- 什么是方法的重写?
- Java 类的继承特点?
- 抽象类存在的意义?
- final 关键字的作用?
- 接口中可以定义哪些成员?
- 什么是接口的多继承和多实现?
- 多态的前提条件有哪些?
- 多态的好处和弊端有哪些?
- java.util.Date 类是什么?有哪些常用方法?
- java.text.DateFormat 类是什么?有哪些常用方法??
- java.math.BigDecimal 类的特点?
- 包装类有哪些?什么是装箱和拆箱?
- Collection 集合的常用方法有哪些?
- 泛型的好处
- 常用数据结构及其特点?
- List 集合特点?
- 什么是可变参数,有哪些注意事项?
- HashSet 集合的特点?
- TreeSet 集合特点?
- 有哪些常用的双列集合及其特点?
- error 和 exception 的区别?
- 异常的分类
- java 异常处理机制
- 请写出你最常见的 5 个 RuntimeException
- 什么是进程和线程?
- 创建多线程的格式有几种?
- Thread和Runnable的使用区别?
- java中的线程执行调度方式是哪一种?
- 同步代码块、同步方法、静态同步的锁的区别?
- 可见性问题的理解与解决?
- 原子性问题的理解与解决?
- 什么是死锁?
- 什么是递归?
- IO流的体系介绍?
- 用语言描述IO流实现读写数据读写的过程?
- 请说明追加写入和换行的基本实现方式?
- 解释什么是装饰着设计模式?举例具体的应用。
- 常见的IO流类有哪些?简述其功能。
- 什么是序列化与反序列化?
- 请描述对于字节流与字符流转化的桥梁这句话的理解。
- 请说出什么是网络编程三要素?
- 请解释什么是三次握手协议?
- 请简单描述NIO的组成。
- 请简单描述同步/异步,阻塞/非阻塞
- 什么是反射?
- 什么是注解?
- 什么是动态代理模式?
- 说一下你了解的jdk8的新特新。
- 说明XML文档的约束分类。
- 什么是XML解析器,常见的XML文档解析工具有哪些?
- 简单介绍什么是xpath。
- 什么是正则表达式?
- 介绍多列设计模式?
- 什么是枚举?
- java中的引用类型有哪些?
- 什么是工厂设计模式?
- Request对象的主要方法有哪些?
- 如何取获得请求参数?
- 如何处理请求参数中文乱码?
- 响应中文乱码怎么解决?
- session的生命周期是什么
- cookie的生命周期的分别是什么
- cookie常用方法有哪些?
- cookie的原理是什么是?
- JSP和Servlet有哪些相同点和不同点,他们之间的联系是什么?
- JS中两种跳转方式分别是什么?有什么区别? ?
- el的可以取值的对象是有哪些?
- mvc是什么概念
- 如何使用过滤器,统一处理全网站中文乱码的问题
- 过滤器映射路径的配置有哪几种?
- 监听ServletContext对象的创建和销毁
- 如何让过滤器可以区分不同的访问资源的方式,有不同的拦截方式?
- 如何实现添加联系人?
- 如何实现删除联系人?
- 如何实现查询的数据进行分页显示
- 分页查询的时候,如何操作数据库?
- JQ常用事件有哪些?
- val(),text(),html()三者在获取内容时候有什么区别
- remove() 和empty() 在清空内容时候有什么区别
- keydown和keypress在使用时候有什么区别
- ajax的TEXT和jason返回值类型的区别
- Ajax中POST和GET的区别
- JackSon: json和java对象如何互相转换?
- FastJSON:json和java对象如何互相转换?
- 介绍vue的生命周期
- Vue实现数据双向绑定的原理
- Linux系统的主要应用场景?
- Linux 怎么关闭进程
- 什么是Redis持久化?Redis有哪几种持久化方式?
- Reids的特点
- maven管理项目生命周期的命令有哪些
- maven的坐标含义
- Mybatis 的编程步骤是什么样的?
- JDBC 编程有哪些不足之处, MyBatis 是如何解决这些问题的?
- Mybatis 中一级缓存与二级缓存?
- 说一说mybatis底层所使用的设计模式有哪些
- ElementUI的表单组件怎么使用?它有哪些属性?
- ElementUI的表格组件怎么使用?它有哪些属性?
- 基础题库新增的流程介绍
- 图片上传的注意点
- 登录与注册的流程分析
- 微信小程序的代码结构介绍
- 题库分类列表展示的流程介绍
- 题目详情信息展示的流程
- nginx的简介和作用
- 反向代理的介绍
- 谈谈Spring的IoC
- 谈谈Spring的DI
- Spring中bean的作用域有哪些?
- Spring的配置方式有哪些
- @Component, @Controller, @Service, @Repository注解有什么作用和区别
- 什么是AOP
- 请说明AOP中相关的概念
- Spring的AOP有哪些通知类型
- Spring中事务的隔离级别有哪些
- Spring中事务传播行为有哪些
- SpringMVC的执行流程
- SpringMVC常用注解有哪些
- @RequestMapping注解的作用
- 如何解决请求参数乱码的问题
- SpringMVC如何实现文件上传
- SpringMVC的异常处理方案
- 过滤器Filter和SpringMVC的拦截器的区别
- 为什么要工程拆分?
- 为什么用Git不用SVN?
- 说一说Zookeeper数据结构?
- zookeeper安装需要注意哪些?
- Zookeeper中如何实现监听?
- zookeeper集群模式下,如何选举?
- 什么是RPC?
- RCP调用过程?
- dubbo架构调用流程?
- dubbo中负载均衡策略有哪些?
- 传智健康这个项目有哪些模块?
- 传智健康使用了哪些技术架构?
- 说一说项目工程的结构
- 说一说项目工程各模块间的关系
- 使用分页插件PageHelper需要哪些步骤?
- 检查项能否直接删除?
- 添加检查组需要操作哪些表?
- 添加检查组的业务服务中有哪些步骤?
- 说一说添加套餐的业务流程
- Quartz的执行流程
- 使用redis做清理七牛上垃圾图片的思路
- POI写excel的步骤有哪些?
- 简要说一下批量导入预约设置信息操作过程?
- 移动端开发方式有哪些?
- 说一说使用发送验证码的操作步骤
- 说一说提交体检预约的操作步骤
- Spring Security入门案例有哪些步骤?
- 什么是认证与授权?
- 说一说springboot大体的使用步骤
- 说一说springboot控制版本的原理
- 说一说springboot常用的注解
- rabbitmq的消息模式有哪些各自有哪些特点
- 如何确保消息接收方消费了消息
- 说下eureka的架构流程
- 谈一谈 spring cloud openfeign
- 谈一谈网关gateway以及他的作用
- elasticsearch是什么?有什么优点
- elasticsearch的实现原理是什么
- 如何实现高亮查询
- 说一说常用的查询以及各自的特性
- 说说电商常见的模式
- 简单聊聊电商行业技术特点
- 能够画出项目架构图
- 说说FastDFS相关术语以及作用
- 说说FastDFS的运行原理(画图)
- 能够说出FastDFS的文件上传的代码步骤
- 说出SPU和SKU的概念并举例
- 说出商品保存整个过程涉及到的表
- 说出商品保存的代码实现的步骤
- 通过学习的lua语法,定义一个返回两个数的最大的函数(需要对所写语句进行说明)
- 能够说出前台系统广告的加载流程
- 什么是限流以及nginx限流方式
- 说出canal工作原理和实现广告同步过程
- 说出ES中常见的过滤方式
- 说出数据导入索引库的代码步骤
- 如何实现关键字检索(业务层代码)
- 说出ES统计查询的步骤
- 说出实现关键字高亮显示
- 什么是Thymeleaf
- 说出所学的thymeleaf的语法以及作用
- 说出回显商品列表数据思路
- 说出网关的好处
- 什么是JWT以及它的组成部分
- 说出鉴权的代码实现思路
- 什么是单点登录?
- 说说Oauth2.0认证流程,画面说明
- Oauth2授权模式有几种?
- 介绍下非对称加密算法中的公钥与私钥(图解)
- 资源服务授权配置有哪些步骤?
- OAuth认证微服务对接普通微服务?
- 说明购物车的类型
- 介绍下hystrix隔离模式
- Oauth中如何保持登录会话?
- 说说订单结算功能涉及的表。
- 微信扫码支付申请流程有哪些?
- 说说项目中使用的微信支付模式整体流程。
- 说明项目中整体如何对接微信支付,画图说明。
- 秒杀是什么?
- 说说秒杀整体设计思路,画图说明。
- 秒杀中如何防止超卖?
- 普通订单与秒杀订单如何共用一个支付微服务,说说思路。
- 什么是事务?
- 什么是分布式事务?
- 分布式事务的解决方案有哪些?
- 集群与分布式的区别?
- 说说Eureka集群的架构
- 说说Redis-Cluster整体原理
- 什么是缓存雪崩?
- 什么是缓存穿透?
什么是方法的重写?
方法重写,指的是子父类中出现一模一样的方法(返回值类型、方法名以及参数列表都相同),此时会出现覆盖效果,也称为方法的 “重写” 、“复写”。表示方法的声明不变,但子类重写了从父类中继承过来的方法。
@Override 注解是一个重写校验注解,可以写在方法上,如果这个方法满足重写条件,则编译通过,如果不满足重写条件,就会编译失败。
Java 类的继承特点?
