四种、常见运行模式
参考:Spark的四大运行模式以及原理简介:| | | | —- | —- | | | | | | | | | | | | | | | 以client模式连接到YARN.cluster 集群的位置基于HADOOP_CONF_DIR 变量找到 | | | 以模式连接到YARN.cluster 集群的位置基于HADOOP_CONF_DIR 变量找到 |
区别:
| | |
| —- | —- |
| | |
| | spark 自带的资源调度框架,支持分布式搭建,Spark任务可以依赖stanalone调度资源,它有基于Standalone-client和Standalone-cluster两种提交模式,这里我以sparkPI为例,环境是Spark1.6两种模式 |
| | yarn-client:
yarn-cluster: |
| | |
一、local模式下的 spark-shell的使用

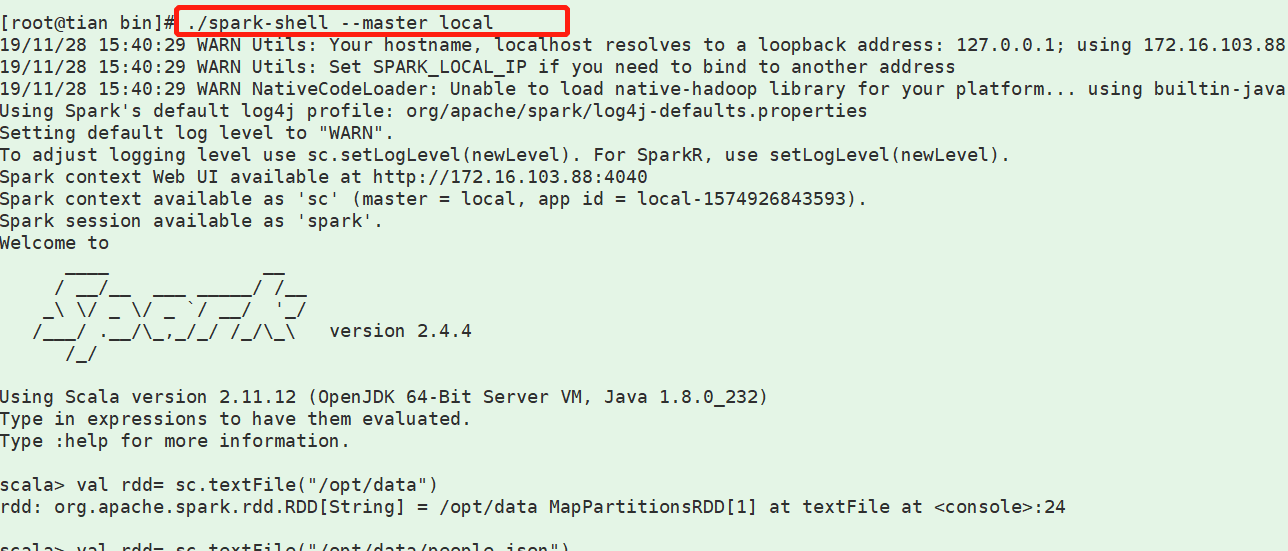
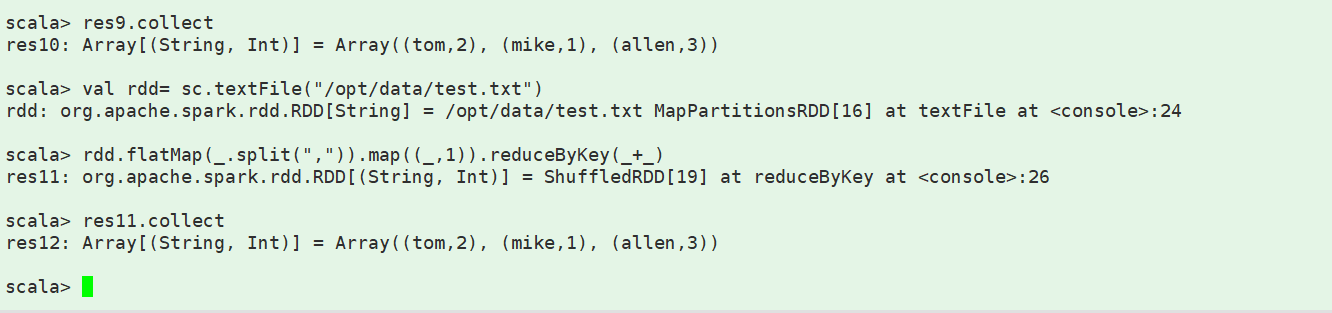
二、local模式下使用spark-submit提交spark作业(jar包)1、采用 maven自带的 package 进行打源码包 瘦打包(不含jar)2、这里采用 rz 把 jar 包和几个测试文件 从 w10本地上传到 云主机 3、执行
3、执行
自己的jar 测试
三、yarn运行
