1、集群模式
1.1 虚拟机准备
- 再准备三台虚拟机
- 可以通过命令脚本分发hadoop的安装文件,避免每台虚拟机都要重新配置,可以使用脚本来循环完成
- rsync相比常规的scp命令,只会去拷贝不相同的文件,跳过相同文件,这样就能加快拷贝速度
rsync -rvl /opt/hadoop-3.1.3/ root@hadoop102:/opt/hadoop-3.1.3rsync -rvl /opt/hadoop-3.1.3/ root@hadoop103:/opt/hadoop-3.1.3rsync -rvl /opt/hadoop-3.1.3/ root@hadoop104:/opt/hadoop-3.1.3rsync -rvl /opt/hadoop-3.1.3/ root@hadoop105:/opt/hadoop-3.1.3
1.2 集群规划
- NN(NameNode)是目录,DN(DataNode)是实际的文件存放地,所以规划集群时候,尽可能分开放入不同的服务器
- SNN(SecondaryNameNode)是目录的二级缓存,起到对NN的维护作用,二者的内存占用是一致的,所以SNN和NN也不要放在同一台服务器上
- 如果条件允许,我们最好可以分配单独的服务器来专门做计算用,这部分服务器不用来存放数据,以保证MR(MapReduce)性能最高
- 对于YARN来说,RM(ResourceManager)是所有资源请求的入口,要为他分配最大的内存,因此我们将这个节点放在DN上,避免和NN、SNN竞争内存
- NM(NodeManager)是单节点的管理器,所以每个服务器都要有
| hadoop101 | hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|---|
| HDFS | NN 日志服务器 |
Hive、Spark等 DN |
SNN |
DN |
| YARN | NM | NM | NM | RM+NM |
1.3 集群配置
1.3.1 HDFS配置
修改core-site.xml,将主机名改为规划的NN主机
<!-- 指定HDFS中NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop101:9000</value></property>
配置hadoop-env.sh(配置后分发至每台主机即可,已配完可略过)
export JAVA_HOME=/opt/module/jdk1.8.0_144配置hdfs-site.xml
<!-- 指定HDFS副本的数量,比如现在有4个 --> <property> <name>dfs.replication</name> <value>4</value> </property> <!-- 指定Hadoop辅助名称节点SNN主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop103:50090</value> </property>
1.3.2 YARN配置
配置yarn-env.sh(hadoop3版本可省略)
export JAVA_HOME=/opt/jdk1.8.0_241配置yarn-site.xml
<!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop104</value> </property> <!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
1.3.3 MapReduce配置
配置mapred-env.sh,(hadoop3版本可省略)
export JAVA_HOME=/opt/jdk1.8.0_241配置mapred-site.xml
<!-- 指定MR运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 指定MR运行日志服务器 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop101:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop101:19888</value> </property>
1.3.4 分发配置文件
scp可在主机未安装情况下,整个软件进行复制
scp -r /opt/hadoop/ root@hadoop102:/opt/hadoop/ scp -r /opt/hadoop/ root@hadoop103:/opt/hadoop/ scp -r /opt/hadoop/ root@hadoop104:/opt/hadoop/rsync是在主机上已经安装了hadoop,只需要同步配置文件时使用
rsync -rvl /opt/hadoop/etc/hadoop/ root@hadoop102:/opt/hadoop/etc/hadoop/ rsync -rvl /opt/hadoop/etc/hadoop/ root@hadoop103:/opt/hadoop/etc/hadoop/ rsync -rvl /opt/hadoop/etc/hadoop/ root@hadoop104:/opt/hadoop/etc/hadoop/常规做法要输入四次命令很麻烦,更好的做法是使用脚本来循环调用,在/home目录下创建bin目录,并在bin目录下创建xsync文件,这个文件名就是日后脚本调用的方法名
cd /home mkdir bin touch xsync vim xsync脚本内容如下 ```shell
!/bin/bash
1 获取输入参数个数,如果没有参数,直接退出
pcount=$# if((pcount==0)); then echo no args; exit; fi
2 获取文件名称
p1=$1
fname=basename $p1
echo fname=$fname
3 获取上级目录到绝对路径 –P指向实际物理地址,防止软连接
pdir=cd -P $(dirname $p1); pwd
echo pdir=$pdir
4 获取当前用户名称
user=whoami
5 循环,我们初始主机101,需要分发至三台上
