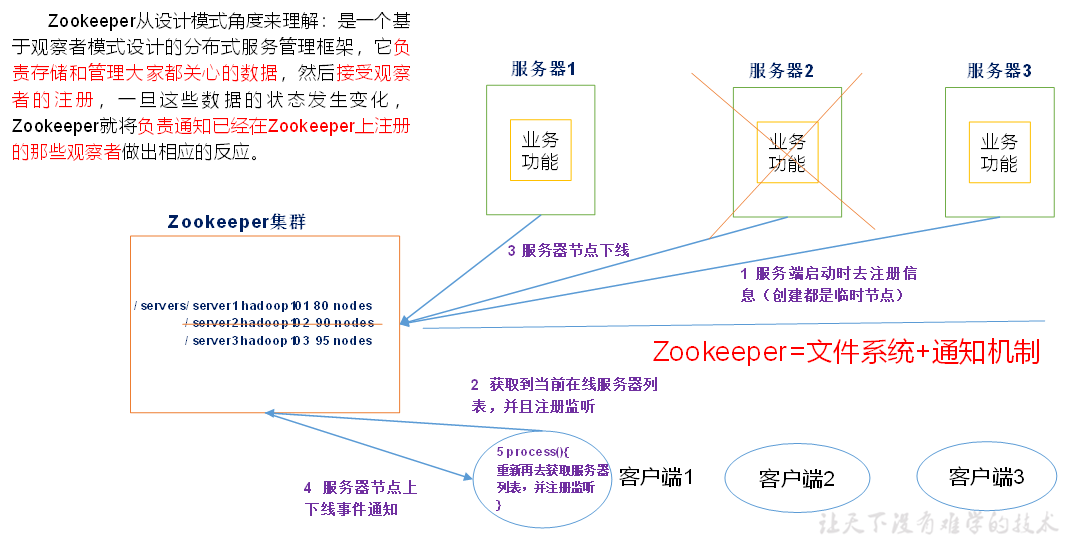
1、基础介绍
1.1 工作机制
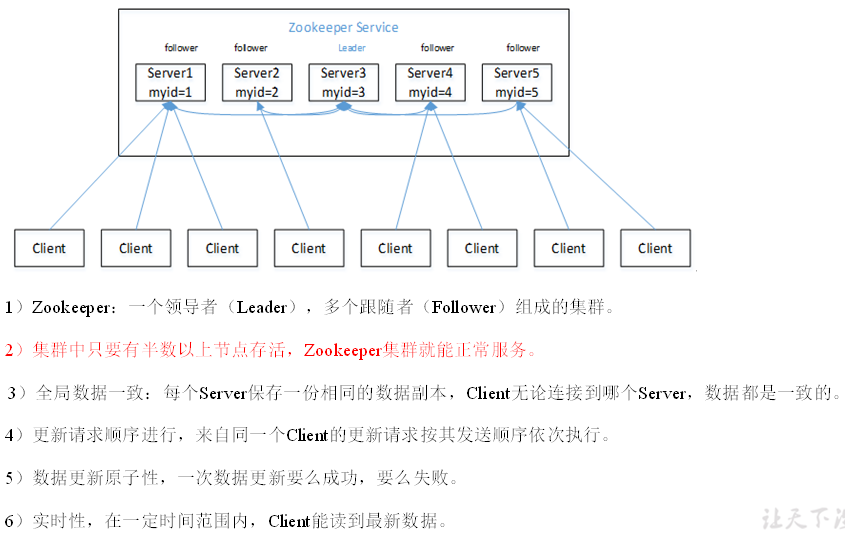
1.2 特点
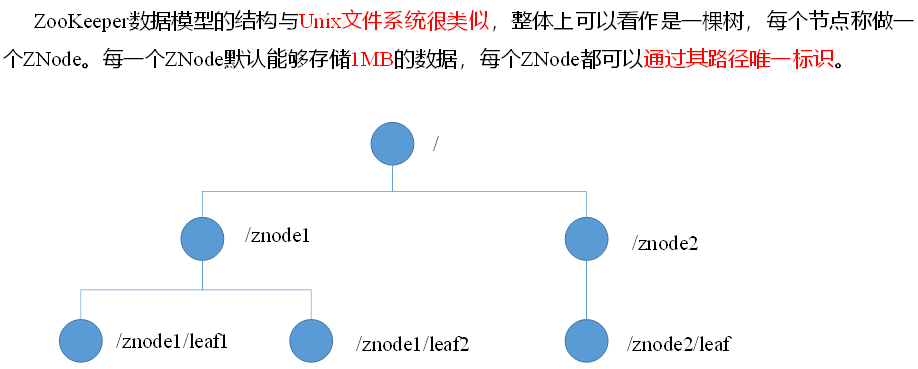
1.3 数据结构
1.4 应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
**
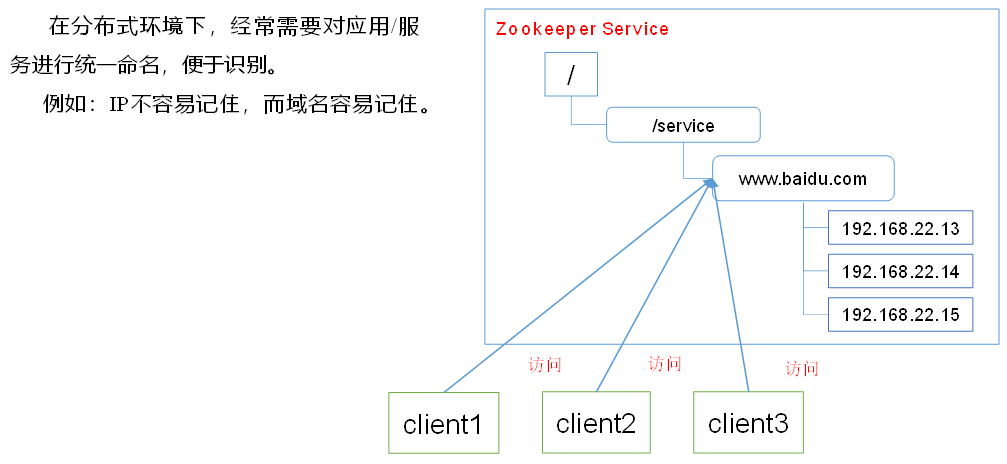
1.4.1 统一命名
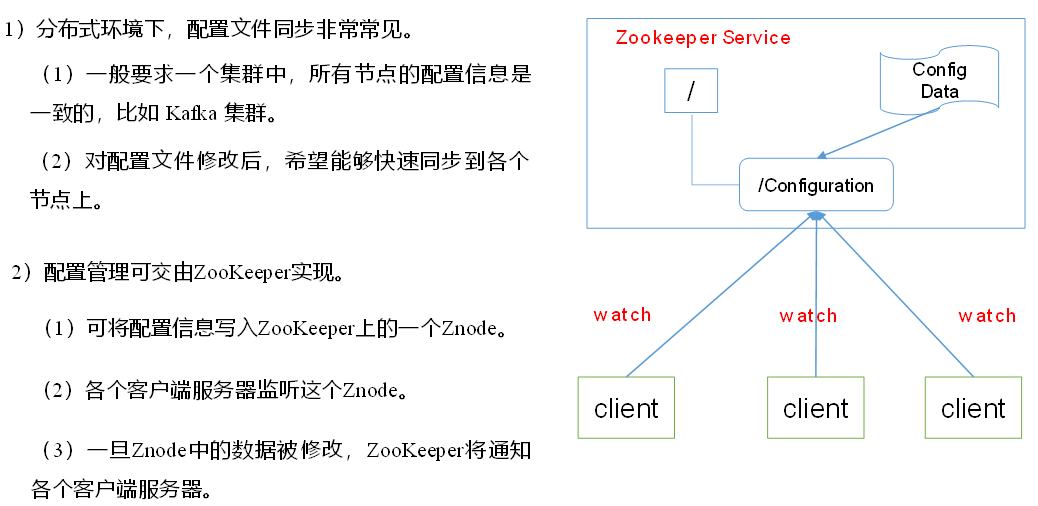
1.4.2 统一配置管理
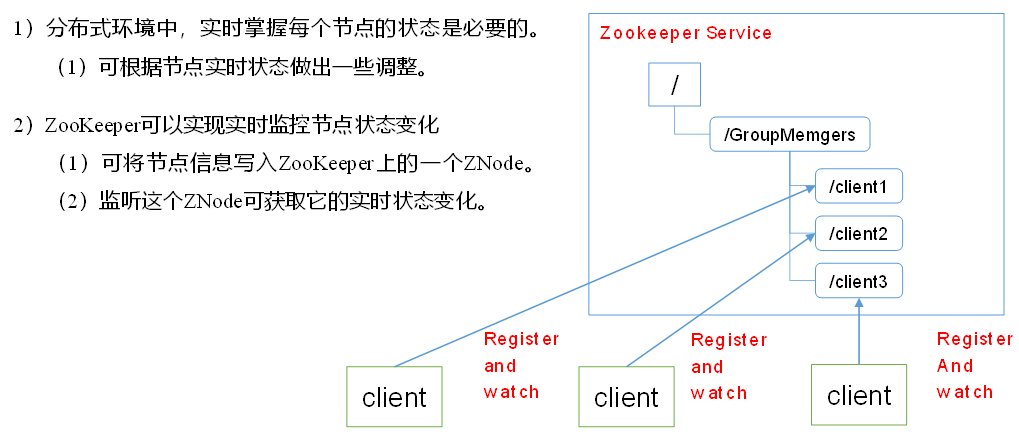
1.4.3 统一集群管理
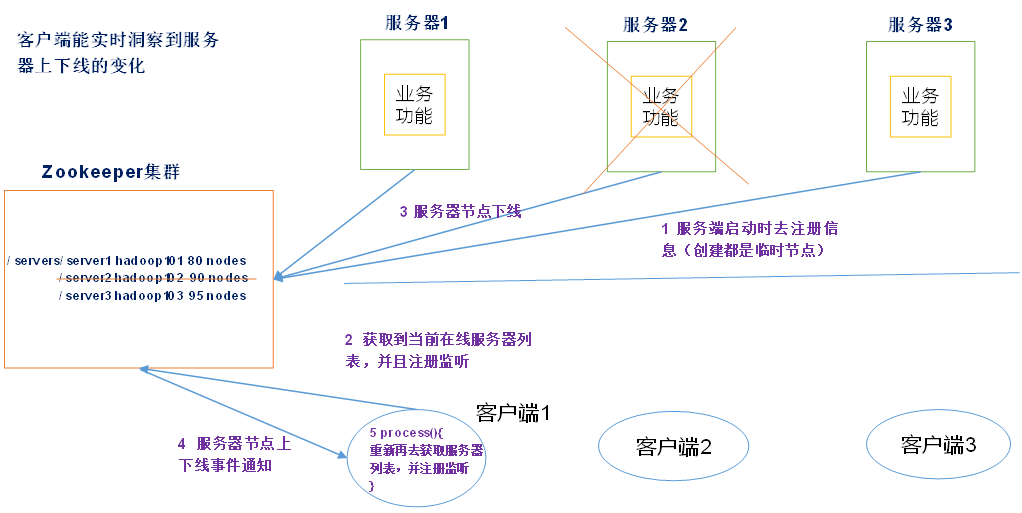
1.4.4 服务动态上下线
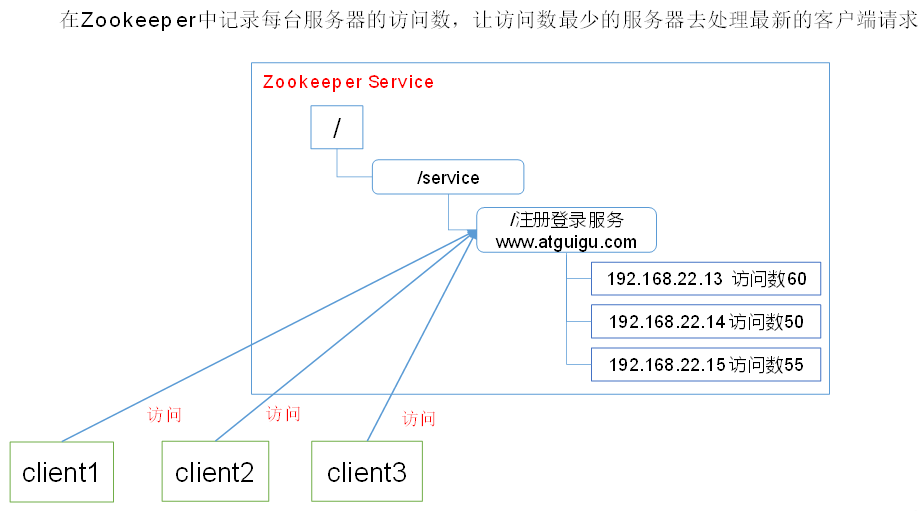
1.4.5 服务动态上下线
2、安装使用
- 官网地址:链接,下载后直接解压即可。
- 在安装目录下创建文件夹/zkData,用来存放运行时的数据。
- 在文件夹/zkData中创建myid文件,编辑数字,代表当前主机的服务序号
配置zoo.cfg文件
# 通信心跳数,Zookeeper服务器与客户端心跳时间,单位毫秒# 它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间tickTime=2000# LF初始通信时限# 