搭建(1)spark 单机、standalone
一、单机配置
1、下载 http://spark.apache.org/downloads.html
2、修改配置文件2.1、配置环境变量
2.2、目录在 $SPARK_HOME/conf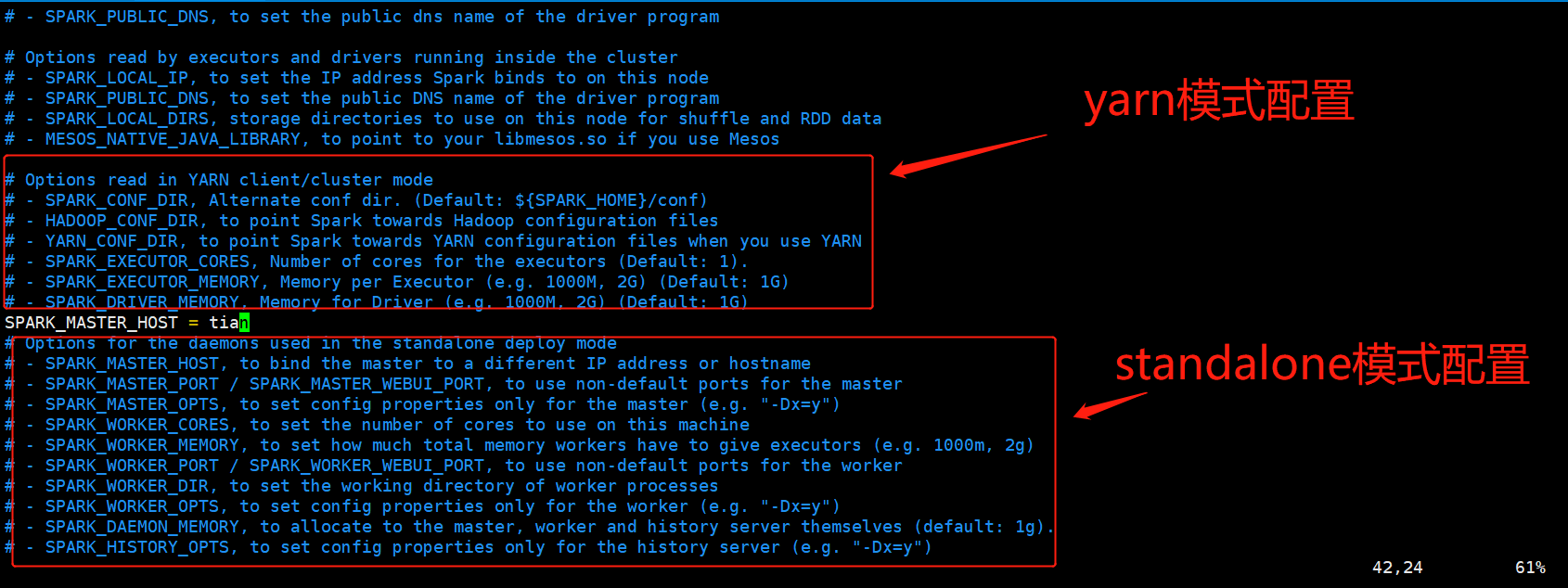
2.3、将slaves.template重命名为slaves修改为如下内容:这里测试用的一台机器所以 所以写的还是 主机名 tian,当然默认的参数 localhost未尝不可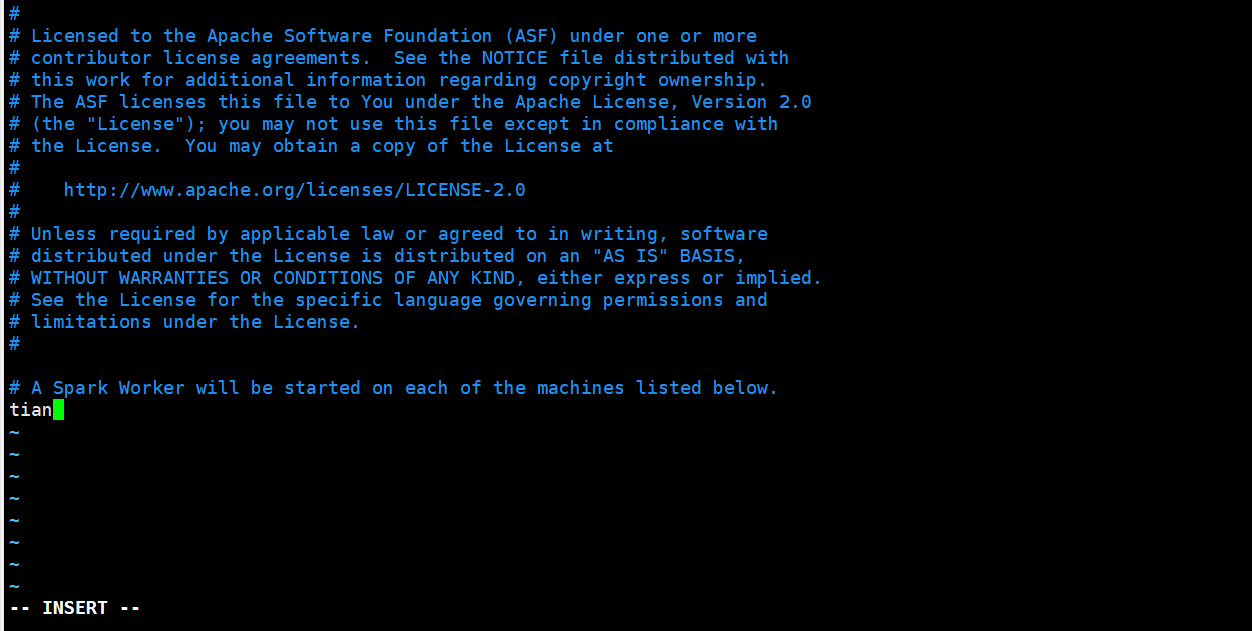
2.4、配置java的环境变量在 $SPARK_HOME/sbin 目录下的 spark-config.sh文件下未添加JAVA_HOME的索引.
3、这里采用standalone 模式所以 不配置 hadoop相关后续补:
4、配置Scala环境
### 4.1 安装Scala
spark中已经默认带有scala,如果没有或者要安装其他版本可以下载安装包安装,过程如下:先下载安装包,然后解压 tar zxvf scala-2.12.5.tgz -C /usr/local/bigdata/
然后在~/.bashrc文件中添加如下内容,并执行$ source ~/.bashrc命令使其生效测试是否安装成功,可以执行如下命令:
4.2 启动Spark shell界面
执行spark-shell —master spark://master:7077命令,启动spark shell。二、standalone集群配置
https://www.jianshu.com/p/aee59bcafc6a基于 1、单机配置 步骤
1、在上面步骤 2.3 Slave01Slave022、分发同步 同样的配置到集群各节点 2.1、考虑 设置 2.2 将配置好的Spark拷贝到其他节点上
3、在主节点下 $SPARK_HOME/sbin目录下 启动

若有收获,就点个赞吧
0 人点赞
