1、基础概念
Hbase是以hadoop的HDFS系统为基础构建的数据库,也就是用HDFS系统充当存储引擎、MapReduce充当查询引擎的数据库,他用于支持结构化的数据存储,而不仅限于非结构化数据。
1.1 HBase 特点
1.1.1 海量存储
Hbase 适合存储 PB 级别的海量数据,在 PB 级别的数据以及采用廉价 PC 存储的情况下,能在几十到百毫秒内返回数据。这与 Hbase 的极易扩展性息息相关。正式因为 Hbase 良好的扩展性,才为海量数据的存储提供了便利。
1.1.2 **列式存储
** 这里的列式存储其实说的是列族存储,Hbase 是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
1.1.3 **极易扩展
**
- Hbase 的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
- 通过横向添加 RegionSever 的机器,进行水平扩展,提升 Hbase 上层的处理能力,提升Hbsae服务更多 Region 的能力。
- RegionServer 的作用是管理 region、承接业务的访问,这个后面会详细的介绍通过横向添加 Datanode 的机器,进行存储层扩容,提升 Hbase 的数据存储能力和提升后端存储的读写能力。
1.1.4 **高并发
**
由于目前大部分使用 Hbase 的架构,都是采用的廉价 PC,因此单个 IO 的延迟其实并不
小,一般在几十到上百 ms 之间。这里说的高并发,主要是在并发的情况下,Hbase 的单个
IO 延迟下降并不多。能获得高并发、低延迟的服务。
1.1.5 **稀疏
**
稀疏主要是针对 Hbase 列的灵活性,在列族中,你可以指定任意多的列,在列数据为空
的情况下,是不会占用存储空间的。
1.2 结构分析
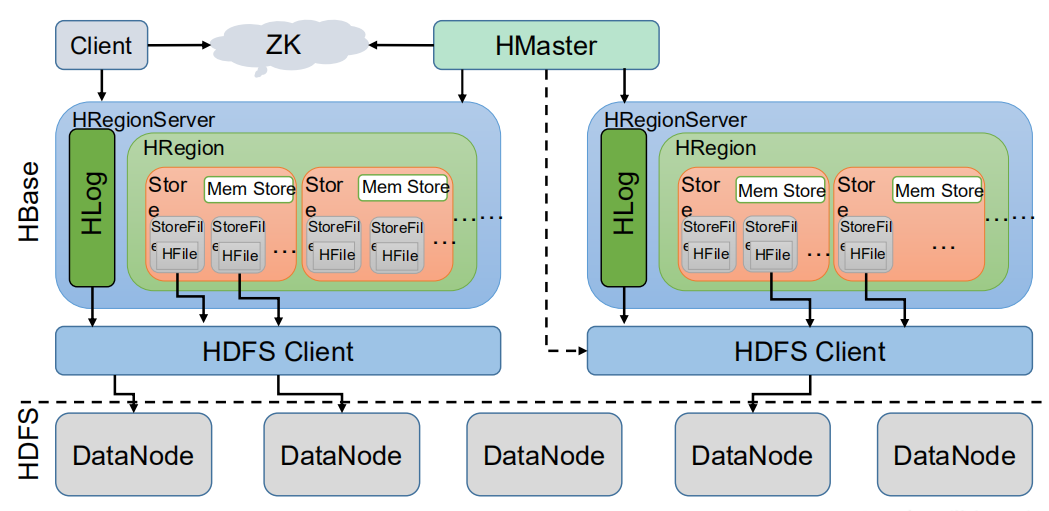
1.2.1 Client
Client 包含了访问 Hbase 的接口,另外 Client 还维护了对应的 cache 来加速 Hbase 的访问,比如 cache 的.META.元数据的信息。
1.2.2 Zookeeper
HBase 通过 Zookeeper 来做 master 的高可用、RegionServer 的监控、元数据的入口以及集群配置的维护等工作。具体工作如下:
- 通过 Zoopkeeper 来保证集群中只有 1 个 master 在运行,如果 master 异常,会通过竞争机制产生新的 master 提供服务
- 通过 Zoopkeeper 来监控 RegionServer 的状态,当 RegionSevrer 有异常的时候,通过回调的形式通知 Master RegionServer 上下线的信息
- 通过 Zoopkeeper 存储元数据的统一入口地址
1.2.3 Hmaster
master 节点的主要职责如下:
- 为 RegionServer 分配 Region
- 维护整个集群的负载均衡
- 维护集群的元数据信息
- 发现失效的 Region,并将失效的 Region 分配到正常的 RegionServer 上
- 当 RegionSever 失效的时候,协调对应 Hlog 的拆分
1.2.4 HregionServer
HregionServer 直接对接用户的读写请求,是真正的“干活”的节点。它的功能概括如下:
- 管理 master 为其分配的 Region
- 处理来自客户端的读写请求