Java 只支持单继承,一个类只能继承自一个类,但是可以有多个子类,可以多层继承。
抽象类存在的意义?
抽象类不能创建对象,它存在的意义就是给子类继承。其中定义的抽象方法体现的是模板思想,相当于是提供了一个标准,子类可以根据这个标准实现符合自己的业务逻辑。
final 关键字的作用?
final 是 Java 中的一个关键字,表示最终的,可以用于修饰类、方法和变量。
修饰类:被 final 修饰的类不能被继承;
修饰方法:被 final 修饰的方法不能被重写;
修饰变量:被 final 修饰的变量不能被重新赋值,即常量;
接口中可以定义哪些成员?
JDK7及以前:常量、抽象方法
JDK8及以后:常量、抽象方法、默认方法、静态方法
什么是接口的多继承和多实现?
类和类之间是继承关系,只支持单继承。
类和接口之间是实现关系,支持多实现,允许一个类同时实现多个接口。
接口和接口之间是继承关系,支持多继承,允许一个接口同时继承多个接口。
多态的前提条件有哪些?
要有继承或者实现关系;
要有方法的重写;
要有父类引用指向子类对象。
多态的好处和弊端有哪些?
多态的好处是提高了代码的扩展性和复用性;
多态的弊端是无法访问子类特有的方法,如果要访问子类中特有的方法,可以将父类类型的变量向下转型成子类类型,向下转型时要注意类型转换异常,可以使用 instanceOf 关键字判断。
java.util.Date 类是什么?有哪些常用方法?
java.util.Date 类 表示特定的瞬间,精确到毫秒。
public long getTime():把日期对象转换成对应的时间毫秒值;
public void setTime(long time):把方法参数给定的毫秒值设置给日期对象
java.text.DateFormat 类是什么?有哪些常用方法??
java.text.DateFormat 是日期/时间格式化子类的抽象类,我们通过这个类可以帮我们完成日期和文本之间的转换,也就是可以在Date对象与String对象之间进行来回转换。
public String format(Date date):将Date对象格式化为字符串。
public Date parse(String source):将字符串解析为Date对象。
java.math.BigDecimal 类的特点?
我们在使用浮点数类型参与运算时会出现精度问题,要解决这个问题,可以使用 java.math.BigDecimal 类。
java.math.BigDecimal 类提供了常用的加、减、乘、除操作,其中除操作如果除不尽,会抛出算数异常,可以在方法的参数中传递 RoundingMode 取舍模式。
包装类有哪些?什么是装箱和拆箱?
byte -> Byte
short -> Short
int -> Integer
long -> Long
float -> Float
double -> Double
char -> Character
boolean -> Boolean
装箱:从基本类型转换为对应的包装类对象;
拆箱:从包装类对象转换为对应的基本类型;
Collection 集合的常用方法有哪些?
public boolean add(E e):把给定的对象添加到当前集合中 。
public void clear():清空集合中所有的元素。
public boolean remove(E e):把给定的对象在当前集合中删除。
public boolean contains(Object obj):判断当前集合中是否包含给定的对象。
public boolean isEmpty():判断当前集合是否为空。
public int size():返回集合中元素的个数。
public Object[] toArray():把集合中的元素,存储到数组中
泛型的好处
1、将运行时期的ClassCastException,转移到了编译时期变成了编译失败。
2、避免了类型强转的麻烦。
常用数据结构及其特点?
栈:先进后出
队列:先进先出
数组:增删慢、查询快
链表:增删快、查询慢
List 集合特点?
java.util.List 接口继承自 Collection 接口,是单列集合的一个重要分支,习惯性地会将实现了 List 接口的对象称为 List 集合。在 List 集合中允许出现重复的元素,所有的元素是以一种线性方式进行存储的,在程序中可以通过索引来访问集合中的指定元素。另外,List 集合还有一个特点就是元素有序,即元素的存入顺序和取出顺序一致。
什么是可变参数,有哪些注意事项?
Java 支持 “数据类型… 变量名” 形式的可变参数,允许传递参数时传递多个同类型的参数或传递一个数组,可变参数在使用时与数组无异。
一个方法只能有一个可变参数,可变参数必须处于参数列表的末尾。
HashSet 集合的特点?
java.util.HashSet 是 Set 接口的一个实现类,它所存储的元素是不可重复的,并且元素都是无序的(即存取顺序不能保证不一致)。java.util.HashSet 底层的实现其实是一个 java.util.HashMap 支持。
HashSet 底层采用数组+链表+红黑树实现。
TreeSet 集合特点?
java.util.TreeSet 集合是 Set 接口的一个实现类,底层依赖于 TreeMap,是一种基于红黑树的实现,其特点为:元素唯一、元素没有索引、使用元素的自然顺序对元素进行排序,或者根据创建 TreeSet 时提供的 Comparator 比较器进行排序。
有哪些常用的双列集合及其特点?
HashMap
LinkedHashMap
TreeMap
error 和 exception 的区别?
Error 类和 Exception 类的父类都是 Throwable 类,他们的区别如下。
Error 类一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢出等。对于这类
错误的导致的应用程序中断,仅靠程序本身无法恢复和和预防,遇到这样的错误,建议让程序终止。
Exception 类表示程序可以处理的异常,可以捕获且可能恢复。遇到这类异常,应该尽可能处理异常,使程序恢复
运行,而不应该随意终止异常。
Exception 类又分为运行时异常( Runtime Exception)和受检查的异常(Checked Exception ),运行时异
常;ArithmaticException,IllegalArgumentException,编译能通过,但是一运行就终止了,程序不会处理运行时异常,
出现这类异常,程序会终止。而受检查的异常,要么用 try。。。 catch 捕获,要么用 throws 字句声明抛出,交给它
的父类处理,否则编译不会通过。
异常的分类
按照异常需要处理的时机分为编译时异常(也叫强制性异常) 也叫 CheckedException 和运行时异常
(也叫非强制性异常) 也叫 RuntimeException。只有 java 语言提供了 Checked 异常, Java 认为 Checked
异常都是可以被处理的异常,所以 Java 程序必须显式处理 Checked 异常。如果程序没有处理 Checked 异
常,该程序在编译时就会发生错误无法编译。这体现了 Java 的设计哲学:没有完善错误处理的代码根本没有
机会被执行。对 Checked 异常处理方法有两种:
1 当前方法知道如何处理该异常,则用 try…catch 块来处理该异常。
2 当前方法不知道如何处理,则在定义该方法是声明抛出该异常
java 异常处理机制
Java 对异常进行了分类,不同类型的异常分别用不同的 Java 类表示,所有异常的根类为 java.lang.Throwable,
Throwable 下面又派生了两个子类: Error 和 Exception, Error 表示应用程序本身无法克服和恢复的一种严重问题。
Exception 表示程序还能够克服和恢复的问题,其中又分为系统异常和普通异常,系统异常是软件本身缺陷所导致的
问题,也就是软件开发人员考虑不周所导致的问题,软件使用者无法克服和恢复这种问题,但在这种问题下还可以让
软件系统继续运行或者让软件死掉,例如,数组脚本越界( ArrayIndexOutOfBoundsException),空指针异常
(NullPointerException)、类转换异常(ClassCastException);普通异常是运行环境的变化或异常所导致的问题,
是用户能够克服的问题,例如,网络断线,硬盘空间不够,发生这样的异常后,程序不应该死掉。
java 为系统异常和普通异常提供了不同的解决方案,编译器强制普通异常必须 try..catch 处理或用 throws 声明继
续抛给上层调用方法处理,所以普通异常也称为 checked 异常,而系统异常可以处理也可以不处理,所以,编译器不
强制用 try..catch 处理或用 throws 声明,所以系统异常也称为 unchecked 异常。
请写出你最常见的 5 个 RuntimeException
1) java.lang.NullPointerException 空指针异常;出现原因:调用了未经初始化的对象或者是不存在的对象。
2) java.lang.ClassNotFoundException 指定的类找不到;出现原因:类的名称和路径加载错误;通常都是程序
试图通过字符串来加载某个类时可能引发异常。
3) java.lang.NumberFormatException 字符串转换为数字异常;出现原因:字符型数据中包含非数字型字符。
4) java.lang.IndexOutOfBoundsException 数组角标越界异常,常见于操作数组对象时发生。
5) java.lang.IllegalArgumentException 方法传递参数错误。
6) java.lang.ClassCastException 数据类型转换异常
什么是进程和线程?
进程:有独立的内存空间,进程中的数据存放空间(堆空间和栈空间)是独立的,至少有一个线程。
线程:堆空间是共享的,栈空间是独立的,线程消耗的资源比进程小的多。
一个应用可以有一个或多个进程。一个进程中可以包含多个线程。
创建多线程的格式有几种?
创建多线程的方式有两种
方式一,通过定义一个类,继承Thread类,并在该类中重写run方法,创建该线程类的对象,并调用start方法,启动线程。
方式2,通过定义一个类,实现Runnable接口,创建该类的对象,创建一个Thread类对象,并将该类作为这个Thread类的参数,通过这个Thread对象启动线程。
扩展方式,以匿名内部类的方式,创建Runnable的子类对象,传入Thread类对象使用。
Thread和Runnable的使用区别?
