在写温度传感器代码时,一直不是很明白flink中的富函数、RuntimeContext是如何拿到上下文中数据的,所以写下这边文章用来理解数据在flink状态中的传递。
以下代码为第八节中温度传感器温度报警(processing time)示例代码:https://www.yuque.com/u1046159/qstfva/gdq5e7#yH57U
接下来将以下示例代码来讲解flink状态的理解以及数据在flink状态中的传输路线。
//定义样例类,温度传感器case class SensorReading(id: String, timestamp: Long, temperature: Double)object processfunctionTest {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val inputStream = env.socketTextStream("192.168.188.8", 7777)// 先转换为为样例类类型val dataStream = inputStream.map(data => {val arr = data.split(",")SensorReading(arr(0), arr(1).toLong, arr(2).toDouble)})val warningStream = dataStream.keyBy(_.id).process(new TempIncreWaring(10000L))// 输出warningStream.print()env.execute("process function test")}}//实现自定义的keyedprocessfunctionclass TempIncreWaring(interval: Long) extends KeyedProcessFunction[String, SensorReading, String] {// 定义状态,保存上一个温度值进行比较,保存注册定时器的时间戳用于删除// 通过状态名称(句柄)获取状态实例,如果不存在则会自动创建lazy val lastTempState: ValueState[Double] = getRuntimeContext.getState(new ValueStateDescriptor[Double]("last-time", classOf[Double]))lazy val timerTsState: ValueState[Long] = getRuntimeContext.getState(new ValueStateDescriptor[Long]("timer-ts", classOf[Long]))override def processElement(value: SensorReading, ctx: KeyedProcessFunction[String, SensorReading, String]#Context, out: Collector[String]): Unit = {// 先取出状态val lastTemp = lastTempState.value()val timerTs = timerTsState.value()// 更新温度值lastTempState.update(value.temperature)// 对当前温度与上次温度进行比较if (value.temperature > lastTemp && timerTs == 0) {// 如果温度上升且没有定时器,那么注册当前时间10s之后的定时器val ts = ctx.timerService().currentProcessingTime() + intervalctx.timerService().registerProcessingTimeTimer(ts)timerTsState.update(ts)} else if (value.temperature < lastTemp) {// 