Error Metrics: How to Evaluate Your Forecasts
How to validate a predictive model
Understanding Loss Functions in Machine Learning
RMSE
https://towardsdatascience.com/what-does-rmse-really-mean-806b65f2e48e
https://towardsdatascience.com/which-evaluation-metric-should-you-use-in-machine-learning-regression-problems-20cdaef258e
https://keras.io/api/losses/regression_losses/#meansquaredlogarithmicerror-function
在考虑任何预测模型的性能时,必须对其产生的预测值进行评估。这是通过计算合适的错误度量来完成的。误差度量是一种量化模型性能的方法,并为预测者提供了一种定量比较不同模型的方法1。它们为我们提供了一种更客观地衡量模型执行任务的方法。
在这篇博文中,我们将介绍一些用于时间序列预测的常用指标、如何解释它们以及每个指标的局限性。一个友好的警告:这涉及一些数学运算,这对于解释这些指标的工作原理是必要的。但是解释和限制被清楚地标记出来,所以你可以直接跳到方程下面的标记部分进行简单的解释。
平均绝对误差 (MAE)
Mean Absolute Error (MAE)
定义: MAE 定义为预测值与真实值之间绝对差的平均值。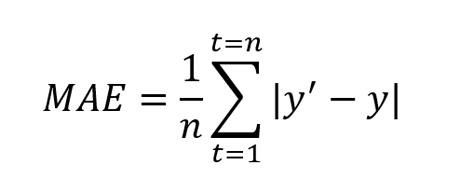
其中y’是预测值,y是真实值。n是测试集中值的总数。MAE 告诉我们预测的平均误差有多大2。误差值采用预测值的原始单位,MAE = 0 表示预测值没有误差。
解释与局限: MAE 值越低,模型越好;零值表示预测中没有错误。换句话说,当比较多个模型时,认为 MAE 最低的模型更好。
然而,MAE 并不表示误差的相对大小,并且很难区分大误差和小误差。它可以与其他指标一起使用(参见下面的均方根误差)来确定误差是否更大。此外,MAE 可以掩盖与低数据量有关的问题;请参阅本文中的最后两个指标来解决该问题。
平均绝对百分比误差 (MAPE)
Mean Absolute Percentage Error (MAPE)
定义: MAPE 定义为预测值与真实值绝对差的平均值除以真实值的百分比。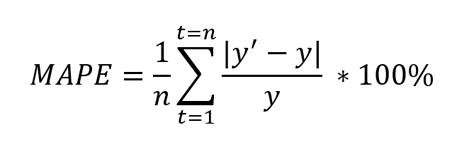
其中y’是预测值,y是真实值。n是测试集中值的总数。由于 in 分母,它最适用于没有零和极值的数据。如果该值极小或极大,MAPE 值也取极值。
解释与局限: MAPE 越低,模型越好。请记住,MAPE 最适用于没有零和极值的数据。与 MAE 一样,MAPE 也低估了由极端值引起的大而罕见的错误的影响。为了解决这个问题,可以使用均方误差。这个指标可以掩盖与低数据量有关的问题;请参阅本文中的最后两个指标来处理这种情况。
均方误差 (MSE)
Mean Squared Error (MSE)
定义: MSE 定义为误差3的平方的平均值。它也被定义为评估预测模型或预测器质量的指标。MSE 还包含方差(预测值彼此之间的传播)和偏差(预测值与其真实值的距离)。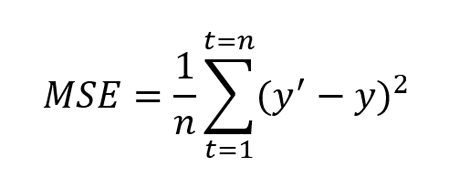
其中y’是预测值,y是真实值。n是测试集中值的总数。MSE 几乎总是正值,并且值越接近零越好。由于平方项(如上面的公式所示),与小错误相比,该指标对大错误或异常值的惩罚更多。
解释与局限: MSE 越接近零越好。虽然它解决了 MAE 和 MAPE 的极值和零问题,但在某些情况下可能是不利的。在处理低数据量时,该指标可能会忽略问题;请参阅加权绝对百分比误差和加权平均绝对百分比误差来处理。
均方根误差 (RMSE)
Root Mean Squared Error (RMSE)
定义:该度量是 MSE 的扩展,定义为均方误差的平方根。
其中y’是预测值,y是真实值。n是测试集中值的总数。与 MSE 一样,该指标也会更多地惩罚较大的错误。
解释和限制:此指标也始终为正值,值越低越好。这种计算的一个优点是 RMSE 值与预测值的单位相同。与 MSE 相比,这使得它更容易理解。
RMSE 还可以与 MAE 进行比较,以确定预测是否包含较大但不常见的错误。RMSE 和 MAE 之间的差异越大,误差大小就越不一致。2该指标可以掩盖与低数据量有关的问题;请参阅本文中的最后两个指标来解决该问题。
归一化均方根误差 (NRMSE)
Normalized Root Mean Squared Error (NRMSE)