Thread类的方式
子类一旦继承Thread类,就不能再继承其他类。
不适合资源共享。
线程对象不能接收Thread子类线程对象
Runnable接口方式
适合多个相同的程序代码的线程去共享同一个资源
可以避免java中的单继承的局限性
增加程序的健壮性,实现了解耦操作,在可以被多个线程共享的同事,使代码和线程独立。
线程对象只能接收Runable或Callable子类线程对象。
java中的线程执行调度方式是哪一种?
常见的线程调度方式有分时调度,抢占式调度
分时调度,指所有线程轮流使用 CPU 的使用权,平均分配每个线程占用 CPU 的时间。
抢占式调度指的是,优先让优先级高的线程使用 CPU,如果线程的优先级相同,那么会随机选择一个(线程随机性),Java使用的为抢占式调度。
在java中使用的是抢占式调度。
同步代码块、同步方法、静态同步的锁的区别?
同步代码块,可以传递一个自己定义的对象作为锁对象。
同步方法的锁为调用该方法的对象。
静态同步方法的锁为调用该方法的类的字节码文件对象
不同的同步锁,在解决线程多线程安全问题,使用的时候,需要确保使用的是同一把锁。
可见性问题的理解与解决?
可见性指,在内存中,当一个线程将一个共享变量修改,而其他使用访问这个变量的线程,可以读取到该变量的改变。可见性问题指没有能够读取到该线程的变化,叫做多线程的可见性问题。
想要解决可见性问题,需要确保读取该变量的线程,在每次读取的时候,都一定会重写获取该变量,及其变量的值。
解决办法有两种,
第1中使用volatile关键字,该方式推荐使用,一般专门用来解决可见性问题。
第2中,使用synchronized同步方式或Lock同步方式,这种方式的效率相对要低一些。
原子性问题的理解与解决?
原子性指两个或两个以上的多个操作步骤,要么执行期间完整执行,不被打断,要么不执行。原子性问题指执行过程被打断从而造成的多线程数据安全问题。
想要解决多线程原子性问题,需要确保每一个原子性操作的完整性。
解决办法有两种,
第1中是针对java中的变量在进行修改时的底层原子性的保证,可以使用利用CAS机制实现的原子类,这种方式保证原子性的同时,也能够解决效率问题。
第2中,是使用同步锁,这种方式可以针对任何的原子性问题进行解决。但是在效率上会有一定的印象。
什么是死锁?
死锁指的是存在同步代码快嵌套的多个线程对象,由于使用了多把锁,造成的线程之间互相等待。
死锁产生的条件有3个,1.有多把锁,2.有多个线程,3.有同步代码块嵌套。
什么是递归?
递归,就是在方法中调用该方法自己。
递归需要确定递归的规则和出口两个问题。
如果规则错误,就会导致计算结果错误。
如果出口存在问题,就会导致该方法,出现死循环,从而得不到想要的最终结果。
IO流的体系介绍?
IO流的体系从两个方向进行分类。
1.从流向分为 输入流和输出流
2.从类型分为 字节流和字符流
用语言描述IO流实现读写数据读写的过程?
创建输入流,指定读取路径
创建输出流,指定写入路径
定义字节(字符)数组
定义每次读取字节(字符)的个数变量
使用循环开始读取数据,将每次读取的内容放入数组,并返回每次读取的数据个数
在循环中,将每次读取到的数据,从该数组中写入到指定目录,每次从0索引开始写,按照新读取的个数写入数据。
结束循环后,关闭输入流、关闭输出流
请说明追加写入和换行的基本实现方式?
追加写入:使用输出流含有追加写入功能的构造方法,将第2位参数的变量值传入true,确保新指定的路径可以追加写入新的数据。
换行:在java中 使用”\r\n”代表windows系统换行,“\r”代表mac换行 “\n”代表linux换行,在需要使用换行的时候,讲对应数据后面追加对应系统的字符串即可。
解释什么是装饰着设计模式?举例具体的应用。
装饰着设计模式是将指定的类,利用新的类,对其进行封装,对该类中存在的功能进行提升或扩展。
从操作上,需要和要包装的类实现同样的接口,确保方法的一致性,然后将要包装的类作为成员变量传入包装类,并利用包装类的构造方法,给该变量进行赋值操作。
缓冲流、转换流、序列化流等都是包装基本流的类。
常见的IO流类有哪些?简述其功能。
文件字节流:对文件以字节的方式进行读和写的流
文件字符流:对文件以字符的方式进行读和写的流
缓冲流:包装了其他流对象的流,拥有读写速度更快的特点。字符输入缓冲流可以直接一次读取一行内容。
转换流:将字节流转换为字符流的流
序列化流:对java中定义的对象进行存储和读取的流
打印流:向指定路径写入内容的流
什么是序列化与反序列化?
序列化:将java中的对象写入到文件中,长久保存的操作
反序列化:将文件中利用序列化操作长久保存的对象,读取到内存中,重新变为对象的过程。
请描述对于字节流与字符流转化的桥梁这句话的理解。
在java中,一开始并没有字符流的概念,由于java使用的越来越多,对于大量的各国文字等等需要得到处理,使用自己流,在处理这些文本数据的时候,就显得不够灵活。
在java1.1的版本中加入了字符流,但是数据本身的处理仍然是依托于字节流的处理。所以想要得到字符流,就需要利用字节流得到字符流,因为,字符流需要用够构造方法传入字节流,由字节流负责底层操作。而这个负责转换的流叫做转换流。
因为我们称转换流是字节流与字符流的桥梁。
请说出什么是网络编程三要素?
IP:每一个IP代表了一台网络设备,每一台网络设备同时也只能使用一个IP地址。类似于电话的电话号码。
端口:每一个应用程序有一个在设备上有一个属于自己的端口号。在设备上,一个端口号,同时只能归属一个应用程序。端口号可以理解为是具体哪一个应用程序。
协议:协议指的是传输数据的方式,常见有TCP和UDP,TCP稳定安全,UDP传输快捷。
请解释什么是三次握手协议?
三次握手协议,是TCP协议访问网络的特有方式,该协议需要经过三次过程才能建立网络连接。
第1次,客户端访问服务器,服务器监听发现有客户端的访问。
第2次,服务器端给出回应,判断访问者的身份,给出连接通知。
第3次,客户端再次发出连接要求,与服务器建立数据通道,准备收发数据。
请简单描述NIO的组成。
分为缓冲区、通道、选择器
缓冲区,负责将数据进行存取到缓冲区中,真正的数据读写对象。
通道,用于将数据进行传输的工具。
选择器,用于管理通道的对象,能够协调通道资源,以非阻塞的方式提升运行效率。
请简单描述同步/异步,阻塞/非阻塞
同步,一条线程执行,其他线程就只能等待。
异步,一个线程执行,其他线程无需等待,照样可以执行。
阻塞,后续的任务,需要等待当前的任务执行完成,才能继续执行。
非阻塞,后续的任务,不需要等待当前任务执行完成,再执行
什么是反射?
Java反射就是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;并且能改变它的属性。
反射机制允许程序在运行时取得任何一个已知名称的class的内部信息,包括包括其modifiers(修饰符),fields(属性),methods(方法)等,并可于运行时改变fields内容或调用methods。那么我们便可以更灵活的编写代码,代码可以在运行时装配,无需在组件之间进行源代码链接,降低代码的耦合度;还有动态代理的实现等等;但是需要注意的是反射使用不当会造成很高的资源消耗!
什么是注解?
注解类型是一种特殊的接口类型,注解是注解类型的一个实例。 注解类型也有名称和成员,注解中包含的信息采用键值对形式,可以有0个或多个。
可以给Java包、类型(类、接口、枚举)、构造器、方法、域、参数和局部变量进行注解。
Java编译器可以根据指令来解释注解和放弃注解,或者将注解放到编译后的生成的class文件中,运行时可用。
什么是动态代理模式?
代理模式是常用的java设计模式,他的特征是代理类与委托类有同样的接口,代理类主要负责为委托类预处 理消息、过滤消息、把消息转发给委托类,以及事后处理消息等。
代理类与委托类之间通常会存在关联关系,一个代理类的对象与一个委托类的对象关联,代理类的 对象本身并不真正实现服务,而是通过调用委托类的对象的相关方法,来提 供特定的服务。
代理类可以分为两种 , 静态代理 、动态代理
静态代理:由程序员创建或特定工具自动生成源代码,再对其编译。在程序运行前,代理类的.class文件就已经存在了。
动态代理:在程序运行时,运用反射机制动态创建而成。
说一下你了解的jdk8的新特新。
Lambda表达式:匿名内部类的简写形式,要求使用的类型必须是函数式接口,才可以转化为Lambda表达式。
Stream流:结合Lambda表达式,操作集合和数组数据的链式操作。可以简化对于集合数据与数组数据的操作。
函数方法:针对Lambda表达式的进一步简化,当表达式中的操作可以用一个方法完成的时候,我们可以使用直接利用类名(对象)::方法名的形式,替代这个操作。
Base64加密:网络上最常见的用于传输8Bit字节码的编码方式之一。内置了三种BASE64编解码器
- 基本:最基本编码和解码方式。
- URL:表示对浏览器中的地址栏进行编码和解码。编码后对特殊字符有处理,比如编码后没有/ 这个字符
- MIME:编码后字符串每行最多76个字符
说明XML文档的约束分类。
DTD约束,是一种常规的用来约束Xml文件书写规则的约束语法,分为类中,本地,网络三种导入方式,按照标签嵌套层级、标签个数、标签主体数据3个方向对xml文件进行相应的常规约束。
schema约束是一种相对于DTD更为强大的Xml文件约束规则,编写复杂,多用于大型企业。可以利用明明空间在一个xml文件中导入多个schema约束。
什么是XML解析器,常见的XML文档解析工具有哪些?
