# my-suggestion:建议名称,用于返回结果POST /articles/_search{"suggest": {"my-suggestion": {"text": "lucne and elasticsear rock hello world ","phrase": {"field": "body","max_errors":2,"confidence":0,"direct_generator":[{"field":"body","suggest_mode":"always"}],"highlight": {"pre_tag": "<em>","post_tag": "</em>"}}}}}
Complete & Context Suggester
- Completion Suggester 提供了“自动完成”(Auto Complete)的功能。用户每输入一个字符,就需要即时发送一个查询请求到后段查找匹配项。
- 对性能要求比较苛刻。Elasticsearch 采用了不同的数据结构,并发通过倒排索引来完成。而是将 Analyze 的数据编排成 FST 和索引一起存放。FST 会被 ES 整个加载进内存,速度很快。
- FST 只能用于前缀查找。
要使用此功能,请为此字段指定一个特殊映射,为快速完成的字段值编制索引。
# articles:索引名称DELETE /articlesPUT /articles{"mappings": {"properties": {"title_completion":{"type": "completion"}}}}POST /articles/_bulk{ "index" : { } }{ "title_completion": "lucene is very cool"}{ "index" : { } }{ "title_completion": "Elasticsearch builds on top of lucene"}{ "index" : { } }{ "title_completion": "Elasticsearch rocks"}{ "index" : { } }{ "title_completion": "elastic is the company behind ELK stack"}{ "index" : { } }{ "title_completion": "Elk stack rocks"}{ "index" : {} }
# articles:索引名称# article-suggester:建议名称,用于返回结果# "elk":检索的关键字POST /articles/_search?pretty{"size": 0,"suggest": {"article-suggester": {"prefix": "elk ","completion": {"field": "title_completion"}}}}
精准度和召回率
- 精准度: Completion > Phrase > Term
- 召回率:Term > Phrase > Completion
-
跨集群搜索
水平扩展的痛点
单集群 - 当水平扩展时,节点数不能无限增加
- 当集群的 meta 信息(节点、索引、集群状态)过多,回导致更新压力变大,单个 Active Master 会成为性能瓶颈,导致整个集群无法正常工作
早期版本,通过 Tribe Node 可以实现多集群访问的需求,但是存在一定的问题
早期 Tribe Node 的方案存在一定的问题,现在已经被 Deprecated
- Elasticsearch 5.3 引入了跨集群搜索服务( Cross Cluster Search )
- 允许任何节点扮演 federated 节点,以轻量的方式,将搜索请求进行代理
- 不需要以 Client Node 的形式加入其他集群 ```shell //启动3个集群
bin/elasticsearch -E node.name=cluster0node -E cluster.name=cluster0 -E path.data=cluster0_data -E discovery.type=single-node -E http.port=9200 -E transport.port=9300 bin/elasticsearch -E node.name=cluster1node -E cluster.name=cluster1 -E path.data=cluster1_data -E discovery.type=single-node -E http.port=9201 -E transport.port=9301 bin/elasticsearch -E node.name=cluster2node -E cluster.name=cluster2 -E path.data=cluster2_data -E discovery.type=single-node -E http.port=9202 -E transport.port=9302
//在每个集群上设置动态的设置 PUT _cluster/settings { “persistent”: { “cluster”: { “remote”: { “cluster0”: { “seeds”: [ “127.0.0.1:9300” ], “transport.ping_schedule”: “30s” }, “cluster1”: { “seeds”: [ “127.0.0.1:9301” ], “transport.compress”: true, “skip_unavailable”: true }, “cluster2”: { “seeds”: [ “127.0.0.1:9302” ] } } } } }
cURL
curl -XPUT “http://localhost:9200/_cluster/settings“ -H ‘Content-Type: application/json’ -d’ {“persistent”:{“cluster”:{“remote”:{“cluster0”:{“seeds”:[“127.0.0.1:9300”],”transport.ping_schedule”:”30s”},”cluster1”:{“seeds”:[“127.0.0.1:9301”],”transport.compress”:true,”skip_unavailable”:true},”cluster2”:{“seeds”:[“127.0.0.1:9302”]}}}}}’
curl -XPUT “http://localhost:9201/_cluster/settings“ -H ‘Content-Type: application/json’ -d’ {“persistent”:{“cluster”:{“remote”:{“cluster0”:{“seeds”:[“127.0.0.1:9300”],”transport.ping_schedule”:”30s”},”cluster1”:{“seeds”:[“127.0.0.1:9301”],”transport.compress”:true,”skip_unavailable”:true},”cluster2”:{“seeds”:[“127.0.0.1:9302”]}}}}}’
curl -XPUT “http://localhost:9202/_cluster/settings“ -H ‘Content-Type: application/json’ -d’ {“persistent”:{“cluster”:{“remote”:{“cluster0”:{“seeds”:[“127.0.0.1:9300”],”transport.ping_schedule”:”30s”},”cluster1”:{“seeds”:[“127.0.0.1:9301”],”transport.compress”:true,”skip_unavailable”:true},”cluster2”:{“seeds”:[“127.0.0.1:9302”]}}}}}’
创建测试数据
curl -XPOST “http://localhost:9200/users/_doc“ -H ‘Content-Type: application/json’ -d’ {“name”:”user1”,”age”:10}’
curl -XPOST “http://localhost:9201/users/_doc“ -H ‘Content-Type: application/json’ -d’ {“name”:”user2”,”age”:20}’
curl -XPOST “http://localhost:9202/users/_doc“ -H ‘Content-Type: application/json’ -d’ {“name”:”user3”,”age”:30}’
查询
GET /users,cluster1:users,cluster2:users/_search { “query”: { “range”: { “age”: { “gte”: 20, “lte”: 40 } } } } ```

若有收获,就点个赞吧
0 人点赞