- 负责和底层 HDFS 的交互,存储数据到 HDFS
- 负责 Region 变大以后的拆分
- 负责 Storefile 的合并工作
1.2.5 HDFS
HDFS 为 Hbase 提供最终的底层数据存储服务,同时为 HBase 提供高可用(Hlog 存储在HDFS)的支持,具体功能概括如下:
- 提供元数据和表数据的底层分布式存储服务
- 数据多副本,保证的高可靠和高可用性
1.3 组件解析
1.3.1 HMaster
- 监控 RegionServer
- 处理 RegionServer 故障转移
- 处理元数据的变更
- 处理 region 的分配或转移 5.在空闲时间进行数据的负载均衡
- 通过 Zookeeper 发布自己的位置给客户端
1.3.2 RegionServer
- 负责存储 HBase 的实际数据
- 处理分配给它的 Region
- 刷新缓存到 HDFS
- 维护 Hlog
- 执行压缩
- 负责处理 Region 分片
1.3.3 其他组件
- Write-Ahead logs
HBase 的修改记录,当对 HBase 读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
- Region
Hbase 表的分片,HBase 表会根据 RowKey值被切分成不同的 region 存储在 RegionServer中,在一个 RegionServer 中可以有多个不同的 region。
- Store
HFile 存储在 Store 中,一个 Store 对应 HBase 表中的一个列族。
- MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL 中之后,RegsionServer 会在内存中存储键值对。
- HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。StoreFile 是以 Hfile的形式存储在 HDFS 的。
2、 集群搭建
2.1 配置
- 首先下载hbase的bin包:链接,我使用了最新的2.2.4版本,解压。
- 启动Zookeeper集群,因为hbase依赖于Zookeeper。
修改hbase-env.sh
export JAVA_HOME=/opt/jdk1.8# 禁止hbase管理自己的Zookeeper实例export HBASE_MANAGES_ZK=falseexport HADOOP_HOME=/opt/hadoopexport HBASE_HOME=/opt/hbase
配置hbase-site.xml:
<configuration><!-- 配置临时文件存放地址 --><property><name>hbase.tmp.dir</name><value>/opt/tmp/hbase</value></property><!-- 配置NN存储数据库元数据,端口和NN保持一致 --><property><name>hbase.rootdir</name><value>hdfs://hadoop101:9000/hbase</value></property><!-- 是否开启集群模式 --><property><name>hbase.cluster.distributed</name><value>true</value></property><!-- 完全分布式式必须为false --><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property><!