定义: NRMSE是RMSE的扩展,通过归一化RMSE计算。有两种标准化 RMSE 的流行方法:使用平均值或使用真实值的范围(最小值和最大值的差异)。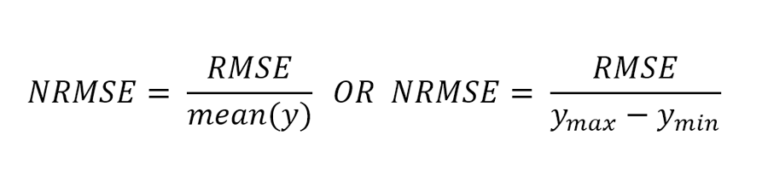
其中y max是最大真值,y min 是最小真值。
解释和限制: NRMSE 通常用于比较具有不同规模(例如单位和总收入)的不同数据集或预测模型。该值越小,模型的性能越好。在处理低数据量时,该指标可能会忽略问题;请参阅加权绝对百分比误差和加权平均绝对百分比误差来解决此问题。
加权绝对百分比误差 (WAPE)
Weighted Absolute Percentage Error (WAPE)
定义: WAPE 定义为平均绝对误差的加权平均值。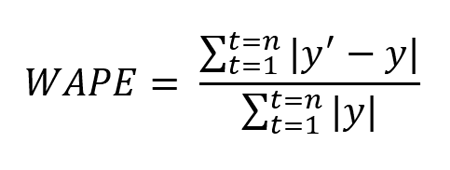
其中y’是预测值,y是真实值。n是测试集中值的总数。
解释和限制:上面提到的误差指标帮助我们衡量预测模型的性能,但在处理少量数据时可能具有欺骗性,例如,当某些数据点的真实值与其余数据相比非常小时(例如,间歇性需求/销售数据)。对于这种情况,可以使用 WAPE。
WAPE 的值越低,模型的性能越好。WAPE 在这里很有用,因为“权重”有助于区分较小的误差和较大的误差。换句话说,该指标可防止将小值视为等于或高于大值。4
加权平均绝对百分比误差 (WMAPE)
定义: WMAPE是WAPE的扩展,定义为加权平均绝对百分比误差。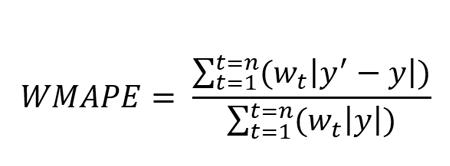
其中y’是预测值,y是真实值。n是测试集中值的总数。
解释与局限: WMAPE 的值越低,模型的性能越好。该指标对于在评估预测模型时每个观察具有不同优先级的低容量数据很有帮助。具有更高优先级的观察具有更高的权重值。高优先级预测值的误差越大,WMAPE 值越大。
误差范围和准确度
当使用上面提到的错误度量时,错误值的实际分布是未知的。但是,这种分布可以进一步了解预测模型的行为并帮助选择最合适的指标。在Jedox AIssisted™ Planning Wizard 中,除了上述度量之外,还会计算误差分布,即测试集每个数据点的度量值。还提供了分布摘要,包括其他相关值,例如最小、最大和中值误差值。
结论
尽管有多个指标,但每个指标都提供可能适合或不适合您的特定用例的特定信息。这意味着应根据用例和对参与预测的数据的理解来选择指标。
以下是本文中讨论的错误指标的概述:
- 当需要测量绝对误差时,MAE 很有用。这很容易理解,但当数据具有极值时效率不高。
- MAPE 也很容易理解,在需要比较不同的预测模型或数据集时使用,因为这是一个百分比值。MAPE 与 MAE 具有相同的缺点,即当数据具有极值时效率不高。
- 当预测值的传播很重要并且需要惩罚较大的值时,MSE 很有用。然而,这个指标通常很难解释,因为它是一个平方值。
- 当传播很重要并且需要惩罚较大的值时,RMSE (NRMSE) 也很有用。与 MSE 相比,RMSE 更容易解释,因为 RMSE 值与预测值的标度相同。
- WAPE 在处理低容量数据时很有用,因为它是通过对总真实值的误差进行加权来计算的。
- WMAPE 在处理低容量数据时也很有用。WMAPE 通过利用每个观察的权重(优先级值)来帮助合并优先级。
Jedox 在AIssisted™ Planning Wizard 中全面概述了预测错误及其分布。
Adjusted R²
https://towardsdatascience.com/which-evaluation-metric-should-you-use-in-machine-learning-regression-problems-20cdaef258e
RMSLELoss
class RMSLELoss(nn.Module):def __init__(self):super().__init__()self.mse = nn.MSELoss()def forward(self, pred, actual):return torch.sqrt(self.mse(torch.log(pred + 1), torch.log(actual + 1)))
Huber Loss
A comparison between L1 and L2 loss yields the following results:
- L1 loss is more robust than its counterpart.
On taking a closer look at the formulas, one can observe that if the difference between the predicted and the actual value is high, L2 loss magnifies the effect when compared to L1. Since L2 succumbs to outliers, L1 loss function is the more robust loss function.