如果温度下降,那么删除定时器ctx.timerService().deleteProcessingTimeTimer(timerTs)//清空状态timerTsState.clear()}}override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, SensorReading, String]#OnTimerContext, out: Collector[String]): Unit = {//如果状态没有被清空掉,说明温度是持续上升的,直接输出报警信息out.collect("传感器" + ctx.getCurrentKey + "的温度持续上升" + interval / 1000 + "秒连续上升")timerTsState.clear()}}
flink程序与数据流(DataFlow)
首先要理解数据流在flink程序之间是怎样传递的。
在 Flink 中,应用程序由用户自定义算子转换而来的流式 dataflows 所组成。这些流式 dataflows 形成了有向图,以一个或多个源(source)开始,并以一个或多个汇(sink)结束。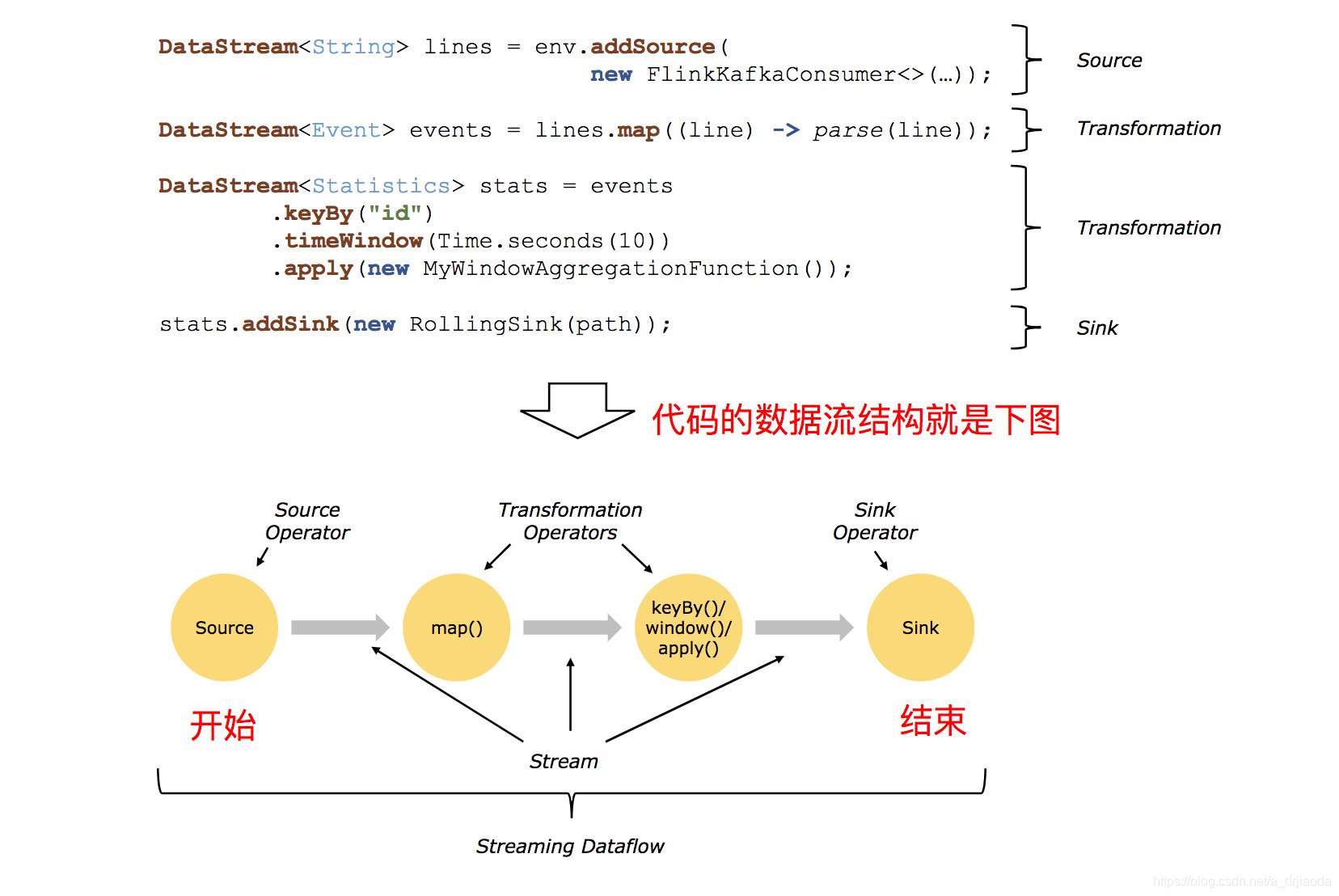
所有的 Flink 程序都是由三部分组成的: Source 、Transformation 和 Sink。 Source 负责读取数据源,Transformation 利用各种算子进行处理加工,Sink 负责输出。
什么是transformation?transformation就是数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据。而map、flatmap……等又称算子
并行 Dataflows
Flink 程序本质上是分布式并行程序。在程序执行期间,一个流有一个或多个流分区(Stream Partition),每个算子有一个或多个算子子任务(Operator Subtask)。每个子任务彼此独立,并在不同的线程中运行,或在不同的计算机或容器中运行。
算子子任务数就是其对应算子的并行度。在同一程序中,不同算子也可能具有不同的并行度。
Flink 算子之间可以通过一对一(直传)模式或重新分发模式传输数据:
- 一对一模式(例如上图中的 Source 和 map() 算子之间)可以保留元素的分区和顺序信息。这意味着 map() 算子的 subtask[1] 输入的数据以及其顺序与 Source 算子的 subtask[1] 输出的数据和顺序完全相同,即同一分区的数据只会进入到下游算子的同一分区。
- 重新分发模式(例如上图中的 map() 和 keyBy/window 之间,以及 keyBy/window 和 Sink 之间)则会更改数据所在的流分区。当你在程序中选择使用不同的 transformation,每个算子子任务也会根据不同的 transformation 将数据发送到不同的目标子任务。例如以下这几种 transformation 和其对应分发数据的模式:keyBy()(通过散列键重新分区)、broadcast()(广播)或 rebalance()(随机重新分发)。在重新分发数据的过程中,元素只有在每对输出和输入子任务之间才能保留其之间的顺序信息(例如,keyBy/window 的 subtask[2] 接收到的 map() 的 subtask[1] 中的元素都是有序的)。因此,上图所示的 keyBy/window 和 Sink 算子之间数据的重新分发时,不同键(key)的聚合结果到达 Sink 的顺序是不确定的。
键控状态(Keyed State)
Keyed State是KeyedStream上的状态。假如输入流按照id为Key进行了keyBy分组,形成一个KeyedStream,数据流中所有id为1的数据共享一个状态,可以访问和更新这个状态,以此类推,每个Key对应一个自己的状态。下图展示了Keyed State,因为一个算子子任务可以处理一到多个Key,算子子任务1处理了两种Key,两种Key分别对应自己的状态。Keyed State必须在stream.keyBy(…)之后使用,否则会报错
代码分析
接下来用示例代码进行分析
输入数据转化为样例类类型
