:::info
💡 根据 遗忘曲线:如果没有记录和回顾,6天后便会忘记75%的内容
读书笔记正是帮助你记录和回顾的工具,不必拘泥于形式,其核心是:记录、翻看、思考
:::
1. 规范化数据
在执行 PCA 之前标准化数据。这将确保每个特征的均值 = 0 和方差 = 1。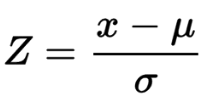
2.构建协方差矩阵
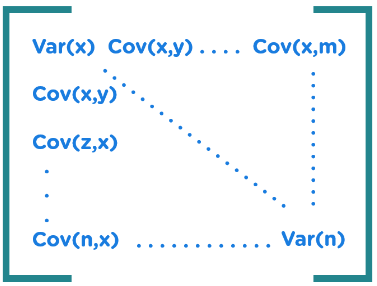
3. 找到特征向量和特征值
计算特征向量/单位向量和特征值。特征值是我们乘以协方差矩阵的特征向量的标量.
。
3.1 矩阵对角化
根据我们的优化条件,我们需要将除对角线外的其它元素化为 0,并且在对角线上将元素按大小从上到下排列(变量方差尽可能大),这样我们就达到了优化目的。这样说可能还不是很明晰,我们进一步看下原矩阵与基变换后矩阵协方差矩阵的关系。
设原始数据矩阵 X 对应的协方差矩阵为 C,而 P 是一组基按行组成的矩阵,设 Y=PX,则 Y 为 X 对 P 做基变换后的数据。设 Y 的协方差矩阵为 D,我们推导一下 D 与 C 的关系:
这样我们就看清楚了,我们要找的 P 是能让原始协方差矩阵对角化的 P。换句话说,优化目标变成了寻找一个矩阵 P,满足  是一个对角矩阵,并且对角元素按从大到小依次排列,那么 P 的前 K 行就是要寻找的基,用 P 的前 K 行组成的矩阵乘以 X 就使得 X 从 N 维降到了 K 维并满足上述优化条件。
是一个对角矩阵,并且对角元素按从大到小依次排列,那么 P 的前 K 行就是要寻找的基,用 P 的前 K 行组成的矩阵乘以 X 就使得 X 从 N 维降到了 K 维并满足上述优化条件。
4. 将特征向量从高到低排序,选择主成分的个数。
代码
https://github.com/heucoder/dimensionality_reduction_alo_codes/blob/master/codes/PCA/PCA.py
4. 性质
- 缓解维度灾难:PCA 算法通过舍去一部分信息之后能使得样本的采样密度增大(因为维数降低了),这是缓解维度灾难的重要手段;
- 降噪:当数据受到噪声影响时,最小特征值对应的特征向量往往与噪声有关,将它们舍弃能在一定程度上起到降噪的效果;
- 过拟合:PCA 保留了主要信息,但这个主要信息只是针对训练集的,而且这个主要信息未必是重要信息。有可能舍弃了一些看似无用的信息,但是这些看似无用的信息恰好是重要信息,只是在训练集上没有很大的表现,所以 PCA 也可能加剧了过拟合;
- 特征独立:PCA 不仅将数据压缩到低维,它也使得降维之后的数据各特征相互独立;
41 零均值化
当对训练集进行 PCA 降维时,也需要对验证集、测试集执行同样的降维。而对验证集、测试集执行零均值化操作时,均值必须从训练集计算而来,不能使用验证集或者测试集的中心向量。
其原因也很简单,因为我们的训练集时可观测到的数据,测试集不可观测所以不会知道其均值,而验证集再大部分情况下是在处理完数据后再从训练集中分离出来,一般不会单独处理。如果真的是单独处理了,不能独自求均值的原因是和测试集一样。
另外我们也需要保证一致性,我们拿训练集训练出来的模型用来预测测试集的前提假设就是两者是独立同分布的,如果不能保证一致性的话,会出现 Variance Shift 的问题。

若有收获,就点个赞吧
0 人点赞