-- 配置Zookeeper节点 --><property><name>hbase.zookeeper.quorum</name><value>hadoop101,hadoop102,hadoop103,hadoop104</value></property><!-- 配置Zookeeper客户端端口 --><property><name>hbase.zookeeper.property.clientPort</name><value>2181</value></property><!-- Zookeeper的数据存储目录,应和Zookeeper配置保持一致 --><property><name>hbase.zookeeper.property.dataDir</name><value>/opt/zookeeper/zkData</value></property></configuration>
需要知道两个端口号,hbase.master.port配置了主服务端口号,默认是16000;hbase.master.info.port配置了webUI界面的访问端口号,默认为16010
配置regionservers,将HDFS集群中的主机配置进来
hadoop101 hadoop102 hadoop103 hadoop104配置高可用,在/conf目录下新增文件配置backup-masters,这里列出允许作为master的主机
hadoop101将安装目录分发至所有主机
rsync -rvl /opt/hbase/ root@hadoop101:/opt/hbase/ rsync -rvl /opt/hbase/ root@hadoop103:/opt/hbase/ rsync -rvl /opt/hbase/ root@hadoop104:/opt/hbase/
2.2 启动集群
在安装目录下输入命令,会有部分类报错,可以不管
bin/start-hbase.shjps验证启动是否成功 ```shell [root@hadoop102 hbase]# jps 2033 DataNode 2721 HRegionServer 2774 Jps 2170 NodeManager 2522 HMaster
hadoop101是hbase高可用中的备用主机,所以启动了HMaster进程
[root@hadoop101 myTools]# jps 2466 NodeManager 1829 NameNode 2341 JobHistoryServer 3733 HRegionServer 1993 DataNode 3529 QuorumPeerMain 3802 HMaster 3851 Jps
[root@hadoop103 opt]# jps 2977 QuorumPeerMain 3153 HRegionServer 1819 SecondaryNameNode 3275 Jps 1740 DataNode 1916 NodeManager
[root@hadoop104 /]# jps 3570 Jps 3268 QuorumPeerMain 3431 HRegionServer 1768 DataNode 2153 NodeManager 1982 ResourceManager ```
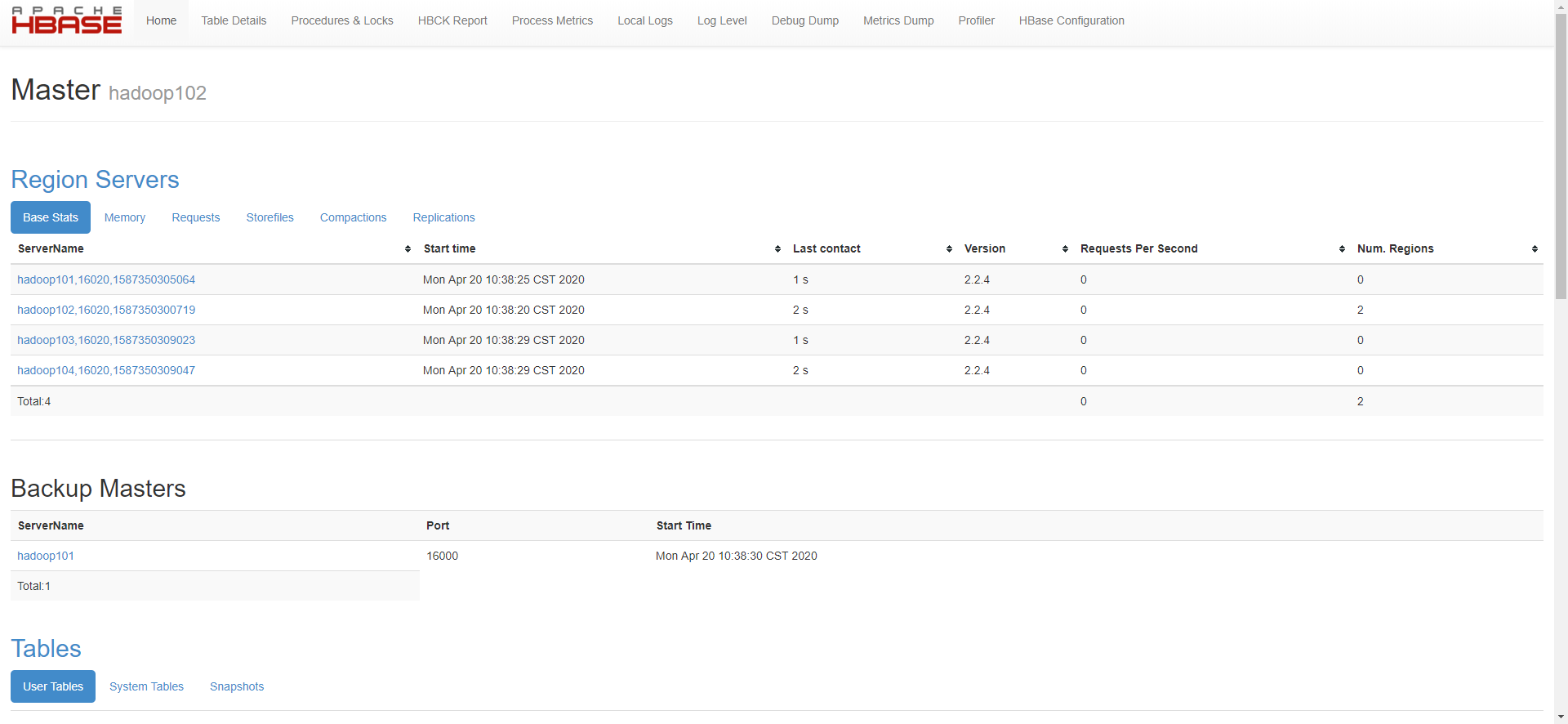
- 现在访问hbase自带的web页面,默认端口是16010:http://hadoop102:16010

若有收获,就点个赞吧
0 人点赞