//定义样例类,温度传感器case class SensorReading(id: String, timestamp: Long, temperature: Double)val inputStream = env.socketTextStream("192.168.188.8", 7777)// 将输入数据转换为为样例类类型val dataStream = inputStream.map(data => {val arr = data.split(",")SensorReading(arr(0), arr(1).toLong, arr(2).toDouble)})
map():输入一个DataStream元素对应输出一个DataStream元素。常用作对数据集内数据的清洗和转换。本案例中map(data =>{})对输入数据先使用split进行切分,然后进行数据类型转换,转换为样例类类型输出

keyBy以及ProcessFunction
keyBy算子将数据从 DataStream → KeyedStream:逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同 key 的元素(相同的key一定在同一个分区,但同一个分区中不一定只有一种key),在内部以 hash 的形式实现的。
val warningStream = dataStream.keyBy(_.id)//自定义KeyedProcessFunction方法.process(new TempIncreWaring(10000L))
经过步骤一,已经对数据类型进行了转换,接下来根据数据的id进分组,并且自定义状态方法ProcessFunction,同时传递一个温度差值参数10000L
那process(new TempIncreWaring(10000L))有什么作用呢?要想基于keyby做process算子操作,直接在keyby后面调用process方法,参数为自定义的processfunction(也就是说要想使用processfunction必须在keyby后面调用.process())。这里process参数中定义一个名为TempIncreWaring的方法,用来将处理逻辑交给自定义的TempIncreWaring()方法进行处理。
注意:
- 如果你想访问一个键控状态(keyed state)和定时器,你需要将ProcessFunction应用到一个键控流(keyed stream)中,即在keyby后面使用
.process() - DataStream 与 KeyedStreamd 都有 process 方法,DataStream 接收的是 ProcessFunction,而 KeyedStream 接收的是 KeyedProcessFunction(原本也支持 ProcessFunction,现在已被废弃),建议生产环境中使KeyedProcessFunction 代替 ProcessFunction。
代码中数据流结构
代码中设置并行度为1:env.setParallelism(1)
其中状态的维护是由处理函数TempIncreWaring进行维护的
状态的选择
因为键控状态(Keyed State)是常用的状态,本文代码以及介绍中都使用键控状态进行讲解。
对于Keyed State,Flink提供了几种现成的数据结构供我们使用,包括ValueState、ListState等,他们的继承关系如下图所示。首先,State主要有三种实现,分别为ValueState、MapState和AppendingState,AppendingState又可以细分为ListState、ReducingState和AggregatingState。
注意:以上所述的State对象,仅仅用于与状态进行交互(更新、删除、清空等),而真正的状态值,有可能是存在内存、磁盘、或者其他分布式存储系统中。相当于我们只是持有了这个状态的句柄(statehandle)。状态句柄并不存储状态,它只是Flink提供的一种访问状态的接口,状态数据实际存储在State Backend中。
那如何得到这个状态句柄呢?请看下一节。
状态的定义
Flink通过StateDescriptor来定义一个状态。这是一个抽象类,内部定义了状态名称、类型、序列化器等基础信息。与上面的状态对应,从StateDescriptor派生了ValueStateDescriptor, ListStateDescriptor等descriptor。具体方式如下:
