
flink代码中算子操作主要分为三大部分:source(读取数据源)、transform(对数据做转换操作)、sink(输出)
前提是创建执行环境environment
1. environment
设置执行环境
//批处理val env = ExecutionEnvironment.getExecutionEnvironment//流处理val env = StreamExecutionEnvironment.getExecutionEnvironment
另外,使用Scala API时,应该按照下面的方式引用,否则会出现一些问题(直接引用以下代码)
import org.apache.flink.streaming.api.scala._
2. source
2.1 从集合中/文件中读取数据
package apitest
import org.apache.flink.streaming.api.scala._
//定义样例类,温度传感器
case class SensorReading(id: String, timestamp: Long, temperature: Double)
object SourceTest {
def main(args: Array[String]): Unit = {
// 创建执行环境(流处理)
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 1.从集合中读取数据
val dataList = List(
SensorReading("sensor_1", 1547718199, 35.80018327300259),
SensorReading("sensor_6", 1547718201, 15.402984393403084),
SensorReading("sensor_7", 1547718202, 6.720945201171228),
SensorReading("sensor_10", 1547718205, 38.101067604893444)
)
val stream1 = env.fromCollection(dataList)
stream1.print()
// 从文件中读取数据
val inputPath = "D:\\IDEA\\flink\\src\\main\\resources\\stock\\stock-test.csv"
val stream2 = env.readTextFile(inputPath)
stream2.print()
// 使用流式处理必须有执行这一步
env.execute("source test")
}
}
其中集合中读取数据使用 val stream1 = env.fromCollection(dataList)
文件中读取数据 val stream2 = env.readTextFile(inputPath)
以上数据是有界流(相当于批处理),实际流处理中数据是无界流,那么如何中无界流中处理数据?请看下面
2.2 从kafka中读取数据
当流式处理数据庞大时,需要消息队列进行缓冲,kafka就是很好的选择
本文环境为idea上开发+fink 1.11.2 +Scala 2.11
从maven官网上查看版本对应号,教程:https://blog.csdn.net/mrliqifeng/article/details/112550408
配置
在pom.xml文件中引入kafka连接器
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.11.2</version>
</dependency>
- 其中version为当前flink版本
报错


解决办法
https://blog.csdn.net/pbrlovejava/article/details/103451302
启动zookeeper与kafka
# 启动zookeeper(kafka2.8自带zookeeper,本地开发可以不另外安装zookeeper)
./bin/zookeeper-server-start.sh config/zookeeper.properties
# 后台启动kafka
./bin/kafka-server-start.sh -daemon ./config/server.properties
# 创建topic
./bin/kafka-topics.sh --create --topic topicname --replication-factor 1 --partitions 1 --zookeeper localhost:2181
#启动已经存在topic
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic sensor
#创建消费者
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic sinktest
kafka命令:https://segmentfault.com/a/1190000040316572
实例代码
import java.util.Properties
import org.apache.flink.api.common.restartstrategy.RestartStrategies
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
object SourceTest {
def main(args: Array[String]): Unit = {
// 创建执行环境(流处理)
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从kafka中读取数据
val properties = new Properties()
properties.setProperty("bootstrap.servers","192.168.188.8:9092")
properties.setProperty("group.id","consumer-group")
val stream3 = env.addSource( new FlinkKafkaConsumer[String]("sensor",new SimpleStringSchema(),properties))
stream3.print()
// 使用流式处理必须有执行这一步
env.execute("source test")
}
}
val stream3 = env.addSource( new FlinkKafkaConsumer[String]("sensor",new SimpleStringSchema(),properties)),其中new FlinkKafkaConsumer之所以是new一个消费者实例(Consumer)而不是生产者实例(producer),是因为这里的逻辑是:将kafka中的数据读进来,然后让flink做操作,读kafka中的数据,就是消费者- [String]是泛型
sensor为topic(也就是生产者名称)new SimpleStringSchema()是反序列化器(读进来的是string)properties为配置项
2.3 自定义source
使用自定义source的原因:代码已经开发出来了,但是没有数据,如果想测试代码逻辑是否正确,可以自定义数据
3. transform
3.1 简单转换算子
map
flatmap
filter
3.2 keyBy

DataStream → KeyedStream:逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同 key 的元素(相同的key一定在同一个分区,但同一个分区中不一定只有一种key),在内部以 hash 的形式实现的。
3.3 滚动聚合算子(Rolling Aggregation)
这些算子可以针对 KeyedStream 的每一个支流做聚合。
- sum()
- min()
- max()
- minBy()
- maxBy()
3.4 split 和 select
split

DataStream → SplitStream
根据某些特征把一个 DataStream 拆分成两个或者 多个 DataStream。 并不是真正的切开拆分成了两条流,只是在splitStream里面分成了两组。所以SplitStream不能直接操作需要另一个算子select拿出来处理。
select

SplitStream→DataStream:从一个 SplitStream 中获取一个或者多个 DataStream。
案例
需求:传感器温度数据按照温度高低(以30度为界),拆分为两个流
3.5 connect 和 Comap
connect

DataStream,DataStream → ConnectedStreams
将两条流形式上包了一层,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。
Comap
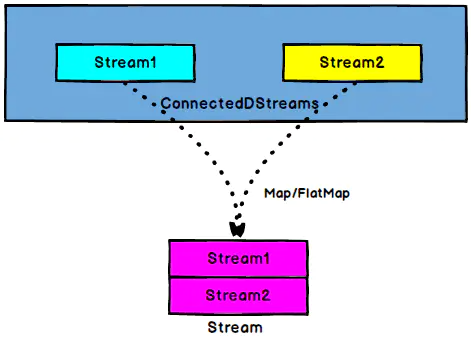
ConnectedStreams → DataStream
作用于ConnectedStreams上,功能与map和flatMap一样,对ConnectedStreams中的每一个Stream分别进行map和flatMap处理。
4. sink
对外输出时一般使用addSink方法
stream.addSink(new MySink(xxxx))
官方自带的连接器:https://ci.apache.org/projects/flink/flink-docs-master/zh/docs/connectors/datastream/overview/
示例代码
object sinkTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 1.读取数据
val inputPath = "D:\\IDEA\\flink\\src\\main\\resources\\stock\\sensor.txt"
val inputStream = env.readTextFile(inputPath)
// 2.先转换为为样例类类型
val dataStream = inputStream
.map( data =>{
val arr = data.split(",")
SensorReading(arr(0),arr(1).toLong,arr(2).toDouble)
})
dataStream.addSink(StreamingFileSink.forRowFormat(
new Path("D:\\IDEA\\flink\\src\\main\\resources\\sink.csv"),
new SimpleStringEncoder[SensorReading]()
).build()
)
env.execute("sink test")
}
}
将数据写入kafka
flink处理完数据后将数据写入kafka中
pom文件中添加flink-kafka连接器
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.13.0</version>
</dependency>
package apitest
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer
import org.omg.CORBA.StringHolder
object kafkaSinkTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 1.读取数据
val inputPath = "D:\\IDEA\\flink\\src\\main\\resources\\stock\\sensor.txt"
val inputStream = env.readTextFile(inputPath)
// 2.先转换为为样例类类型
val dataStream = inputStream
.map(data => {
val arr = data.split(",")
SensorReading(arr(0), arr(1).toLong, arr(2).toDouble).toString
})
dataStream.addSink(
new FlinkKafkaProducer[String](
"192.168.188.8:9092", "sinktest", new SimpleStringSchema()))
env.execute("kafka sink")
}
}
- kafka创建消费者命令:
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic sinktest,保证topic一样

若有收获,就点个赞吧
0 人点赞