集群中的Follower跟随者服务器与Leader领导者服务器之间初始连接时能容忍的最多心跳数(tickTime的数量)# 用它来限定集群中的Zookeeper服务器连接到Leader的时限initLimit=10# LF同步通信时限# 集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit * tickTime# Leader认为Follwer死掉,从服务器列表中删除FollwersyncLimit=5# 数据文件夹路径dataDir=/opt/zookeeper/zkData# 客户端端口号,API也通过该端口调用clientPort=2181# server.A=B:C:D# A表示这个是第几号服务器,B是这个服务器的地址# C是这个服务器Follower与集群中的Leader服务器交换信息的端口# D是用来执行选举时服务器相互通信的端口server.1=hadoop101:2888:3888server.2=hadoop102:2888:3888server.3=hadoop103:2888:3888server.4=hadoop104:2888:3888
rsync命令分发文件,然后修改每台主机的myid,为1~4,然后在每台主机上启动Zookeeper
bin/zkServer.sh start
2.1 群启群停脚本
可以编写群启、群停脚本,注意必须source配置文件,否则Zookeeper会报找不到JAVA_HOME
echo "开始启动Zookeeper" /opt/zookeeper/bin/zkServer.sh start ssh root@hadoop102 "source /etc/profile;/opt/zookeeper/bin/zkServer.sh start" ssh root@hadoop103 "source /etc/profile;/opt/zookeeper/bin/zkServer.sh start" ssh root@hadoop104 "source /etc/profile;/opt/zookeeper/bin/zkServer.sh start" echo "启动完毕"echo "开始关闭Zookeeper" /opt/zookeeper/bin/zkServer.sh stop ssh root@hadoop102 "source /etc/profile;/opt/zookeeper/bin/zkServer.sh stop" ssh root@hadoop103 "source /etc/profile;/opt/zookeeper/bin/zkServer.sh stop" ssh root@hadoop104 "source /etc/profile;/opt/zookeeper/bin/zkServer.sh stop" echo "执行完毕"通过命令进入界面,然后在一台主机上插入节点和数据,在另一台主机上获取数据,成功获取则搭建成功
bin/zkCli.sh create /node1 "test1" get /node1
3、应用开发
Apache官方提供了开发jar包,实际使用更推荐另一个封装后的框架curator
implementation("org.apache.curator:curator-recipes:4.3.0")然后就可通过代码的方式操作Zookeeper节点
@Test fun contextLoads() { val retryPolicy: RetryPolicy = ExponentialBackoffRetry(2000, 3) // 连接列表,主机名:端口号(就是配置文件中的client端口号),逗号分隔 val connectString = "hadoop101:2181,hadoop102:2181,hadoop103:2181,hadoop104:2181" val client = CuratorFrameworkFactory.builder().connectString(connectString) // 通常设置为心跳时间的二倍以上 .sessionTimeoutMs(4000) // 会话超时时间 .connectionTimeoutMs(4000) // 连接超时时间 .retryPolicy(retryPolicy) .build() // 启动客户端,项目挂掉则客户端失联,这时就说明节点下线,或者故障。 client.start() client.create().withMode(CreateMode.EPHEMERAL_SEQUENTIAL) .forPath("/node2", "test2".toByteArray()) println("节点数据:${String(client.data.forPath("/node2"))}") }

若有收获,就点个赞吧
0 人点赞
