1.1 Hadoop的体系结构
Hadoop是一个Apache基金会开发的分布式系统基础架构,主要用来解决海量数据的存储与计算问题。广义来说,Hadoop是一个生态圈,类似于Spring。
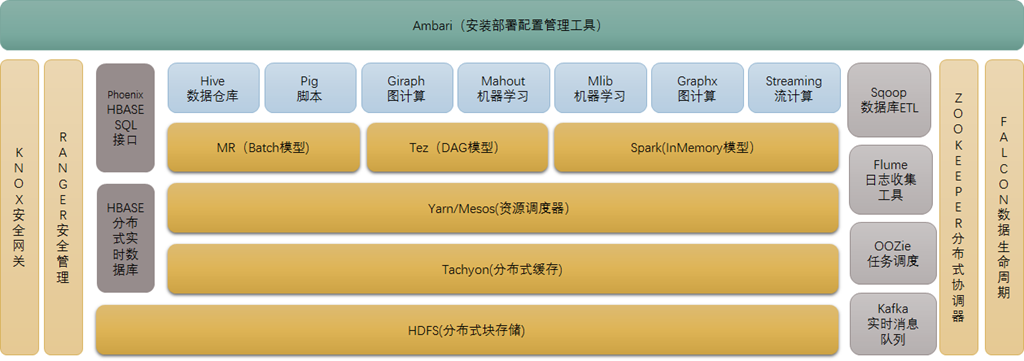
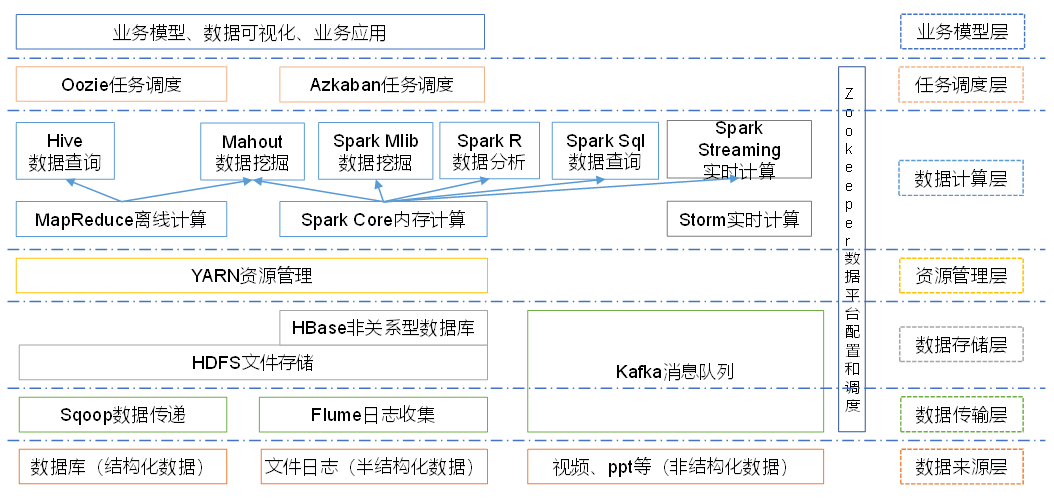
1.2 Hadoop的发展史


1.3 三大发行版本
- Hadoop三大发行版本:Apache、Cloudera、Hortonworks:
- Apache版本最原始(最基础)的版本,对于入门学习最好,建议从阿里云镜像库直接下载编译后的tar文件。
- Cloudera在大型互联网企业中用的较多,官网地址https://www.cloudera.com,该版本为成熟的商用解决方案,需要付费。
- Hortonworks文档支持较好,官网地址https://hortonworks.com/products/data-center/hdp/,也是需要付费的。
- 除此之外,Hadoop也有众多别的商业版本,各个版本根据使用场景会做不同的优化。
1.4 Hadoop的优势

1.5 Hadoop的组成
1.5.1 各大版本的特性
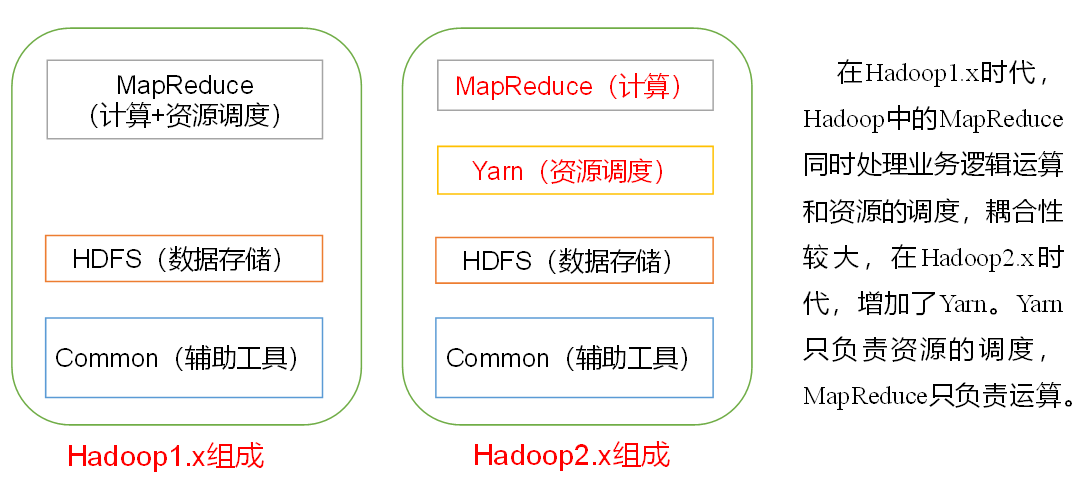
由于Hadoop2.0版本是用Java7开发的,而jdk7已经停止更新,因此最新的Hadoop3.0版本使用了jdk1.8进行开发,下面是Hadoop3.0的新特性:
Hadoop Common:**
- 精简Hadoop内核,包括剔除过期的API和实现,将默认组件实现替换成最高效的实现(比如将FileOutputCommitter缺省实现换为v2版本,废除hftp转由webhdfs替代,移除Hadoop子实现序列化库org.apache.hadoop.Records
- Classpath isolation以防止不同版本jar包冲突,比如google Guava在混合使用Hadoop、HBase和Spark时,很容易产生冲突。
- Shell脚本重构。 Hadoop 3.0对Hadoop的管理脚本进行了重构,修复了大量bug,增加了新特性,支持动态命令等。
Hadoop HDFS:
- HDFS支持数据的擦除编码,这使得HDFS在不降低可靠性的前提下,节省一半存储空间。
- 多NameNode支持,即支持一个集群中,一个active、多个standby namenode部署方式。注:多ResourceManager特性在hadoop 2.0中已经支持。
Hadoop MapReduce