for((host=101; host<=104; host++)); do echo —————————- hadoop$host ——————— rsync -rvl $pdir/$fname $user@hadoop$host:$pdir done
- 赋予脚本权限
```shell
chmod 777 xsync
1.4 集群启动
第一次启动时一定格式化,否则集群启动时候,hadoop101用jps命令会看不到NN进程
hdfs namenode -format根据规划,可以根据职责在不同服务器上启动不同节点,但这样做特别慢,所以最好做群启节点
1.4.1 ssh免密码登录
- 可以在主机上保存ssh秘钥文件,这样就能让服务器之间互相实现免密码登录
- 首先生成公钥和私钥,然后拷贝至其他主机,建议可以所有主机都操作一遍,完成互联互通
ssh-keygen -t rsa ssh-copy-id hadoop101 ssh-copy-id hadoop102 ssh-copy-id hadoop103 ssh-copy-id hadoop104
1.4.2 配置集群关系
- 根据hadoop官方文档,我们可以在./etc/hadoop/workers这个文件中配置所有参与集群的服务器主机名,然后就能借助内置的集群脚本来群启节点,前提是参与集群的服务器之间是可以免密码ssh登录的。workers文件并未初始存在,所以我们需要新建一个,然后追加 ```shell cd /opt/hadoop-3.1.3/etc/hadoop/ touch workers vim workers
追加所有主机名
hadoop101 hadoop102 hadoop103 hadoop104
- 然后继续分发脚本(建议使用脚本代替)。
<a name="YxSul"></a>
#### 1.4.3 群启集群节点
- 配置好集群节点文件后,是可以单个节点去启动的,但这样做太麻烦,而且得自己维护哪台服务器启动什么组件,所以hadoop提供了群启工具,进入hadoop安装目录下:
```shell
# 启动HDFS集群
sbin/start-dfs.sh
- 如果出现下面的错误,就是因为我们安装hadoop时候用的是root帐号,但脚本启动文件的用户权限却不是root导致的(建议不要用root用户安装)
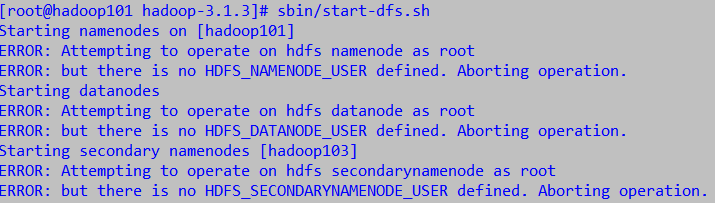
修改sbin目录下的start-dfs.sh,stop-dfs.sh脚本文件,在顶部追加
#!/usr/bin/env bash HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=rootstart-yarn.sh,stop-yarn.sh顶部也需添加
#!/usr/bin/env bash YARN_RESOURCEMANAGER_USER=root HDFS_DATANODE_SECURE_USER=yarn YARN_NODEMANAGER_USER=root再次分发配置文件
rsync -rvl /opt/hadoop/sbin/ root@hadoop102:/opt/hadoop/sbin/ rsync -rvl /opt/hadoop/sbin/ root@hadoop103:/opt/hadoop/sbin/ rsync -rvl /opt/hadoop/sbin/ root@hadoop104:/opt/hadoop/sbin/启动成功
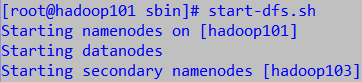
- NN会分配给输入命令的当前主机,这个暂时无法指定,所以应在规划的NN服务器上输入启动命令
YARN是需要单独启动的,并且会默认把运行启动命令的主机分配为ResourceManger,所以,记得去对应的主机上输入命令。
#启动YARN [root@hadoop104 hadoop-3.1.3]# sbin/start-yarn.sh Starting resourcemanager Starting nodemanagers [root@hadoop104 hadoop-3.1.3]# jps 2285 DataNode 2717 NodeManager 2543 ResourceManager 3071 Jps现在通过jps命令查看每台主机的组件运行情况
[root@hadoop101 sbin]# jps 3760 DataNode 4289 Jps 4148 NodeManager 3561 NameNode[root@hadoop102 ~]# jps 2312 NodeManager 2457 Jps 2091 DataNode[root@hadoop103 ~]# jps 2418 SecondaryNameNode 2740 Jps 2295 DataNode 2585 NodeManager[root@hadoop104 ~]# jps 2285 DataNode 2717 NodeManager 3117 Jps 2543 ResourceManager服务器节点的运行符合预期规划,至此集群搭建成功。通过连接http://hadoop101:9870可以直接访问web页面。
1.4.4 历史服务器启动
sbin/mr-jobhistory-daemon.sh start historyserver
1.4.5 群启群停脚本编写
- hadoop自带脚本无法满足规划需求时,可以自己编写脚本
echo "开始启动HDFS" /opt/hadoop/sbin/start-dfs.sh echo "启动日志服务器" mapred --daemon start historyserver echo "开始启动YARN" ssh root@hadoop104 "/opt/hadoop/sbin/start-yarn.sh" echo "启动完毕"echo "开始关闭HDFS" /opt/hadoop/sbin/stop-dfs.sh echo "开始关闭YARN" ssh root@hadoop104 "/opt/hadoop/sbin/stop-yarn.sh" echo "停止日志服务器" mapred --daemon stop historyserver echo "关闭成功"

若有收获,就点个赞吧
0 人点赞