XML解析器常见的分为3中,DOM,SAX,PULL
DOM是将整个XML加载到内存,解析成一个Document对象。好处是保留了结果,可以进行增删改查所有操作。但是会造成对内存的占用,XML过大,就会导致内存溢出。
SAX是逐行扫面的方式,按照设定的条件,一遍扫描一遍处理,这种方式节省了内存,处理速度快,可以处理较大的文件,确定是只能读取,不能回写。
简单介绍什么是xpath。
Xpath是一种对于Xml文件进行解析的扩展操作方式,利用路径的概念,快速设定想要查找符合路径语法的节点内容,既简化了操作,也更容易筛选想要的内容。
什么是正则表达式?
正则表达式就是用来验证各种字符串的规则,可以快速判断指定的字符串是否符合指定的语法规则。
常用语用户名密码的内容的注册登录等内容的输入验证。
介绍多列设计模式?
多例模式指的是,指让一个类只能创建指定个实例,且在使用的时候,只能从这些对象中获取其一。
什么是枚举?
枚举是一个实现了多例模式的类,可以表示固定个数的类型。
即用来表示某类事物的多种状态。
java中的引用类型有哪些?
Class:用来表示事物类型的描述方式的类型。
数组:用来存储数据的基本类型
接口:用来定义事物接口标准的类型
注解:用来对类中内容进行标记,且可以根据这些标记定义执行操作的类型。
枚举:用来针对类中不同状态,进行描述的类型。
什么是工厂设计模式?
工厂设计模式简单来说就是用来创建对象的。是 Java 中最常用的设计模式之一,属于创建型模式,特点是在实现解耦的同时,可以对同一类事物的不同子类的新建方案进行集中化管理,在提高可读性的同时,也简化了代码。
Request对象的主要方法有哪些?
- 操作请求行(获得客户机信息)
- getMethod(); 获得请求方式
- getRemoteAddr(); 获得客户机的IP地址
- getContextPath(); 获得项目的部署的路径
- getRequestURI(); 获得URI(不带http,主机,端口)
- getRequestURL(); 获得URL(带http,主机,端口)
2. 操作请求头
- getHeader(String name);
- User-Agent: 浏览器信息
- Referer:来自哪个网站(防盗链)如何取获得请求参数?
String getParameter(String name)
获得指定参数名对应的值。如果没有则返回null,如果有多个获得第一个。 例如:username=jack
String[] getParameterValues(String name)
获得指定参数名对应的所有的值。此方法专业为复选框提供的。 例如:hobby=抽烟&hobby=喝酒&hobby=敲代码
Map
获得所有的请求参数。key为参数名,value为key对应的所有的值。如何处理请求参数中文乱码?
- 为什么出现乱码?
编码和解码不一致, iso8859-1不支持中文
- 请求乱码解决
request.setCharacterEncoding(“utf-8”);响应中文乱码怎么解决?
response.setContentType(“text/html;charset=utf-8”);session的生命周期是什么
session存在于服务器的内存中,一个session域对象为一个用户浏览器服务session的生命周期是间隔的,
从创建时,开始计时如在20分钟,没有访问session,那么session生命周期被销毁。
但是,如果在20分钟内(如在第19分钟时)访问过session,
那么,将重新计算session的生命周期。关机会造成session生命周期的结束cookie的生命周期的分别是什么
cookie的生命周期是累计的,从创建时,
就开始计时,20分钟后,cookie生命周期结束;cookie常用方法有哪些?
- new Cookie(String name,String value); 创建Cookie
- response.addCookie(cookie); 把Cookie写给浏览器
- request.getCookies(); 获得所有的Cookie对象
- cookie.getName() 获得Cookie的key
- cookie.getValue() 获得Cookie的valuecookie的原理是什么是?
cookie采用的是客户端的会话状态的一种储存机制。
它是服务器在本地机器上存储的小段文本或者是内存中的一段数据,
并随每一个请求发送至同一个服务器。
JSP和Servlet有哪些相同点和不同点,他们之间的联系是什么?
JSP是Servlet技术的扩展,
本质上是Servlet的简易方式,更强调应用的外表表达。
JSP编译后是”类servlet”。Servlet和JSP最主要的不同点在于,
Servlet的应用逻辑是在Java文件中,
并且完全从表示层中的HTML里分离开来。
而JSP的情况是Java和HTML可以组合成一个扩展名为.jsp的文件。
JSP侧重于视图,Servlet主要用于控制逻辑。
JS中两种跳转方式分别是什么?有什么区别? ?
前者页面不会转向include所指的页面,只是显示该页的结果,主页面还是原来的页面。执行完后还会回来,相当于函数调用。并且可以带参数.后者完全转向新页面,不会再回来。
el的可以取值的对象是有哪些?
1、pageContext:代表pageContext对象 例如:${pageScope.name1}
2、pageScope:代表page域
3、requestScope:代表request域
4、sessionScope
5、applicationScoope
6、param:Map对象,保存了所有的请求参数
7、paramValues:Map对象(value对应一个数组).
8、header:Map对象。获取一个请求头的值 注意:如果头里面有“-” ,例Accept-Encoding,则要headerValues[“Accept-Encoding”]
9、headerValues:Map对象(value对应一个数组)
10、cookie:Map对象。(value对应一个cookie对象)
11、initParam:Map对象。(key=参数名value=参数值,此参数是在web.xml中配置的) 例如 ${initParam.encode }
mvc是什么概念
M是指业务模型,V是指用户界面,C则是控制器,使用MVC的目的是将M和V的实现代码分离,从而使同一个程序可以使用不同的表现形式。
如何使用过滤器,统一处理全网站中文乱码的问题
//1.强转两个参数
HttpServletRequest request = (HttpServletRequest) req;
HttpServletResponse response = (HttpServletResponse) resp;
//2.处理乱码
request.setCharacterEncoding(“utf-8”);
response.setContentType(“text/html;charset=utf-8”);
//3.放行
chain.doFilter(request, response);
过滤器映射路径的配置有哪几种?
- 完全路径匹配 以”/“开始
2. 目录匹配 以”/“开始 以 结束 .
3. 扩展名匹配 以”“开始 例如: .jsp .do
4. 缺省匹配 / 除了jsp以外的资源都匹配监听ServletContext对象的创建和销毁
- 创建一个类实现ServletContextListener接口
- 在web.xml配置如何让过滤器可以区分不同的访问资源的方式,有不同的拦截方式?
通过dispatcherTypes配置拦截方式
- DispatcherType.FORWARD: 【只】过滤转发
- DispatcherType.REQUEST: 除了转发以为其它的都过滤(1.浏览器的直接请求 2.重定向)【默认值】如何实现添加联系人?
- 新增联系人说白了就是向数据库里面插入一条记录
2. 思路
- 浏览器 点击提交 把数据提交到LinkManServlet(method=add, 联系人的基本信息)
- 在LinkManServlet创建add()方法
1.获得请求参数(联系人的基本信息), 封装成LinkMan对象
2.调用业务新增联系人
3.再查询所有展示【建议使用重定向】如何实现删除联系人?
- 浏览器点击了确定之后, 请求LinkManServlet, 携带method=delete,id
- 在LinkManServlet里面创建delete()方法
1.获得请求参数id
2.调用业务 根据id删除
3.再查询所有展示如何实现查询的数据进行分页显示
- 浏览器 点击 分页展示联系人 请求LinkManServlet 携带(method=findPage, curPage=1)
- 在LinkManServlet里面创建findPage()方法
1.获得请求参数 curPage
2.调用业务 获得分页的数据 PageBean
3.把pageBean存到request, 转发page_list.jsp页面展示分页查询的时候,如何操作数据库?
使用limit;
SELECT FROM linkman LIMIT a,b;
一, 解释limit
a: 从哪里开始查询 【a=(当前页码-1)b】
b: 每页条数(一页展示的数量) 【自定义的】
二, 例子 分页查询联系人, 一页展示5条
第一页 a=0 , b=5;
第二页 a=5 , b=5;
第三页 a=10 , b=5;JQ常用事件有哪些?
click(), focus(),blur(),change(),
submit(), keydown(), keyup(),mousexxx()val(),text(),html()三者在获取内容时候有什么区别
val()=获得元素value属性相应的值
text()=获得元素的文本内容
html()=获元素的标签体内容remove() 和empty() 在清空内容时候有什么区别
remove()删除指定元素,而 empty()清空指定元素的所有子元素keydown和keypress在使用时候有什么区别
keypress 事件与 keydown 事件类似。当按钮被按下时,会发生该事件。
它发生在当前获得焦点的元素上。
不过,与 keydown 事件不同,每插入一个字符,就会发生 keypress 事件。
注释:如果在文档元素上进行设置,则无论元素是否获得焦点,该事件都会发生ajax的TEXT和jason返回值类型的区别
TEXT:该方式返回的是拼接字符串,想要取到其中的值,需要先将返回值进行拆分
json:该方式返回的是数组,想要取到其中的值,可用索引项进行提取Ajax中POST和GET的区别
GET请求会将参数跟在URL后进行传递,
而POST请求则是作为HTTP消息的实体内容发送给WEB服务器。
当然在Ajax请求中,这种区别对用户是不可见的。JackSon: json和java对象如何互相转换?
