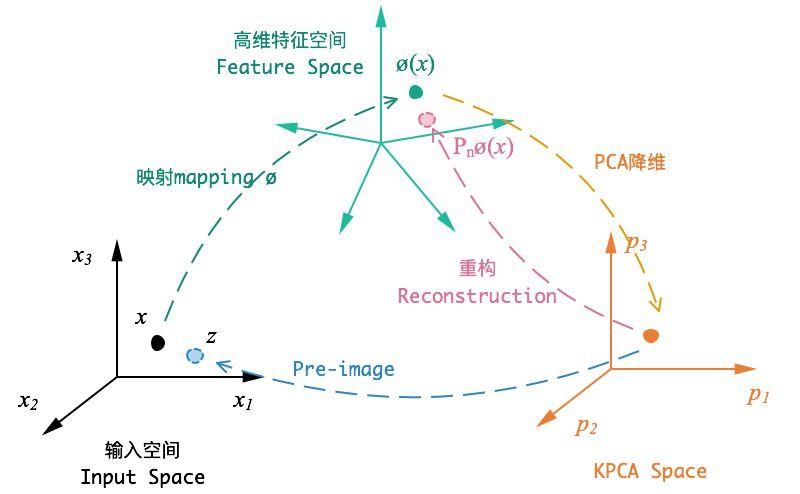
一般来说,主成分分析(Principal Components Analysis, PCA)适用于数据的线性降维。而核主成分分析(Kernel PCA, KPCA)可实现数据的非线性降维,用于处理线性不可分的数据集。
KPCA的大致思路是:对于输入空间(Input space)中的矩阵  ,我们先用一个非线性映射把
,我们先用一个非线性映射把  中的所有样本映射到一个高维甚至是无穷维的空间(称为特征空间,Feature space),(使其线性可分),然后在这个高维空间进行PCA降维。
中的所有样本映射到一个高维甚至是无穷维的空间(称为特征空间,Feature space),(使其线性可分),然后在这个高维空间进行PCA降维。
核主成分分析 (KPCA) 是一种非线性数据处理方法,其核心思想是通过一个非线性映射把原始空间的数据投影到高维特征空间, 然后在高维特征空间中进行基于主成分分析 (PCA) 的数据处理。KPCA通常有以下主要应用:
- 降维
- 特征提取
- 去噪
- 故障检测
KPCA 建模流程
KPCA 的建模流程如下[1]:
- 获取训练数据
- 计算核矩阵
- 核矩阵中心化
- 特征值分解
- 特征向量的标准化处理
- 主成分个数的选取
- 计算非线性主成分
- 计算 SPE 和 T2 统计量 (用于故障检测)
- 计算 SPE 和 T2 统计量的控制限(用于故障检测)
通过步骤1-7可以实现数据降维或者特征提取(即非线性主成分)。另外,基于 KPCA 的数据重构一般是通过求解近似的逆映射,把所获取的非线性主成分重构到原始空间,本文参考以下资料来实现 KPCA 数据重构实现:
- Python 的机器学习库 Scikit-learn (sklearn):sklearn.decomposition.KernelPCA.inverse_transform
通过步骤1-9实现故障检测模型的建立。对于测试数据,在获取 KPCA 模型的基础上,实现故障检测的流程为:
- 获取测试数据
- 计算核矩阵
- 核矩阵中心化
- 计算测试数据的非线性主成分
- 计算 SPE 和 T2 统计量(用于故障检测)
- 与 SPE 和 T2 统计量的控制限进行比较(用于故障检测)
- 若超过控制限,则判断为故障(用于故障检测)
对于步骤7, 通过计算故障区间的 SPE 和 T2 统计量的贡献率来实现故障诊断。本文参考以下资料来实现KPCA故障检测和故障诊断:
- Lee J M, Yoo C K, Choi S W, et al. Nonlinear process monitoring using kernel principal component analysis[J]. Chemical engineering science, 2004, 59(1): 223-234. (故障检测)
- Deng X, Tian X. A new fault isolation method based on unified contribution plots[C]//Proceedings of the 30th Chinese Control Conference. IEEE, 2011: 4280-4285. (故障诊断)
KPCA
编写了 KPCA 的 代码,主要特点有:
- 易于使用的 API
- 基于 KPCA 的数据降维、特征提取、数据重构
- 基于 KPCA 的故障检测和故障诊断
- 核函数 ( gaussian, polynomial,, laplacian){‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘cosine’, ‘precomputed’}
- 基于主元贡献率或给定数字的降维维度/主元个数选取
# https://github.com/heucoder/dimensionality_reduction_alo_codes/blob/master/codes/PCA/KPCA.pyfrom sklearn.datasets import load_irisfrom sklearn.decomposition import KernelPCAimport numpy as npimport matplotlib.pyplot as pltfrom scipy.spatial.distance import pdist, squareform'''author: heucoderemail: 812860165@qq.comdate: 2019.6.13'''def sigmoid(x, coef = 0.25):x = np.dot(x, x.T)return np.tanh(coef*x+1)def linear(x):x = np.dot(x, x.T)return xdef rbf(x, gamma = 15):sq_dists = pdist(x, 'sqeuclidean')mat_sq_dists = squareform(sq_dists)return np.exp(-gamma*mat_sq_dists)def kpca(data, n_dims=2, kernel = rbf):''':param data: (n_samples, n_features):param n_dims: target n_dims:param kernel: kernel functions:return: (n_samples, n_dims)'''# 计算核矩阵K = kernel(data)# 核矩阵中心化N = K.shape[0]one_n = np.ones((N, N)) / NK = K - one_n.dot(K) - K.dot(one_n) + one_n.dot(K).dot(one_n)# 特征值分解eig_values, eig_vector = np.linalg.eig(K)# 主成分个数的选取idx = eig_values.argsort()[::-1]eigval = eig_values[idx][:n_dims]eigvector = eig_vector[:, idx][:, :n_dims]# 特征向量的标准化处理print(eigval)eigval = eigval**(1/2)vi = eigvector/eigval.reshape(-1,n_dims)#计算非线性主成分data_n = np.dot(K, vi)return data_n
结论
在这篇文章中,您大致了解了 KPCA 和非线性降维技术。在实践中,你应该很好地研究你的数据集,以便选择你应该使用什么算法来减少你的维度。另请注意,KPCA 比 PCA 花费更多时间。
https://github.com/JAVI897/Kernel-PCA
https://github.com/heucoder/dimensionality_reduction_alo_codes/blob/master/codes/PCA/KPCA.py
https://zhuanlan.zhihu.com/p/59775730

若有收获,就点个赞吧
0 人点赞