- Tasknative优化。为MapReduce增加了C/C++的map output collector实现(包括Spill,Sort和IFile等),通过作业级别参数调整就可切换到该实现上。对于shuffle密集型应用,其性能可提高约30%。
- MapReduce内存参数自动推断。在Hadoop 2.0中,为MapReduce作业设置内存参数非常繁琐,涉及到两个参数:mapreduce.{map,reduce}.memory.mb和mapreduce.{map,reduce}.java.opts,一旦设置不合理,则会使得内存资源浪费严重,比如将前者设置为4096MB,但后者却是“-Xmx2g”,则剩余2g实际上无法让java堆内存heap使用到。
Hadoop YARN
- 基于cgroup的内存隔离和IO Disk隔离
- 用curator实现RM leader选举
- containerresizing
- Timelineserver next generation
1.5.2 HDFS概述
HDFS全称Hadoop Distributed File System:
**
- 是一个分布式文件存储系统
- NameNode(NN):存储了文件的元数据,包括文件名、目录结构、文件属性(创建时间、权限等),以及每个文件所在的块列表和块所在的DataNode等。
- DataNode(DN):负责在本地文件系统存储文件块数据,以及块数据的校验和。
- Secondary NameNode(2NN):监控HDFS系统的状态,是一个后台辅助程序,每隔一段时间获取元数据的快照
1.5.3 YARN概述
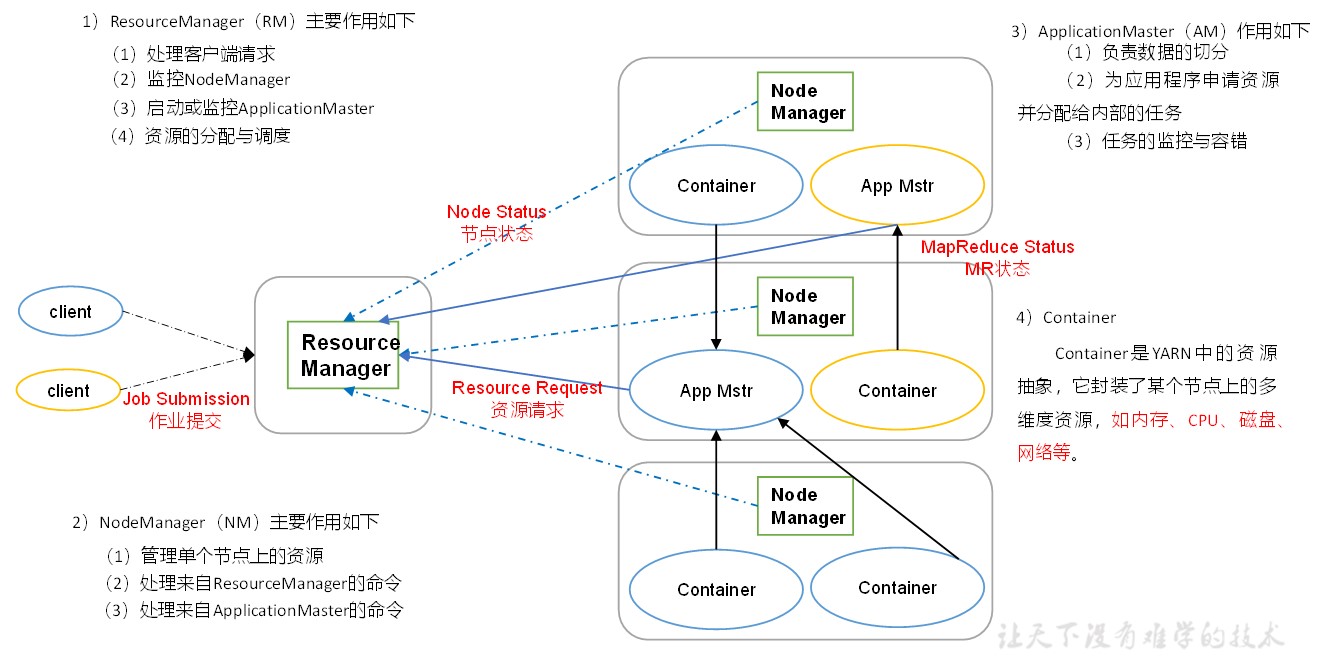
YARN是HDFS中的资源调度器,这个组件负责分配其他组件耗费的资源空间。
- ResourceManager(RM):总的资源管理器,负责处理客户端请求,监控NodeManager,启动或监控ApplicationMaster,资源的分配和调度。
- NodeManager(NM):管理单个节点的资源,负责执行其他两个部分下发的命令,包括ResourceManager和ApplicationMaster的命令。
- ApplicationMaster(AM):负责数据切分,能为应用申请资源,并将资源分给内部应用,还负责任务的监控与容错。
- Container是YARN的资源抽象层,封装来某个节点上的多种资源,比如内存、CPU、磁盘、网络等。
1.5.4 MapReduce概述
这个部分其实是分为两个部分:Map,Reduce,Map是在数据输入阶段做并行处理(提高数据吞吐量),Reduce是在数据输入完毕后汇总至服务器的阶段。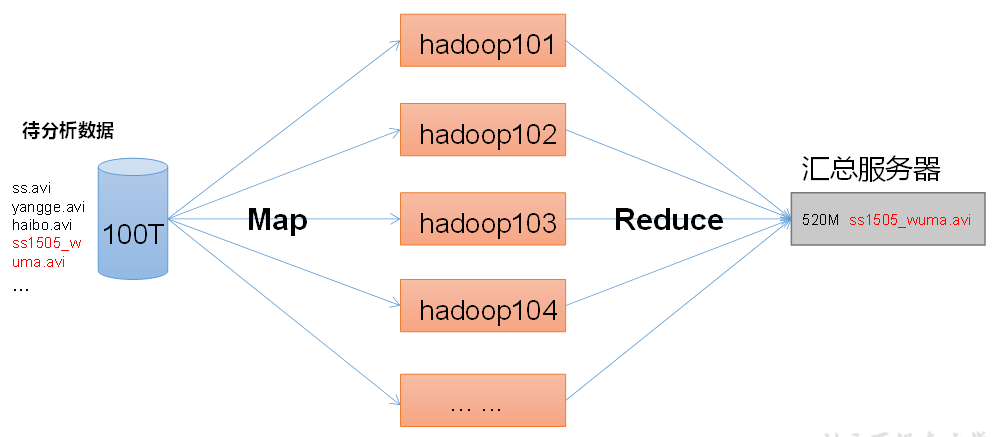