- java对象转json(导入jar)
- 创建ObjectMapper对象
- 调用writeValueAsString(Object obj)
- json转java对象(导入jar)
- java对象转成json
- JSON.toJsonString(Object obj)
2. json转成java对象
- JSON.parseObject(String json,Class clazz )介绍vue的生命周期
beforeCreate(创建前) 在数据观测和初始化事件还未开始
created(创建后) 完成数据观测,属性和方法的运算,初始化事件,$el属性还没有显示出来
beforeMount(载入前) 在挂载开始之前被调用,相关的render函数首次被调用。实例已完成以下的配置:编译模板,把data里面的数据和模板生成html。注意此时还没有挂载html到页面上。
mounted(载入后) 在el 被新创建的 vm.$el 替换,并挂载到实例上去之后调用。实例已完成以下的配置:用上面编译好的html内容替换el属性指向的DOM对象。完成模板中的html渲染到html页面中。此过程中进行ajax交互。
beforeUpdate(更新前) 在数据更新之前调用,发生在虚拟DOM重新渲染和打补丁之前。可以在该钩子中进一步地更改状态,不会触发附加的重渲染过程。
updated(更新后) 在由于数据更改导致的虚拟DOM重新渲染和打补丁之后调用。调用时,组件DOM已经更新,所以可以执行依赖于DOM的操作。然而在大多数情况下,应该避免在此期间更改状态,因为这可能会导致更新无限循环。该钩子在服务器端渲染期间不被调用。
beforeDestroy(销毁前) 在实例销毁之前调用。实例仍然完全可用。
destroyed(销毁后) 在实例销毁之后调用。调用后,所有的事件监听器会被移除,所有的子实例也会被销毁。该钩子在服务器端渲染期间不被调用。Vue实现数据双向绑定的原理
vue实现数据双向绑定主要是:采用数据劫持结合发布者-订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应监听回调。当把一个普通 Javascript 对象传给 Vue 实例来作为它的 data 选项时,Vue 将遍历它的属性,用 Object.defineProperty 将它们转为 getter/setter。用户看不到 getter/setter,但是在内部它们让 Vue 追踪依赖,在属性被访问和修改时通知变化。
vue的数据双向绑定 将MVVM作为数据绑定的入口,整合Observer,Compile和Watcher三者,通过Observer来监听自己的model的数据变化,通过Compile来解析编译模板指令(vue中是用来解析 {{}}),最终利用watcher搭起observer和Compile之间的通信桥梁,达到数据变化 —>视图更新;视图交互变化(input)—>数据model变更双向绑定效果。Linux系统的主要应用场景?
1.服务器系统 2.关键任务的应用 3,学术机构的高效能运算任务 4.嵌入式系统Linux 怎么关闭进程
通常用
ps 查看进程 PID ,用 kill 命令终止进程 。
ps
命令用于查看当前正在运行的进程。
grep 是搜索
例如: ps ef | grep java
表示查看所有进程里 CMD 是 java 的进程信息 。
ps aux | grep java
aux 显示所有状态
kill
命令用于终止进程 。
例如: kill 9 [PID]
9 表示强迫进程立即停止什么是Redis持久化?Redis有哪几种持久化方式?
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
Redis 提供了两种持久化方式:RDB(默认) 和AOF RDB:rdb是Redis DataBase缩写
功能核心函数rdbSave(生成RDB文件)和rdbLoad(从文件加载内存)两个函数 AOF:Aof是Append-only file缩写
每当执行服务器(定时)任务或者函数时flushAppendOnlyFile 函数都会被调用, 这个函数执行以下两个工作
aof写入保存:
WRITE:根据条件,将 aof_buf 中的缓存写入到 AOF 文件
SAVE:根据条件,调用 fsync 或 fdatasync 函数,将 AOF 文件保存到磁盘中。
存储结构:
内容是redis通讯协议(RESP )格式的命令文本存储。 比较:
1、aof文件比rdb更新频率高,优先使用aof还原数据。
2、aof比rdb更安全也更大
3、rdb性能比aof好
4、如果两个都配了优先加载AOFReids的特点
Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过 10万次读写操作,是已知性
能最快的Key-Value DB。
Redis的出色之处不仅仅是性能,Redis最大的魅力是支持保存多种数据结构,此外单个value的最大限制是1GB,不像 memcached只能保存1MB的数据,因此Redis可以用来实现很多有用的功能,比方说用他的List来做FIFO双向链表,实现一个轻量级的高性 能消
息队列服务,用他的Set可以做高性能的tag系统等等。另外Redis也可以对存入的Key-Value设置expire时间,因此也可以被当作一 个功能加强版的memcached来用。
Redis的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。maven管理项目生命周期的命令有哪些
- clean 清理 2. compile 编译 3. test 执行测试 4. package 打包 5. install 安装 6. deploy 发布
maven的坐标含义
groupId 组织名 artifactId 项目名 version版本号 packaging :定义Maven项目打包的方式,使用构件的什么包。 classifier: 该元素用来帮助定义构建输出的一些附件。Mybatis 的编程步骤是什么样的?
1
、创建 SqlSessionFactory
2
、通过 SqlSessionFactory 创建 SqlSession
3
、通过 sqlsession 执行数据库操作
4
、调用 session.commit() 提交事务
5
、调用 session.close() 关闭会话JDBC 编程有哪些不足之处, MyBatis 是如何解决这些问题的?
1.
数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库链接池可解决此问题。
解决:在
SqlMapConfig.xml 中配置数据链接池,使用连接池管理数据库链接。
2. Sql
语句写在代码中造成代码不易维护,实际应用 sql 变化的可能较大, sql 变动需要改变 java 代码。
解决:将
Sql 语句配置在 XXXXmapper.xml 文件中与 java 代码分离。
3.
向 sql 语句传参数麻烦,因为 sql 语句的 where 条件不一定,可能多也可能少,占位符需要和参数一一对应。
解决:
Mybatis 自动将 java 对象映射至 sql 语句。
4.
对结果集解析麻烦, sql 变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成 pojo 对象解
析比较方便。Mybatis 中一级缓存与二级缓存?
- 一级缓存 : 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session ,当 Session flush 或
close 之后,该 Session 中的所有 Cache 就将清空。
2. 二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache HashMap 存储,不同在于其存储作用域为
Mapper(Namespace) Namespace),并且可自定义存储源,如 Ehcache 。作用域为 namespance 是指对该 namespance 对应的
配置文件中所有的 select 操作结果都缓存,这样不同线程之间就可以共用二级缓存。启动二级缓存:在 mapper 配置
文件中: :二级缓存可以设置返回的缓存对象策略:
:<cache readOnly=” 。当 readOnly=”true” 时,表示二级缓存返
回给所有调用者同一个缓存对象实例,调用者可以 updat e 获取的缓存实例,但是这样可能会造成其他调用者出现数
据不一致的情况(因为所有调用者调用的是同一个实例)。当 readOnly=”false” 时,返回给调用者的是二级缓存总缓
存对象的拷贝,即不同调用者获取的是缓存对象不同的实例,这样调用者对各自的缓存对象的修改不会影响到其他的
调用者,即是安全的,所以默认是 readOnly=”false”;
3. 对于缓存数据更新机制,当某一个作用域 一级缓存 Session/ 二级缓存 Namespaces) 的进行了 C/U/D 操作后,
默认该作用域下所有 select 中的缓存将被 clear 。说一说mybatis底层所使用的设计模式有哪些
1.构造者模式:
构造者模式是在mybatis初始化mapper映射文件的过程中,为节点创建Cache对象的方式就是构造者模式。其中CacheBilder为建造者角色,Cache对象是产品角色
2 装饰器模式
Cache接口的实现有多个,但是大部分都是装饰器,只有PerpetualCache提供了Cache接口的基本实现,其他的装饰器都是在PerpetualCache的基础上提供了一些额外的功能,通过各种组合后满足一个特定的需求。
3 工厂方法模式
mybatis中DataSource的创建使用了工厂方法模式,那么有哪些类在该模式中扮演了哪些角色呢?
工厂接口(Factory):DataSourceFactory扮演工厂接口角色
具体工厂类(ConcreteFactory):UnpooledDataSourceFactory和PooledDataSourceFactory
产品接口角色(Product):java.sql.DataSource
具体产品类角色(ConcreteFactory):UnpooledDataSource和PooledDataSource
4 动态代理 用于创建Mapper的代理对象ElementUI的表单组件怎么使用?它有哪些属性?
