(1)hadoop安装步骤
在 用户~ 目录新建
software(存放安装包)、app(存放软件安装目录) 、
data(存放数据) 、lib(存放课程中的jar)、
shell (存放相关脚本)、maven_resp(maven仓库)
等目录
1 、下载到 ~/software
wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.15.1.tar.gz
2、解压到 ~/app
tar -zxvf hadoop-2.6.0-cdh5.14.0.tar.gz ~/app/
3、进入app 查看 hadoop的相关目录
bin:hadoop 客户端名称
etc/hadoop:hadoop 相关的配置文件存放目录
sbin:启动hadoop相关进程的脚本
share:常用例子
4、环境变量配置 进入app/hadoop目录下
注意:这里一定配置单独的环境变量 获取系统的无效
设置java的环境变量 (yum安装的默认路径)
/opt/hadoop/app/hadoop-2.6.0-cdh5.11.1/etc/hadoop/hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java
配置hadoop 环境变量 (用户范围)
vim ~/.bash_profile
export HADOOP_HOME=/root/app/hadoop-2.9.2/
#这里我设置了 java的环境变量但是好像无效,所以使用上面的配置
export JAVA_HOME=/usr/lib/jvm/java
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin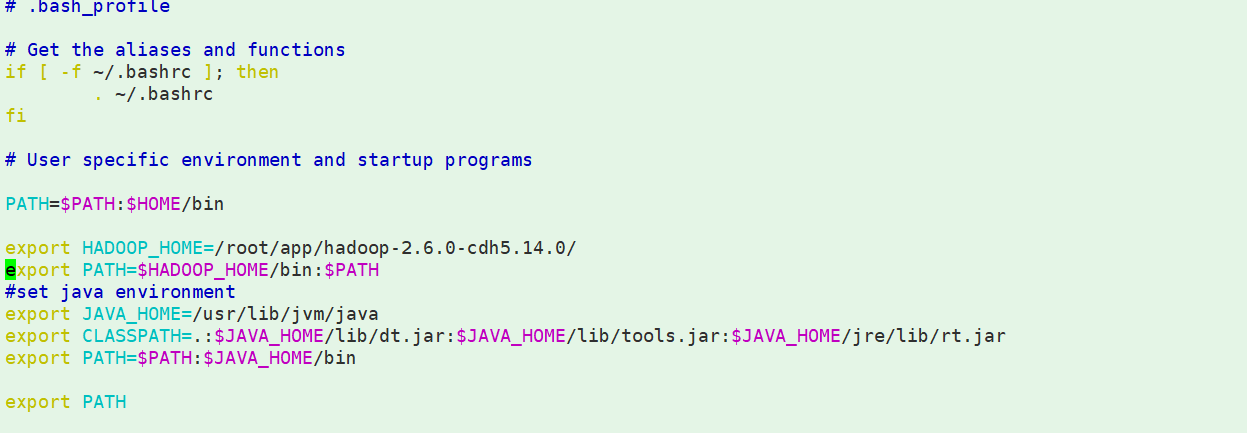
(配置全局范围) vim /etc/profile
export HADOOP_HOME=/opt/hadoop/app/hadoop-2.6.0-cdh5.15.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
一定要
source /etc/profile
source ~/.bash_profile
否者刚刚配置无法生效
5、xml文件的配置
目录在 /root/app/hadoop-2.6.0-cdh5.14.0/etc/hadoop
5.1 etc/hadoop/core-site.xml:
默认的文件系统
5.2 (可不配)etc/hadoop/hdfs-site.xml: hadoop.tmp.dir
hadoop 默认3个节点。默认给它一个
6、etc/hadoop/目录下(可不配)
slaves
主机名(我的是 tian)
7、启动 HDFS :
第一次启动的时候要格式化文件系统,不要重复执行
在/opt/hadoop/app/hadoop-2.6.0-cdh5.15.1/sbin 目录下
执行
注意:如果不是第一次vim,格式化之前需要清除 自定义路径 下的 /dfs 内容,否者会有问题
hdfs namenode -format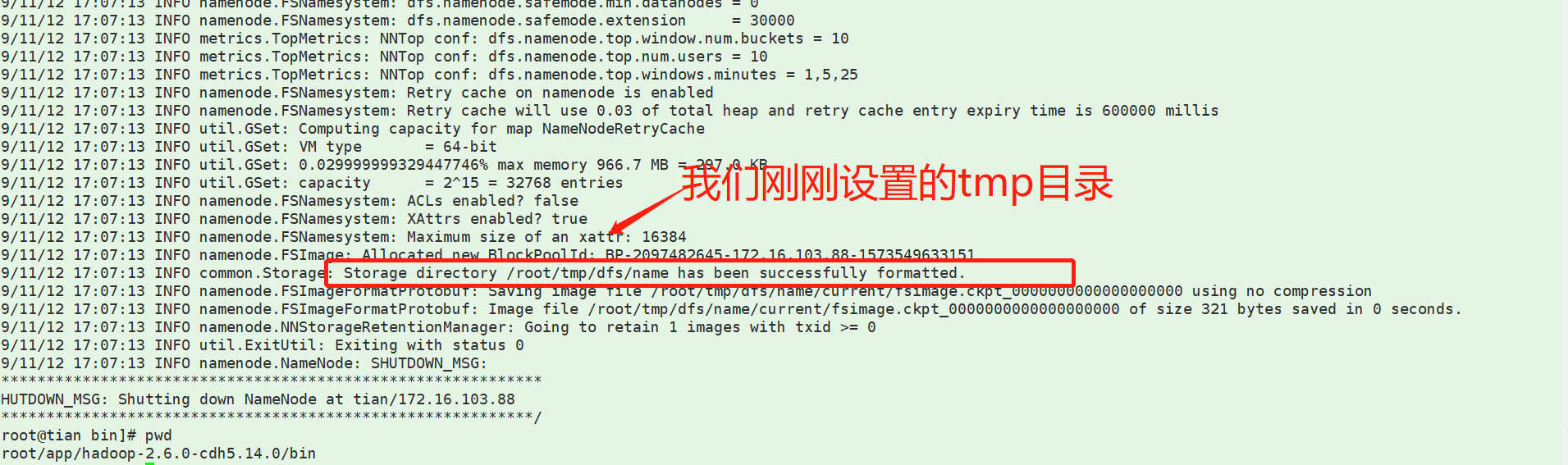
在/root/app/hadoop-2.6.0-cdh5.14.0/sbin 目录下 启动集群