四、standlone运行1、配置从节点在spark-2.4.4-bin-hadoop2.7/conf
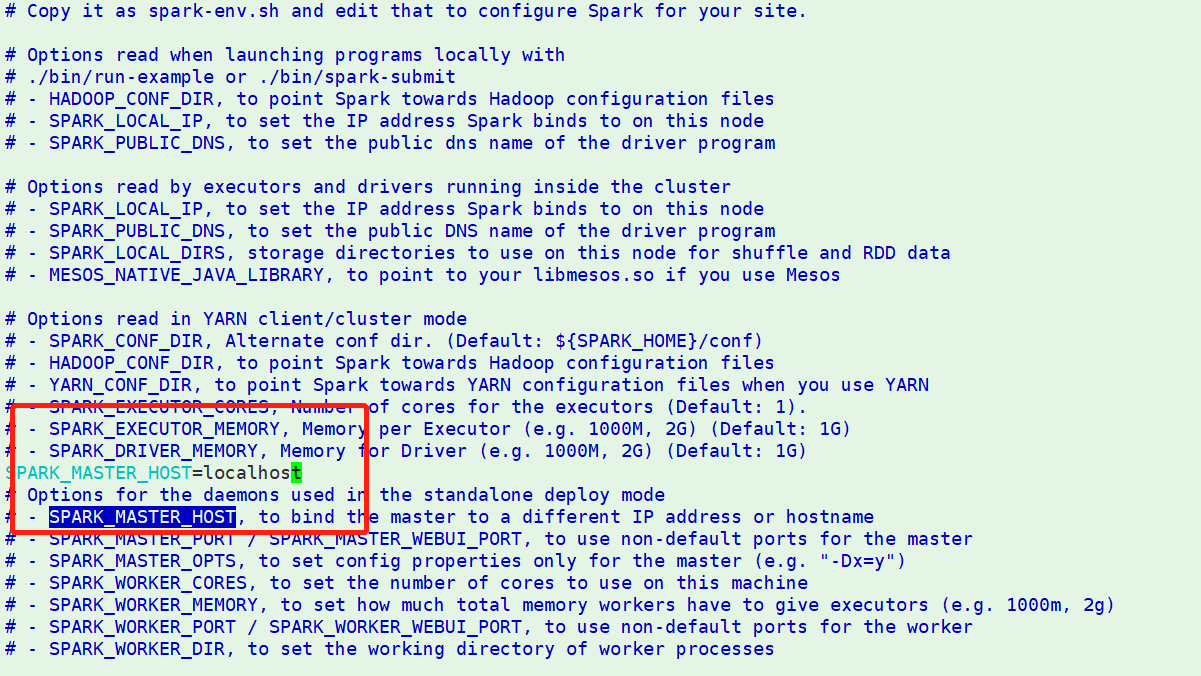 3、启动集群进入spark-2.4.4-bin-hadoop2.7/sbin
3、启动集群进入spark-2.4.4-bin-hadoop2.7/sbin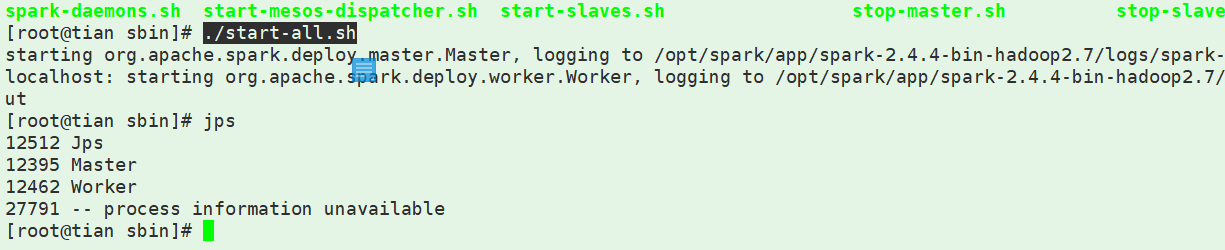
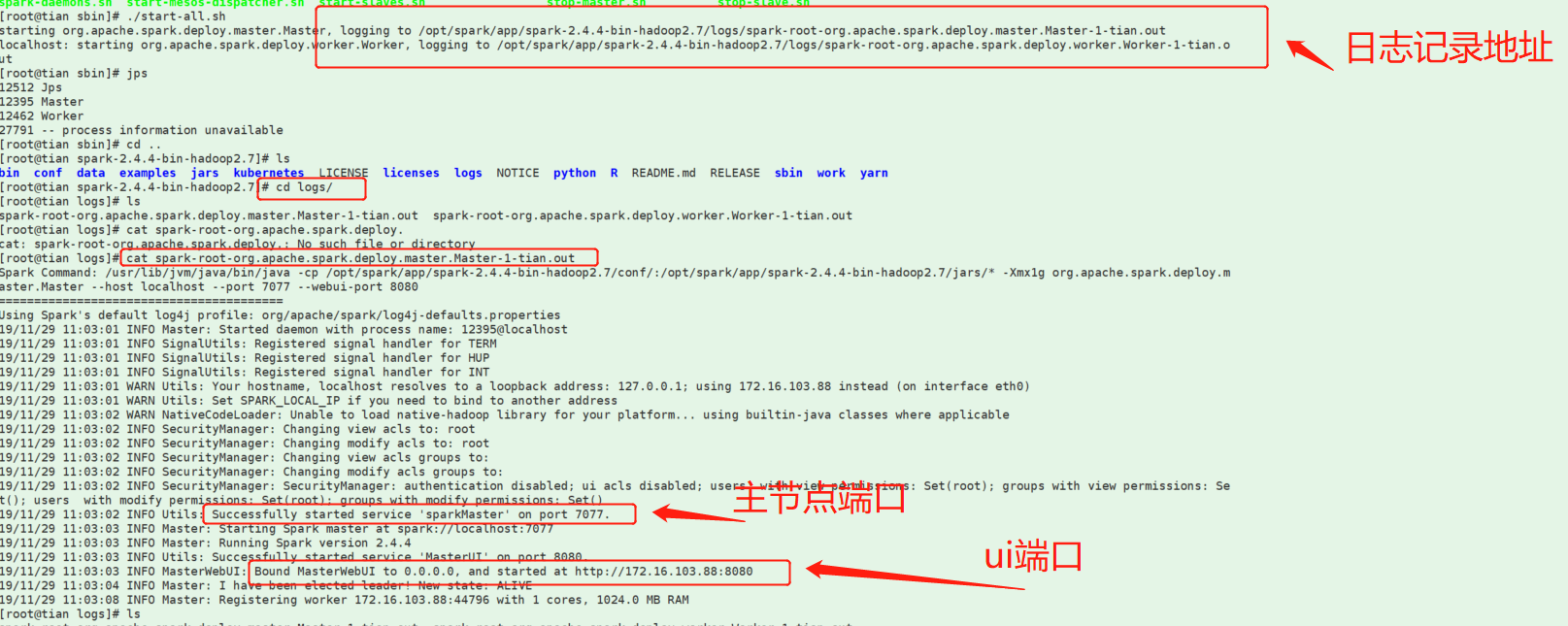 进入spark-2.4.4-bin-hadoop2.7/bin执行:自己案例测试
进入spark-2.4.4-bin-hadoop2.7/bin执行:自己案例测试

若有收获,就点个赞吧
0 人点赞