先写el-form组件,里面写el-form-item用来放输入框,例如用户名和密码那些。
属性:
一、el-from属性有ref、rules、绑定:model
二、el-form-item属性有prop用来定义一个该输入框对应的验证规则ElementUI的表格组件怎么使用?它有哪些属性?
用一个< /el-table>这个是最外面的上面,里面用 。
属性:
一、el-table组件的data是用来获取数据;
二、每一行el-table-row的数据通过prop属性。基础题库新增的流程介绍
1.初始化学科列表、目录列表、标签列表
2.客户端向QuestionController提交题目的相关信息
3.保存题目信息
4.保存题干信息(题目选项信息)
5.保存标签信息图片上传的注意点
- 客户端的请求方式必须为post
2. 请求头中的”Content-Type”必须为”multipart/form-data;charse=UTF-8”
3.服务器端保存图片的名字要是唯一的
4. 服务器端要将图片的存储路径保存到数据库登录与注册的流程分析
- 获取请求参数中的微信用户的信息
2. 根据用户的昵称判断当前用户是否已经注册
3. 如果没有注册则执行注册(将微信用户信息存入数据库)
4. 封装响应结果响应给客户端微信小程序的代码结构介绍
小程序包含一个描述整体程序的 app 和多个描述各自页面的 page,一个小程序主体部分由三个文件组成,必须放在项目的根目录,包含app.js、app.json、app.wxss; 一个小程序页面(page)由四个文件组成,分别是js(页面逻辑)、wxml(页面结构)、json(静态数据配置)、wxss(页面样式)题库分类列表展示的流程介绍
- 客户端向服务器端提交分类类型categoryKind并且在请求头中携带当前用户的标示(openId)
2. CategoryController中获取categoryKind、openId
3. 根据openId获取当前用户的信息
4. 调用业务层的方法根据cityId、categoryKind、memberId获取题库分类列表
5. 在业务层判断categoryKind,分别按照学科、企业、行业方向进行查询题目详情信息展示的流程
- 客户端向服务器端携带categoryKind以及请求头中的openId
2.CategoryController中获取请求参数,并且调用业务层的方法获取题目详情列表
3.业务层判断categoryKind,分别根据学科、公司、行业获取分类题目详情列表nginx的简介和作用
Nginx(engine x)是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。Nginx是由伊戈尔·赛索耶夫为俄罗斯访问量第二的Rambler.ru站点(俄文:Рамблер)开发的,第一个公开版本0.1.0发布于2004年10月4日。因它的稳定性、丰富的功能集、示例配置文件和低系统资源的消耗而闻名,其特点是占有内存少,并发能力强,事实上nginx的并发能力确实在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。
Nginx的作用:
1.可以处理静态资源
2.Nginx是反向代理服务器,实现负载均衡
3.Nginx也是电子邮件(IMAP/POP3)代理服务器,能够代理收发电子邮件反向代理的介绍
反向代理(Reverse Proxy)方式是指以==代理服务器来接受internet上的连接请求==,==然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端==,此时代理服务器对外就表现为一个服务器。
反向代理的作用:
1. 保证内网的安全,可以使用反向代理提供防火墙(WAF)功能,阻止web攻击。大型网站,通常将反向代理作为公网访问地址,Web服务器是内网。
2.负载均衡,通过反向代理服务器来优化网站的负载。当大量客户端请求代理服务器时,反向代理可以集中分发不同用户请求给不同的web服务器进行处理请求。谈谈Spring的IoC
IoC:Inversion of Control,控制反转。
是一种设计思想,表示把创建对象的控制权交给Spring框架,由原来自己主动创建对象 ,变成从Spring容器里被动接收一个对象
这种设计思想的目的,是为了减少入侵、实现松解耦,它底层采用了工厂模式,根据我们的配置生产bean对象,放到Spring容器中由Spring进行管理。当我们需要一个bean对象时,只需要从Spring容器中获取即可使用谈谈Spring的DI
DI:Dependency Injection,依赖注入。它是IoC思想的一种具体实现:
当我们有一个依赖时,不需要自己创建,只需要描述依赖之间的关系,由Spring框架负责从IoC容器中查找依赖并注入进来Spring中bean的作用域有哪些?
- singleton:默认作用域,是单例的。
一个Spring容器中,bean定义只有一个实例对象存在
在Spring容器初始化时就创建bean实例对象
在Spring容器销毁时,bean实例对象也销毁
2. prototype:多例的。
一个bean定义,可以有任意多个实例对象
在获取bean对象时创建实例对象;
创建后交给JVM进行管理,如果bean实例对象长时不使用,由JVM进行垃圾回收
3. request:请求域。每次HTTP请求有自己的一个bean实例对象,bean实例对象的生命周期和request生命周期相同
4. session:会话域。每个会话中有自己的一个bean实例对象。bean实例对象的生命周期和session的生命周期相同
5. application:应用域。每个ServletContext里有自己的一个bean实例对象;bean实例对象的生命周期和ServletContext的生命周期相同Spring的配置方式有哪些
1.XML配置:所有bean的定义、依赖等等全部在xml文件中进行配置。这种配置方式非常成熟,但是配置很麻烦
2.注解配置:Spring2.5提供了基于注解的配置。在类、方法、字段上使用注解声明bean、依赖等,而不使用XML。但是需要在XML中启用注解
3.JavaAPI配置:Spring3.0提供的,纯注解配置方式。在类、方法、字段上使用注解声明bean、依赖等,在Java类上使用@Configuration、@Bean、@Import、@DependsOn等新注解来定义程序外部的bean@Component, @Controller, @Service, @Repository注解有什么作用和区别
@Component:用于声明一个bean,是一个通用注解,Spring会把这个注解标记类进行扫描、创建bean实例对象放到IoC容器中
@Controller,@Service,@Repository是@Component的衍生注解,有相同的作用,只是更加的语义化
其中:
@Controller:通常用于表现层(web层)
@Service:通常用于业务层(service层)
@Repository:通常用于持久层(dao层)什么是AOP
AOP:Aspect-Oriented Programming,面向切面编程,是通过预编译方式(aspectj)或者运行期动态代理(Spring)实现程序功能的统一维护的技术。
AOP是OOP(面向对象编程)的技术延续,利用AOP可以实现对业务逻辑各个部分之间的隔离,从而使得业务逻辑各部分之间的耦合性降低,提高程序的可重用性,同时提高了开发效率。
AOP的本质是动态代理技术,Spring的AOP使用了两种动态代理技术:JDK提供的基于接口的动态代理,和cglib基于子类的动态代理请说明AOP中相关的概念
Target object:目标对象,要结合通知进行增强的对象
Proxy:代理对象。Spring框架通过jdk proxy或cglib生成的增强后的对象
JoinPoint:连接点。能够被拦截到的点,Spring里指目标对象中可以增强的方法
PointCut:切入点。要对哪些点进行切入增强,指要增强的连接点
Advice:通知。拦截到连接点后要做的事情,即进行功能增强的代码
Aspect:切面。是切入点和通知的结合
Weaving:织入,把切入点和通知进行结合,生成代理对象的过程Spring的AOP有哪些通知类型
before advice:前置通知。在切入点方法执行之前 执行的
afterReturning advice:后置通知。在切入点方法正常执行完毕后执行的
afterThrowing advice:异常通知。在切入点方法执行发生导演时执行的
after(finally) advice:最终通知。在切入点执行之后,无论是否有异常,都必定执行的
around advice:环绕通知。Spring中事务的隔离级别有哪些
TransactionDefinition.ISOLATION_READ_UNCOMMITTED:读未提交
最低的隔离级别,执行效率最高,但是存在脏读、不可重复读、幻读问题
TransactionDefinition.ISOLATION_READ_COMMITTED:读已提交
存在不可重复读、幻读问题
TransactionDefinition.ISOLATION_REPEATABLE_READ:重复读
存在幻读问题
TransactionDefinition.ISOLATION_SERIALIZABLE:串行化
最高的隔离级别,执行效率最低,但是不存在事件并发的问题
TransactionDefinition.ISOLATION_DEFAULT:
采用数据库默认的隔离级别。MySql默认是重复读;Oracle默认是读已提交Spring中事务传播行为有哪些
事务传播行为:当业务方法调用业务方法时,事务的处理方案
Spring的事务传播行为有7种:
TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。SpringMVC的执行流程
- 客户端发请求到前端控制器DispatcherServlet
2. 前端控制器DispatcherServlet:通过处理器映射器HandlerMapping查找控制器Handler
3. 处理器映射器HandlerMapping把控制器执行链返回给前端控制器DispatcherServlet
4. 前端控制器DispatcherServlet:通过处理器适配器HandlerAdapter调用控制器Handler
5. 处理器适配器HandlerAdapter把控制器执行结果ModelAndView返回给前端控制器DispatcherServlet
6. 前端控制器DispatcherServlet:通过视图解析器ViewResolver解析逻辑视图
7. 视图解析器ViewResolver把找到的物理视图View返回给前端控制器DispatcherServlet
8. 前端控制器DispatcherServlet渲染视图,把Model数据填充到物理视图View里
9. 前端控制器DispatcherServlet把最终渲染的结果返回给客户端SpringMVC常用注解有哪些
@Controller:控制器注解,加在表现层的类上,声明成为bean
@RequestMapping:用于配置请求映射信息
@RequestBody:用于获取HTTP请求体内容,绑定到控制器参数上。通常用于接收json格式的请求参数,封装成JavaBean对象
@ResponseBody:用于将控制器方法的返回值,直接作为响应体返回客户端。通常用于把方法返回的JavaBean转换成json格式,响应给客户端@RequestMapping注解的作用
@RequestMapping用于控制器类或方法上,用于声明控制器的请求映射信息
常用属性有:
value:用于配置请求路径
method:用于配置请求方式,符合要求的请求方式才能访问到
params:用于配置请求参数,符合要求的请求参数才能访问到如何解决请求参数乱码的问题
在web.xml中配置一个过滤器CharacterEncodingFilter,设置字符集为utf-8即可
characterEncodingFilter
org.springframework.web.filter.CharacterEncodingFilter
encoding
utf-8
characterEncodingFilter
/*
SpringMVC如何实现文件上传
1.添加jar依赖:commons-fileupload
2.配置视图解析器
3.页面表单要符合文件上传三要素:
表单提交方式为POST
要有文件选择框
表单的enctype值为multipart/form-data
4.控制器里使用MultipartFile接收文件数据SpringMVC的异常处理方案
持久层异常抛给业务层,业务层异常抛给表现层,表现层的异常统一由SpringMVC处理
SpringMVC提供了异常处理器,可以统一处理表现层的异常,使用方法:
1. 创建Java类,实现HandlerExceptionResolver,在其resolveException方法中处理异常信息
2. 在xml中配置异常处理器:把Java类配置成bean即可过滤器Filter和SpringMVC的拦截器的区别
- 使用范围不同:
过滤器Filter是Servlet规范提供的技术之一,在任意web应用中都可以使用
SpringMVC的拦截器,是SpringMVC框架提供的技术,只有使用了SpringMVC框架,才可以使用拦截器
2. 拦截范围不同:
过滤器Filter可以对任意资源进行拦截
拦截器Interceptor只能拦截对控制器的请求,不能拦截对JSP、js、HTML、css等等资源的请求
3. 拦截精度不同:
过滤器Filter只能拦截某个请求,对某一方法不能拦截
拦截器Interceptor可以拦截控制器里某一方法为什么要工程拆分?