ValueState getState(ValueStateDescriptor)ReducingState getReducingState(ReducingStateDescriptor)ListState getListState(ListStateDescriptor)FoldingState getFoldingState(FoldingStateDescriptor)MapState getMapState(MapStateDescriptor)

代码中使用new ValueStateDescriptor[Double]("last-time", _classOf_[Double]来定义状态
注意:状态在使用前需要初始化,有两种初始化方法,一种使用lazy关键字进行修饰,实现惰性加载,另一种在open方法中定义状态
至此,flink中状态已经定义,接下来就可以就可以对状态进行操作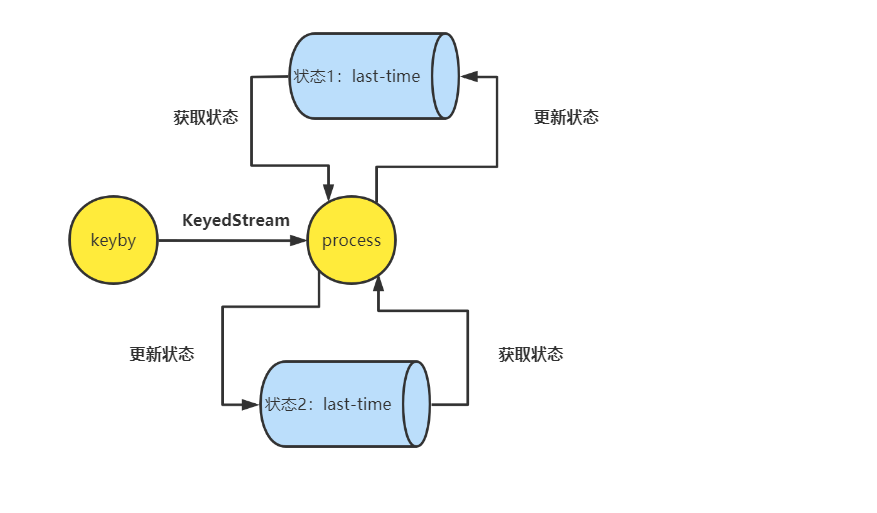
状态的获取
通过状态句柄获取状态示实例,必须使用RichFunction(因为状态需要从RuntimeContext中创建和获取),普通的Function是无状态的。本示例代码:getRuntimeContext.getState用于获取状态句柄(getRuntimeContext方法是获取运行时上下文,getState方法是从上下文中获取状态),并将获取后的状态赋值给变量lastTempState与 timerTsState
状态的使用与更新
使用和更新状态发生在实际的处理函数上,比如RichFlatMapFunction中的flatMap方法(本案例中是KeyedProcessFunction的process方法),在实现自己的业务逻辑时访问和修改状态,比如通过get方法(ValueState的数据结构通过.value()获取状态)获取状态,使用update方法更新状态。
//获取状态val lastTemp = lastTempState.value()//更新状态timerTsState.update(ts)
数据流在flink状态中的传递


- 数据流经过keyby后形成keyedStream数据流,传入process算子中(此时process中已经能接收到数据)
- 在process算子上使用StateDescriptor定义状态(一个算子可以拥有一个或者多个状态),并进行初始化
- 从RuntimeContext中使用getRuntimeContext.getState方法获取状态句柄(状态句柄对象是在RichFunction的open()方法中创建,即使使用lazy修饰,本质也是在调用时调用open方法。open()在调用任何处理方法(如flatMap函数中的flatMap())之前被调用。状态句柄对象是函数类的常规成员变量。状态句柄对象仅提供对状态的访问,该状态存储在状态后端维护中。句柄不包含状态本身。),使用状态句柄获取和更新状态数据,比如ValueState.value、ValueState.update、MapState.get、MapState.put
- 每一个数据进入process算子,都会执行processElement处理它,processElement传入的参数为SensorReading,
val lastTemp = _lastTempState_.value()获取当前状态的值,首次获取,值为空 - onTimer方法,用于响应TimerService触发的timer
总结
综上,Keyed State的使用方法可以被归纳为:
- 创建一个StateDescriptor,在里面注册状态的名字和数据类型等。
- 从RuntimeContext中获取状态句柄。
- 使用状态句柄获取和更新状态数据,比如ValueState.value、ValueState.update、MapState.get、MapState.put。
此外,必要时候,我们还需要调用Keyed State中的void clear()方法来清除状态中的数据,以免发生内存问题。

若有收获,就点个赞吧
0 人点赞