1.6 安装与使用
1.6.1 主机的准备
- 虚拟机准备:建议选择CenterOS 8介质安装,网络配置先使用动态配置(DHCP),选择最小安装-标准安装即可。
- 建议安装wget:yum install wget
- 更换阿里镜像源:进入/etc/yum.repos.d目录,备份CentOS-Base.repo文件,输入命令下载阿里镜像配置文件:
- wget http://mirrors.aliyun.com/repo/Centos-8.repo
- 然后依次执行下面的命令:
- yum clean all
- yum makecache
- yum update(可选,更新全局软件版本)
- 安装jdk,要求版本1.8以上:下载jdk的tar包,解压缩,通过命令 vim /etc/profile 编辑配置文件,在末尾追加
- 安装Hadoop:下载tar包后解压即可,然后配置环境变量:

- 输入 source /etc/profile 使配置生效
- 通过 java -version 和 hadoop version 验证安装是否成功
- 修改dns配置 vim /etc/resolv.conf ,dns服务器根据情况自定,通常使用谷歌dns服务器4.4.4.4和8.8.8.8
- 修改网络配置 vim /etc/sysconfig/network-scripts/ifcfg-ens33 :
- BOOTPROTO=”dhcp”改为”static”,从动态获取变为静态模式
- 增加IPADDR=”x.x.x.x”设置固定ip
- hostnamectl set-hostname “master” 可以修改主机名
1.6.2 虚拟机配置与克隆
1.6.2-1 传统克隆方式
- 主机准备完成后即可关闭虚拟机,然后执行克隆操作,根据需要来调整克隆的数量,克隆完毕后,一定记得重新生成网卡物理地址
- **
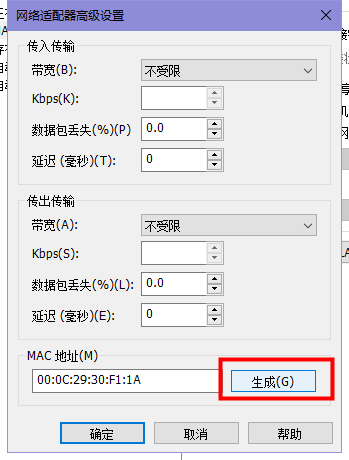
- 调整后即可保证每台服务器的Mac地址不一样了。
- 开机修改每个克隆机的主机名、ip地址、UUID即可
1.6.2-2 更简单的复制方式
- 除了使用软件来操作克隆,还可以直接复制磁盘虚拟机文件夹,修改名字后再软件中打开,选择我已复制该虚拟机,VMware会自动分配新的Mac地址
- 有个缺点是主机必须使用DHCP模式,如果设置静态IP,Mac地址将无法自动改变。
1.6.2-3 hosts主机映射配置
编辑hosts文件,修改完成后,所有的虚拟机应该能够互相ping通,示例如下:
192.168.217.101 hadoop101
192.168.217.102 hadoop102
192.168.217.103 hadoop103