执行
./start-dfs.sh
启动正常过程
启动成功 通过jps 查看 java进程
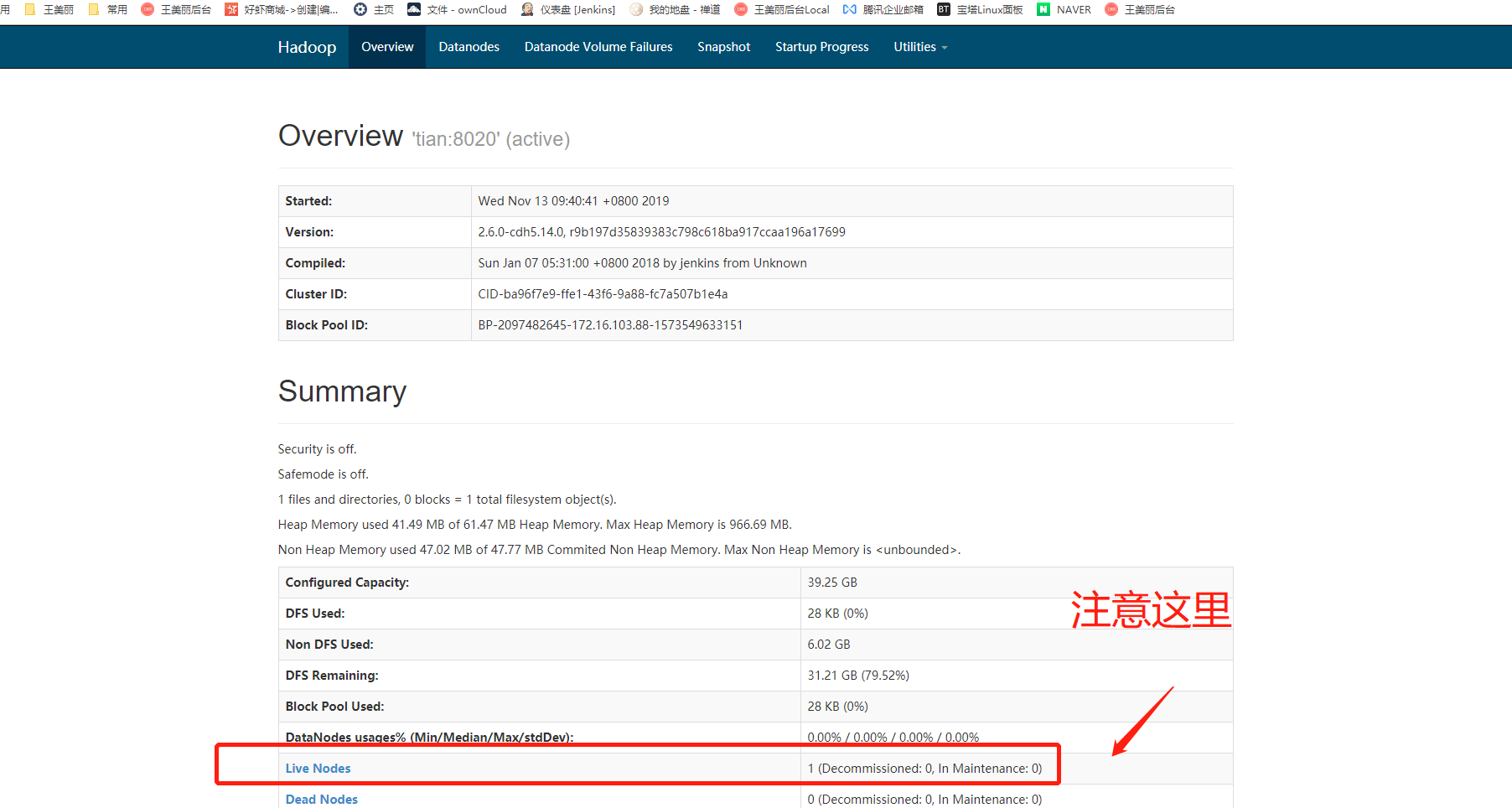
登陆 http://IP:50070(默认端口)/查看hadoop 简单面板
http://47.98.253.2:50070/
50070其实是在hdfs-site.xml里面的配置参数dfs.namenode.http-address,默认配置为dfs.namenode.http-address,这是HDFS web界面的监听端口
8、停止集群及单个进程启动
如果配置了环境hadoop变量 则进 cd $HADOOP
在/root/app/hadoop-2.6.0-cdh5.14.0/sbin 目录下执行
./stop-dfs.sh
分析 start-dfs.sh 文件可知
start-dfs.sh = hadoop-daemons.sh start datanode +
hadoop-daemons.sh start namenode +
hadoop-daemons.sh start secondarynamenode(第二节点)
同理:
stop-dfs.sh = hadoop-daemons.sh stop datanode +
hadoop-daemons.sh stop namenode +
hadoop-daemons.sh stop secondarynamenode
参考:hadoop集群管理之 SecondaryNameNode和NameNode
注意:
给hadoop用户 root权限

若有收获,就点个赞吧
0 人点赞
