1、数据仓库的概念
Hive是一个基于HDFS来存储数据的仓库,与传统数据库相比,完全注重于读操作,存放在数据仓库的数据基本是不会发生改变的。hive通过HDFS存储数据,而非传统的数据库引擎,因此,对于hive来说,数据表都是一个个的文件,然后存放在HDFS上而已。
1.1 三个特点
- Hive处理的数据存储在HDFS,本身不会存数据
- Hive分析数据底层的实现是MapReduce,本身也无法做计算
- 执行程序运行在Yarn上
1.2 本质
- hive本质是将HDFS中的数据以数据表的形式进行存储,方便使用者更方便的对这些数据进行操作,并且hive本身支持HQL语言(SQL方言),学习成本也是很低打的。
- hive底层通过MapReduce进行数据的具体操作,hive只是将sql翻译成MapReduce语句,相当于MapReduce的翻译器
1.3 优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
- 避免了去写MapReduce,减少开发人员的学习成本。
- Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
1.2.2 缺点
- Hive的HQL表达能力有限:
- 迭代式算法无法表达,比如循环。
- 数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现。
- Hive的效率比较低
- Hive自动生成的MapReduce作业,通常情况下不够智能化
- Hive调优比较困难,粒度较粗
- 所以现在通常会在底层使用hive做仓库,顶层使用spark做计算
2、hive的架构
2.1 用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
2.2 元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
2.3 存储系统:Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
2.4 驱动器:Driver
- 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
- 编译器(Physical Plan):将AST编译生成逻辑执行计划。
- 优化器(Query Optimizer):对逻辑执行计划进行优化。
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
3、安装与启动
3.1安装
以最新的3.1.2版本为例,可从阿里镜像源下载hive的安装包:hive镜像
解压缩
#解压tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /root/apps#改名mv apache-hive-3.1.2-bin hive-3.1.2
配置hive-env.sh文件,/hive/conf目录下的hive-env.sh.template名称为hive-env.sh
export HADOOP_HOME=/opt/hadoop-3.1.3export HIVE_CONF_DIR=/opt/hive-3.1.2/confexport HIVE_AUX_JARS_PATH=/opt/hive-3.1.2/lib
配置环境变量(Linux环境变量在/etc/profile中配置)
vim /etc/profileexport HIVE_HOME=/opt/hive-3.1.2export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/binsource /etc/profile# 通过echo $HIVE_HOME验证是否成功
下载mysql-connector-java的jar包:下载地址,hive必须依赖于MySQL的运行,因此也要提前安装MySQL数据库。将解压后的jar包放进/opt**/hive-3.1.2/lib**下
yum install mysqlmv mysql-connector-java-5.1.47.jar /opt/hive-3.1.2/lib/
创建hive-site.xml
touch /opt/hive-3.1.2/conf/hive-site.xml
复制粘贴以下配置内容
<?xml version="1.0" encoding="UTF-8" standalone="no"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 配置mysql连接,可以配置成远程数据库,也可以是本机数据库 --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value></property><!-- 配置jdbc驱动 --><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- 配置mysql用户名 --><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- 配置mysql密码 --><property><name>javax.jdo.option.ConnectionPassword</name><value>1234</value></property><property><name>datanucleus.readOnlyDatastore</name><value>false</value></property><property><name>datanucleus.fixedDatastore</name><value>false</value></property><property><name>datanucleus.autoCreateSchema</name><value>true</value></property><property><name>datanucleus.schema.autoCreateAll</name><value>true</value></property><property><name>datanucleus.autoCreateTables</name><value>true</value></property><property><name>datanucleus.autoCreateColumns</name><value>true</value></property><property><name>hive.metastore.local</name><value>true</value></property><!-- 显示表的列名 --><property><name>hive.cli.print.header</name><value>true</value></property><!-- 显示数据库名称 --><property><name>hive.cli.print.current.db</name><value>true</value></property></configuration>
3.2 启动
首先启动hadoop
然后在hive目录下启动hive
bin/hive如果出现错误
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357) at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338) at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:518) at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:536) at org.apache.hadoop.mapred.JobConf.<init>(JobConf.java:430) at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5141) at org.apache.hadoop.hive.conf.HiveConf.<init>(HiveConf.java:5099) at org.apache.hadoop.hive.common.LogUtils.initHiveLog4jCommon(LogUtils.java:97) at org.apache.hadoop.hive.common.LogUtils.initHiveLog4j(LogUtils.java:81) at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:699) at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:318) at org.apache.hadoop.util.RunJar.main(RunJar.java:232)关键在: com.google.common.base.Preconditions.checkArgument 这是因为hive内依赖的guava.jar和hadoop内的版本不一致造成的。 检验方法:
- 查看hadoop安装目录下/opt/hadoop/share/hadoop/common/lib内guava.jar版本
- 查看hive安装目录下lib内guava.jar的版本 如果两者不一致,删除版本低的,并拷贝高版本的 问题解决!