192.168.217.104 hadoop104
192.168.217.105 hadoop105
192.168.217.106 hadoop106
192.168.217.107 hadoop107
192.168.217.108 hadoop108
1.7 本地运行模式
1.7.1 官网地址
hadoop官网教程地址为:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html,通过该教程可以快速的入手hadoop的使用。
1.7.2 运行示例
根据官方教程,hadoop是可以通过单主机本地运行的方式运行的,进入hadoop安装目录下:
$ mkdir input$ cp etc/hadoop/*.xml input$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input/ output 'dfs[a-z.]+'$ cat output/*
- 首先创建一个input文件夹作为数据输入的来源,将自带的所有配置文件放入,然后运行示例java程序来分析该文本中和给定正则表达式匹配的数据。
- 运行后会在当前所处目录中生成一个output目录,进入可看到里边有两个文件
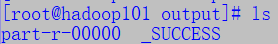
- 查看part文件,可以看到以下输出:

- 可以看到,dfsa打头的字符串出现了一个dfsadmin
- 注意output目录不能自己创建,应交给hadoop自己生成
1.8 伪分布式运行
伪分布式即每个hadoop的守护进程运行在独立的java进程上,而不是共用同一个java进程。
1.8.1 配置
- 首先是etc/hadoop/core-site.xml文件,defaultFS指定NameNode地址(注意主机名一致),tmp.dir指定临时文件存放目录。
```xmlfs.defaultFS hdfs://hadoop101:9000
- 然后etc/hadoop/hdfs-site.xml文件,指定HDFS副本的数量。xml
- 指定jdk路径,修改hadoop-env.sh文件,追加配置(有了这个配置后才能从网页打开控制台):shell
export JAVA_HOME=jdk安装路径
<a name="lTqeW"></a>
### 1.8.2 运行
- 格式化NN(第一次启动格式化即可,之后使用不要格式化)shell
bin/hdfs namenode -format
- ~~(弃用)通过hadoop-daemon.sh脚本启动NN和DN~~shell
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