项目中通常是分组分模块开发的,如果
不拆分系统,开发效率极其低下,问题很多。但是拆分系统之后,每个人就负责自己的一小部分就好了,分布式系统拆分之后,可以大幅度提升复杂系统的开发效率为什么用Git不用SVN?
- git是分布式的scm,svn是集中式的。(最核心)
2. git是每个历史版本都存储完整的文件,便于恢复,svn是存储差异文件,历史版本不可恢复。(核心)
3. git可离线完成大部分操作,svn则不能。
4. git有着更优雅的分支和合并实现。
5. git有着更强的撤销修改和修改历史版本的能力
6. git速度更快,效率更高。说一说Zookeeper数据结构?
a.文件系统的树形结构便于表达数据之间的层次关系。
b.文件系统的树形结构便于为不同的应用分配独立的命名空间(namespace)。
名称是由斜杠(/)分隔的一系列路径元素。ZooKeeper命名空间中的每个节点都由路径进行唯一标识。
ZooKeeper的层次命名空间与标准文件系统不同,ZooKeeper命名空间中的每个节点都可以具有与其关联的数据以及子节点。就像拥有一个文件系统一样,该文件系统也允许文件成为目录。每一个节点都可以存储数据,只是需要注意的是存储的容量是有限,一般不能超过 1MiB。zookeeper安装需要注意哪些?
1.安装目录不要出现中文和空格
2.安装目录中新建data目录
3.安装目录中需要将默认的配置文件zoo_saple.cfg复制一份zoo.cfg
4.修改zoo.cfg配置指定数据目录dataDir=../data目录(第二步创建的目录)Zookeeper中如何实现监听?
Curator引入了Cache的概念用来实现对ZooKeeper服务器端进行事件监听。Cache是Curator对事件监听的包装,其对事件的监听可以近似看做是一个本地缓存视图和远程ZooKeeper视图的对比过程。而且Curator会自动的再次监听,我们就不需要自己手动的重复监听了。
Curator中的cache共有三种
NodeCache(监听和缓存根节点变化)
PathChildrenCache(监听和缓存子节点变化)
TreeCache(监听和缓存根节点变化和子节点变化)zookeeper集群模式下,如何选举?
1.假设有三台服务器,服务器1(192.168.174.128),服务器2(192.168.174.129),服务器3(192.168.174.130)
2.假设服务器1先启动,投自己一票,其它服务器未启动,服务器1处理选举状态。
服务器2启动,投自己一票,同时和服务器1交换结果,由于服务器1和服务器2都将自己作为Leader服务器。服务器1和服务器2需要进行PK,优先检查ZXID(较大的作为Leader),如果ZXID相同,就比较myid(较大的作为Leader),由于服务器2的编号比服务器1的大,更新服务器1的投票为(2,0),将投票更新为服务器2。而服务器2不需要更新投票(因为投的票就是自己)
3.服务器3启动,进行统计后,判断是否有半数服务器收到相同的投票,对于对于1、2、3而言,已统计出集群中已经有3台机器接受了(3, 0)的投票信息,此时投票数正好大于半数,便认为已经选出了Leader,改变服务器状态。一旦确定了Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为FOLLOWING,如果是Leader,就变更为LEADING什么是RPC?
Remote Procedure Call 远程过程调用,是分布式架构的核心,按响应方式分如下两种:
同步调用:客户端调用服务方方法,等待直到服务方返回结果或者超时,再继续自己的操作。
异步调用:客户端把消息发送给中间件,不再等待服务端返回,直接继续自己的操作。
- 是一种进程间的通信方式
- 它允许应用程序调用网络上的另一个应用程序中的方法
- 对于服务的消费者而言,无需了解远程调用的底层细节,是透明的
需要注意的是RPC并不是一个具体的技术,而是指整个网络远程调用过程。
RPC是一个泛化的概念,严格来说一切远程过程调用手段都属于RPC范畴。各种开发语言都有自己的RPC框架。Java中的RPC框架比较多,广泛使用的有RMI、Hessian、Dubbo、spring Cloud等。RCP调用过程?
1、 服务调用方(client)调用以本地调用方式调用服务;
2、 client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体
在Java里就是序列化的过程
3、 client stub找到服务地址,并将消息通过网络发送到服务端;
4、 server stub收到消息后进行解码,在Java里就是反序列化的过程;
5、 server stub根据解码结果调用本地的服务;
6、 本地服务执行处理逻辑;
7、 本地服务将结果返回给server stub;
8、 server stub将返回结果打包成消息,Java里的序列化;
9、 server stub将打包后的消息通过网络并发送至消费方;
10、 client stub接收到消息,并进行解码, Java里的反序列化;
11、 服务调用方(client)得到最终结果。dubbo架构调用流程?
- 服务容器负责启动,加载,运行服务提供者。
2. 服务提供者在启动时,向注册中心注册自己提供的服务。
3. 服务消费者在启动时,向注册中心订阅自己所需的服务。
4. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
5. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
6. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。dubbo中负载均衡策略有哪些?
Dubbo 提供了多种均衡策略(包括随机random、轮询roundrobin、最少活跃调用数leastactive),缺省【默认】为random随机调用
配置负载均衡策略,既可以在服务提供者一方配置(@Service(loadbalance = “roundrobin”)),也可以在服务消费者一方配置(@Reference(loadbalance = “roundrobin”)),两者取一
- 如下在服务消费者指定负载均衡策略,可在@Reference添加@Reference(loadbalance = “roundrobin”)
@RestController
@RequestMapping(“/user”)
public class UserController {
@Reference(loadbalance = “roundrobin”)
private UserSerivce userService;传智健康这个项目有哪些模块?
- 会员管理
2. 预约管理
3. 健康评估
4. 健康干预
5. 在线预约
6. 体检报告传智健康使用了哪些技术架构?
使用SSM做基础构架,再配以Zookeeper作为注册中心,Dubbo做RPC远程调用,SpringSecurity做安全校验,使用Apache POI做数据/报表导入导出。使用阿云的大于短信来发送验证码,七牛用于分布式图片的存储,结合微信公众号实现移动端开发说一说项目工程的结构
health_parent父工程做依赖版本管理
1. health_common 做公共封装与工具类封装,同时引入所有依赖
2. health_pojo 为数据模型层,主要做数据库操作的实体
3. health_dao 为数据操作层, 使用mybatis做数据的操作
4. health_interface 为接口封装层
5. health_service 为具体业务实现层
6. health_web为系统后台管理模块说一说项目工程各模块间的关系
health_web依赖于health_interface
health_service依赖于health_interface 与health_dao
health_interface依赖于health_pojo
health_dao依赖于health_pojo
health_pojo依赖于health_common使用分页插件PageHelper需要哪些步骤?
- 引入分页插件依赖
2. 配置mybatis使用分页插件
3. PageHelper.startPage(pageNo,pageSize),紧接着的查询语句将被分页检查项能否直接删除?
不能。
1. 在企业开发中,是不能直接删除数据,而是通过更新状态的值为失效
2. 删除检查项时,要检查这个检查项是否被检查组使用了,如果被使用了就不能删除添加检查组需要操作哪些表?
