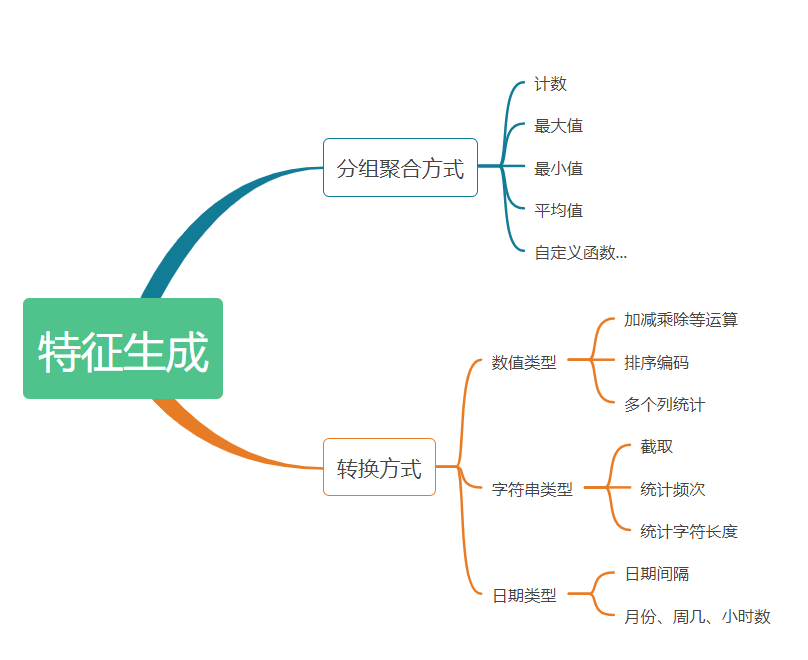
特征生成
特征生成就是从各种角度和侧面来刻画事物。通过对问题的理解,构造一些特征希望机器学习算法可以采纳。
特征与特征间的运算
补集
笛卡儿积
交集
加、减、乘、除运算
特征选择
从给定的特征集合中选出相关特征子集。特征选择过程要确保不丢失重要特征,去除冗余特征。包含两个环节:子集搜索、子集评价。
理由:
缓解维度灾难问题
去除不相关特征往往会降低学习任务的难度
常见的特征选择方法大致可以分为三类:Filter、Wrapper、Embedding。
筛选器(Filter)
基于统计方法找出冗余或无关特征,独立于后续的任何机器学习算法。筛选器一个很大的缺点是扔掉了独立使用时没有 用处的特征,而一些特征看起来跟目标变量完全独立,但是当它们组合在一起就有效果了。
相关性
皮尔逊相关系数(Pearson correlation coefficient):
scipy.stats.pearsonr(),给定两个数据序列 ,会返回相关系数值和p值所组成的元组。皮尔逊相关系数(皮尔逊r值)测量两个序列的线性关系,取值在-1到1之间,-1代表负相关、1代表正相关、0代表不相关。r值:
基于相关性的特征选择方法的一个最大的缺点就是它只能检测出线性关系。
其他
- 特征的方差
- 假设检验:卡方检验、F检验、t检验
互信息
互信息通过计算两个特征所共有的信息,与相关性不同,它依赖的并不是数据序列,而是数据的分布。
优点: 与相关性不同,它并不只关注线性关系。
缺点:计算每对特征之间的归一互信息量,计算量以平方级增长封装器(Wrapper)
让模型选择特征,选择一个目标函数来一步步筛选特征,即直接把最终要使用的学习器的性能作为特征子集的评价准则。效果通常比过滤式特征选择更好,但是计算开销大得多。
sklearn.feature_selection
嵌入法(Embedded)
嵌入式特征选择是将特征选择过程与学习器训练过程融为一体,两者在同一优化过程中完成,即在学习器训练过程中自动进行了特征选择。
决策树模型:深植于其内核的特征选择机制
L1正则化:把效用不大的特征的重要性降低为0
L1范数和L2范数都有助于降低过拟合风险,但前者还会代来一个额外的好处:它比厚泽更易获得“稀疏”(sparse)解,即它求得的w会有更少的非零向量。
特征抽取
试图将原始特征空间转换成一个低维特征空间。有时当我们删掉冗余特征和无关特征后,经常会发现还有过多的特征。线性模型代表:PCA、LDA;非线性:KerelPCA、MDS。
降维度
主成分分析(PCA)
线性模型,无监督方法
性质:
保留方差最大的
最终的重构误差(从变换都特征回到原始特征)是最小的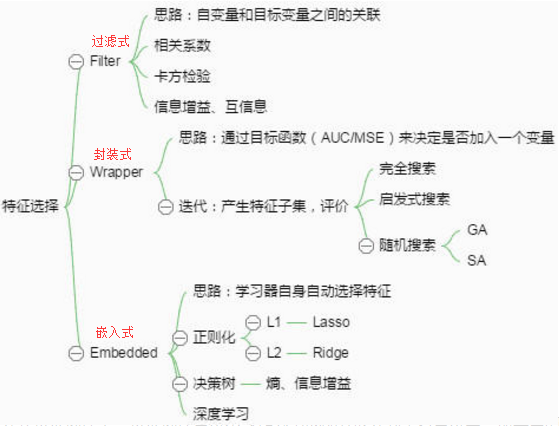
https://blog.csdn.net/cymy001/article/details/79169862
https://blog.csdn.net/fengdu78/article/details/113904358
https://blog.csdn.net/Shingle_/article/details/81987675

若有收获,就点个赞吧
0 人点赞