~~
- 新的hadoop版本中推荐使用hdfs --daemon start命令启动,**应按照顺序启动,先有NN,再有DN**shell
hdfs —daemon start namenode
hdfs —daemon start datanode
~~
- 输入jps检验是否启动成功shell
[root@hadoop101 hadoop-3.1.3]# jps
2536 DataNode
2351 NameNode
2623 Jps
- web端直接访问
hadoop自带了一个web管理页面供外部访问:[http://hadoop101:9870](http://hadoop101:9870),只要配置了jdk路径即可在启动后访问,hadoop老版本中,端口号是50070,新版本改为9870
通过页面上的菜单,可以把本地文件上传至HDFS中存储。
<a name="OpQwc"></a>
### 1.8.3 为什么不能经常格式化NN?
我们之前配置过hadoop运行时的数据存放目录:**/opt/tmp/hadoop**,通过以下命令我们可以查看集群的元信息:shell
cd /opt/tmp/hadoop/dfs/name/current/
cat VERSION
上述命令会打印一串字符串,这个就是**NN的ID**,当你运行了格式化NN命令后,会发现ID变化了,但是DN中记录的NN却仍是老的ID,这时就会导致节点数据丢失,无法查找到老数据。所以,格式NameNode时,一定要**停止相关进程,删除data数据和log日志**,然后再格式化NameNode。
<a name="cHkvy"></a>
## 1.9 操作集群
<a name="qCuHM"></a>
### 1.9.1 上传文件至HDFS
- 在HDFS上创建一个input文件夹,我的路径为/opt/input
- 准备一个文本文件,我存在/opt/test.txt下,通过put命令将该文件传入HDFS中shell
bin/hdfs dfs -mkdir -p /opt/input
bin/hdfs dfs -put /opt/test.txt /opt/input
- 上传成功后,在网页管理端可以看到该文件信息
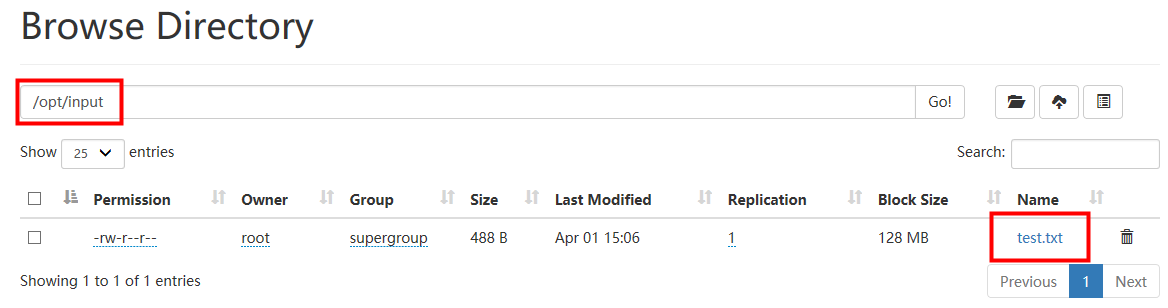
- HDFS以**Block**(块)来作为数据存储的基本单位,一个块默认是128MB
- 进入/opt/tmp/hadoop/目录我们可以看到hadoop运行时产生的数据文件,通过探寻我们发现,这个块文件最终被放进了下面的目录中,特别长,shell