- 理论上hadoop生态内的组件都可能遇到jar包冲突,选择最高版本进行拷贝即可
启动成功
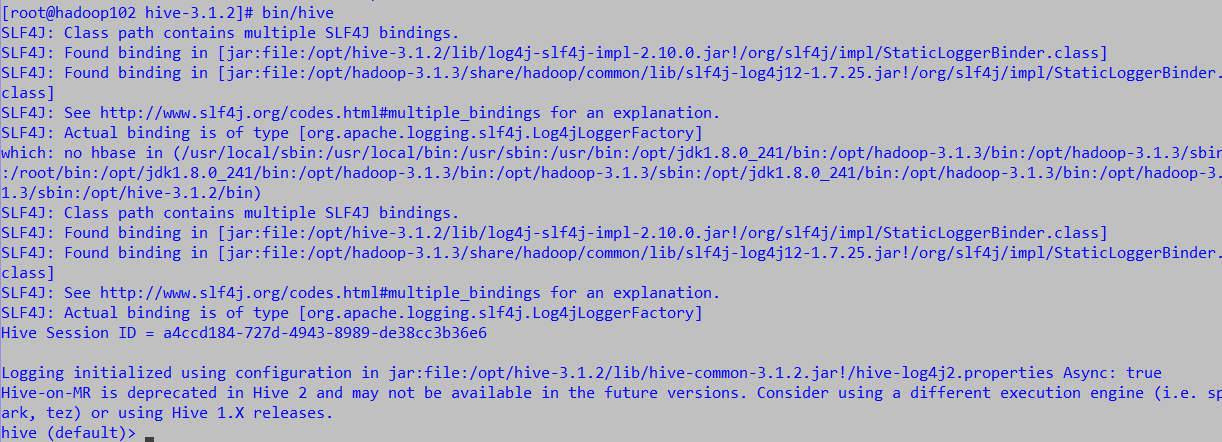
4、JDBC交互
4.1 使用MySQL保存元数据
- 之前下载的mysql-jar包是为了让Hive可以连接上MySQL数据库,从而将元数据等关键信息存入MySQL
- 可以打开多个shell窗口,分别启动hive,如果在MySQL中看到配置的数据库(我用的是”hive”),那么就成功了:
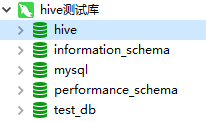
4.2 jdbc操作
首先,要通过多客户机启动命令来启动hive,这样才能支持jdbc并发操作
[root@hadoop102 hive-3.1.2]# bin/hiveserver2 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/hive-3.1.2/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/jdk1.8.0_241/bin:/opt/hadoop-3.1.3/bin:/opt/hadoop-3.1.3/sbin:/root/bin:/opt/jdk1.8.0_241/bin:/opt/hadoop-3.1.3/bin:/opt/hadoop-3.1.3/sbin:/opt/jdk1.8.0_241/bin:/opt/hadoop-3.1.3/bin:/opt/hadoop-3.1.3/sbin:/opt/hive-3.1.2/bin) 2020-04-14 17:36:40: Starting HiveServer2 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/hive-3.1.2/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Hive Session ID = f31033cf-ff2d-4b58-876a-37f577470343在另一台客户机启动命令行
bin/beeline

若有收获,就点个赞吧
0 人点赞