- L1 loss is less stable than L2 loss.
Since L1 loss deals with the difference in distances, a small horizontal change can lead to the regression line jumping a large amount. Such an effect taking place across multiple iterations would lead to a significant change in the slope between iterations.
On the other hand, MSE ensures the regression line moves lightly for a small adjustment in the data point.
Huber Loss combines the robustness of L1 with the stability of L2, essentially the best of L1 and L2 losses. For huge errors, it is linear and for small errors, it is quadratic in nature.
Huber Loss is characterized by the parameter delta (𝛿). For a prediction f(x) of the data point y, with the characterizing parameter 𝛿, Huber Loss is formulated as:
Mean Bias Error (MBE)
平均偏置误差用于计算模型中的平均偏差。简而言之,偏见是高估或低估参数。可以采取纠正措施来减少使用MBE评估模型的偏差。
平均偏置误差是目标和预测值之间的实际差异,而不是绝对差异。必须谨慎,因为积极和负面错误可以相互抵消,这就是为什么它是较少使用的损失函数之一。
Mean Bias Error is used to calculate the average bias in the model. Bias, in a nutshell, is overestimating or underestimating a parameter. Corrective measures can be taken to reduce the bias post-evaluating the model using MBE.
Mean Bias Error takes the actual difference between the target and the predicted value, and not the absolute difference. One has to be cautious as the positive and the negative errors could cancel each other out, which is why it is one of the lesser-used loss functions.
The formula of Mean Bias Error is:![[ML]regression metric - 图9](/uploads/projects/u1067415@lfvwvi/e31c78608f0eeded98815504ec54aa71.png)
Source: Medium
Where yi is the true value, ŷi is the predicted value and ‘n’ is the total number of data points in the dataset.
MeanSquaredLogarithmicError
Los cosh loss
Quantile loss
https://inblog.in/Top-10-activation-and-loss-function-which-you-should-know-about-it-wM27n7JXRg
https://github.com/tuantle/regression-losses-pytorch
参考
1 误差指标
2 绝对误差预测精度
3 均方误差
4 MAPE 与 WAPE (DE)
5.https://github.com/lavinei/pybats/blob/0da0162117eef9e0b52cb67ce79f65878e5ccbf5/pybats/loss_functions.py

若有收获,就点个赞吧
0 人点赞

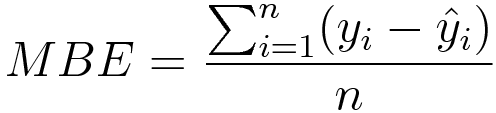{kind=link}