cd /opt/tmp/hadoop/dfs/data/current/BP-1895896188-192.168.217.101-1585709649773/current/finalized/subdir0/subdir0
- hadoop3将多个块放进了一个块池(block pool)中:
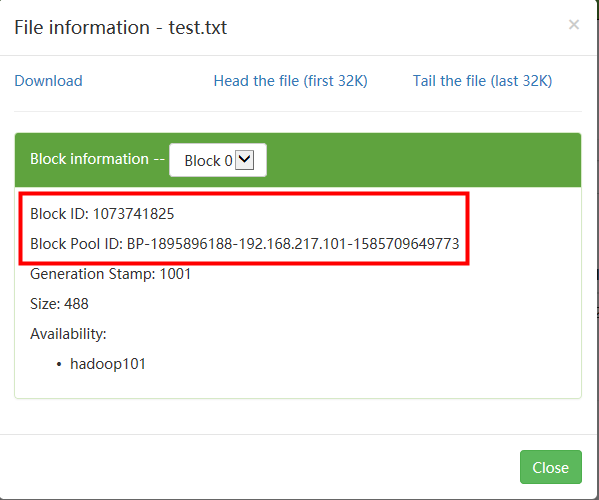
- 通过寻找,我们发现块id和池id是可以在磁盘中找到的

<a name="uMsHs"></a>
### 1.9.2 运行MapReduce处理数据
- 与本地模式一样,在hadoop目录下运行MapReduce命令shell
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /opt/input /opt/output
- 查看结果,注意,此时的MapReduce输出目录虽然指定的是/opt/output,但这个**路径不是指磁盘路径,而是HDFS自身的路径**,所以你是无法在磁盘找到/opt/output这个目录的,只能通过命令查看shell
bin/hdfs dfs -cat /opt/output/
```
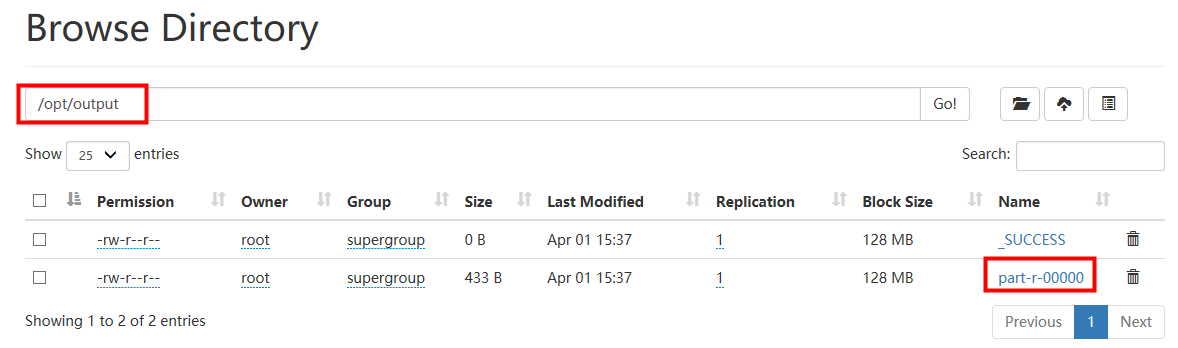
 - 浏览器也可以查看到输出记录
- 浏览器也可以查看到输出记录
 ## 1.10 YARN的使用
###
### 1.10.1 配置
- 配置:*yarn-site.xml
```xml
## 1.10 YARN的使用
###
### 1.10.1 配置
- 配置:*yarn-site.xml
```xml
- 配置:**mapred-site.xml**```xml<!-- 指定MR运行在YARN上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
- 配置 yarn-env.sh 和 mapred-env.sh
export JAVA_HOME=/opt/jdk1.8.0_241
1.10.2 启动
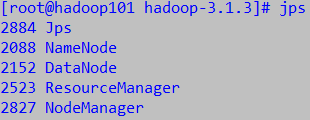
- 首先启动NN和DN
然后启动ResourceManager和NodeManager
yarn --daemon start resourcemanageryarn --daemon start nodemanager
jps命令查看是否启动成功
- YARN也自带浏览器页面http://hadoop101:8088/cluster
1.10.3 日志
先删除之前的output文件夹
bin/hdfs dfs -rm -R /opt/output
重新运行一次MapReduce

若有收获,就点个赞吧
0 人点赞