- t_checkgroup 检查组信息表
2. t_checkgroup_checkitem检查组与检查项关系表添加检查组的业务服务中有哪些步骤?
- 调用dao保存检查组,通过select last_insert_id返回插入的主键
2. 获取新插入的检查组id
3. 遍历循环选中检查项id,调用dao添加检查组与检查项的关系说一说添加套餐的业务流程
- 绑定新建单击事件,弹出新建窗口,清空表单内容,默认选中第一个标签
2. 检查组列表信息展示
- 发送ajax
- 后端查询返回给前端 tableData
3. 上传图片并预览
- 加入上传组件
- 后台接收上传的图片,调用QiNiuUtil上传到七牛云存储上
- 图片预览
4. 提交表单
- 前端绑定事件,发送ajax 表单formData内容,选中的检查组id checkgroupIds,提示操作的结果
- 后端:
- controller 调用service
- service调用Dao
- 添加套餐 t_package, 返回主键
- 设置套餐与检查组的关系 t_package_checkgroup
- Dao与映射文件
- 添加方法
- 设置关系的方法Quartz的执行流程
- Spring容器启动时会创建Scheduler对象,trigger,jobdetail, job
2. 将trigger与jobdetail进行绑定并存入scheduler中
3. scheduler随着系统时间运行到某一刻时,时间刚才符合trigger的表达式
这时就会触发 这个触发器
4. 触发器触发后就去找对应的jobdetail
5. Jobdetal就会去调用spring容器中的那个job(任务类)的方法使用redis做清理七牛上垃圾图片的思路
- 使用redis的set数据类型分别存储所有上传到七牛上的图片名称
2. 使用redis的set数据类型存储所有保存到数据库的图片名称
3. 使用redis的set数据的sdiff命令,计算所有图片减去数据库图片
得出需要七牛上需要删除的图片名
4. 调用七牛api删除七牛上的图片
5. 清空redis两个set数据POI写excel的步骤有哪些?
1.创建工作簿对象
2.创建工作表对象
3.创建行对象
4.创建列(单元格)对象, 设置内容
5.通过输出流将workbook对象保存到磁盘简要说一下批量导入预约设置信息操作过程?
1、点击模板下载按钮下载Excel模板文件
2、将预约设置信息录入到模板文件中
3、点击上传文件按钮将录入完信息的模板文件上传到服务器
4、通过POI读取上传文件的数据,对不存在的进行添加,对已经存在的进行更新操作移动端开发方式有哪些?
- 基于手机API开发: 原生App
- 优点: 用户体验特别好, 调用手机硬件方便。获取系统权限,获取个人隐私 开发商
- 缺点: 不跨平台, 每一个系统都需要独立开发,浪费成本,每次重新,都要下载新软件,浪费流量. CS
2. 基于手机浏览器开发 : webApp B/S
- 优点: 跨平台, 只需要开发一套,节约成本, 服务器更新时客户端不需要更新,都有内置浏览。
- 缺点: 用户体验不是特别好, 调用手机硬件不方便。无法获取更新的系统权限及个人信息
3. 混合开发: 原生+ webApp
框架底层:APP 获取更多的系统信息与个人信息….
页面展示 :WebApp, B/S说一说使用发送验证码的操作步骤
- 发送验证码, 获取手机号码, 点击【发送验证码】绑定事件,发送ajax请求,提交手机号码给ValidateCodeController
2. Controller,接收手机号码(字符串)
- 判断这个手机号码是否已经发送过验证码了? 通过手机号码从redis获取对应的验证码,有值就代表着发送过了,没值意味着没有发送过或验证码已失效
- 如果没有发送过 生成验证码 调用SmsUtils发送验证码 存入redis记录一下这个手机号码发送的验证码, 5-15分钟的有效期
- 发送过了,返回提示:验证码已经发送过了,请注意查收。说一说提交体检预约的操作步骤
- 验证手机的验证码的有效性
提交过来的验证码与redis中存在的验证相同时就通过
其它情况则不通过
redis中没有这个手机号码的验证码
redis中的验证码与提交过来的验证不一致
通过则调用业务服务
返回订单的id给前端,进行预约成功页面展示
体检预约的操作步骤
1. 判断是否为会员, 通过手机号码查询,
存在则已为会员,
2. 不存在 不是会员
添加会员
插入t_member 产生会员id
filenumber 不知道 null 档案号
name 前端来
sex 前端来
idCard 前端来
phoneNumber 前端来
regTime 注册时间 当前系统时间
password 不知道, 后续用户登陆系统时再完善
email 不知道, 后续用户登陆系统时再完善
birthday 不知道, 后续用户登陆系统时再完善
remark 标记
取得会员id-》插入订单使用
3. 判断是否重复预约 通过会员id,预约日期,套餐id
预约过了则要报错
没预约过,则继续预约
4. t_ordersetting 表 预约设置表 后台管理人员
判断预约信息是否存在 通过预约日期查询
不存在:
报错 所选日期不能预约
存在:
判断number<=reservations
已满
报错 所选日期已经预约满了,请重新选择另一个日期
未满:
可预约,
通过日期更新已预约人数+1
5. t_order 表
插入记录
id 自增
member_id 不知道,从t_member来 手机 用户 从会员表的操作中就可以获取
orderDate 预约体检日期,从前端中来
orderType 预约的类型 可以写死 health_mobile 接收的预约就是 微信预约
如果是health_web接收的就是 电话预约
orderStatus 体检/订单状态 未到诊
setmeal_id 预约的套餐id 从前端中来Spring Security入门案例有哪些步骤?
- 创建Maven工程, 添加坐标
2. 配置web.xml(前端控制器,springSecurity权限相关的过滤器 DelegatingFilterProxy, 过滤器的名称不能修改,一定是springSecurityFilterChain)
3. 创建spring-security.xml(security:http 自动配置,使用表达式的方式完成授权,只要具有ROLE_ADMIN的角色权限才能访问系统中的所有功能; 授权管理器,指定用户名admin,密码{noop}admin,具有ROLE_ADMIN的角色权限)什么是认证与授权?
- 认证: 提供账号和密码进行登录认证, 系统知道你的身份
- 授权: 根据不同的身份, 赋予不同的权限,不同的权限,可访问系统不同的功能说一说springboot大体的使用步骤
1.添加parent
2.添加起步依赖
3.创建一个启动类
4.添加main方法加入注解@springbootapplication即可说一说springboot控制版本的原理
由继承的springboot的parent来统一控制,
springboot-parent中统一控制了所有的需要用到的版本
在使用中继承了parent意味着也同时控制了说一说springboot常用的注解
@springbootapplicatioin:
用于实现自动配置
@import 用于导入配置类进行自动配置
@OnClassCondition 用于判断当前spring容器中是否有某一个类存在,在自动配置中有重要的作用
@enableautoconfiguration:
用于启用自动配置类相关配置,让其生效rabbitmq的消息模式有哪些各自有哪些特点
模式如下:
简单模式:简单发送消息和接收消息
工作模式:发送消息由多个消费者来共同消费
路由模式:根据业务将业务根据路由key进行划分发送到不同的队列中进行消费
广播模式:根据业务将发送消息 并广播给所有的消费者进行消费
主题模式:根据业务规则将根据通配符的模式 发送消息,只有匹配了通配符规则的消费可以接收消息如何确保消息接收方消费了消息
接收方消息确认机制:消费者接收每一条消息后都必须进行确认(消息接收和消息确认是两个不同操作)。只有消 费者确认了消息,RabbitMQ才能安全地把消息从队列中删除。 这里并没有用到超时机制,RabbitMQ仅通过Consumer的连接中断来确认是否需要重新发送消息。也就是说,只要 连接不中断,RabbitMQ给了Consumer足够长的时间来处理消息。
深圳黑马javaee教研部
下面罗列几种特殊情况:
如果消费者接收到消息,在确认之前断开了连接或取消订阅,RabbitMQ会认为消息没有被分发,然后重新分 发给下一个订阅的消费者。(可能存在消息重复消费的隐患,需要根据bizId去重) 如果消费者接收到消息却没有确认消息,连接也未断开,则RabbitMQ认为该消费者繁忙,将不会给该消费者 分发更多的消息。说下eureka的架构流程
1.eureka有服务端和客户端
2.eureka的客户端注册给服务端 将自身的ip和端口以及服务名注册到服务端 并每隔30S进行续约
4.eureka的客户端注册给服务端,并每隔30S进行拉取服务列表到本地缓存,进行更新
5.eureka的客户端进行调用时,从本地缓存中获取服务列表进行调用
6.服务端每隔60S检测一次客户端服务列表是否存活,如果超过90S检测不到就会剔除掉服务列表(前提是关闭了自我保护机制)
7.eureka自我保护机制 ,如果在15分钟内超过85%的节 点都没有正常的心跳,并不会剔除服务列表。这样就很好的保证了可用。谈一谈 spring cloud openfeign
openfeign 是基于restTemplate实现微服务调用的组件,
他的特点就是利用动态代理产生代理类,
我们使用时候不需要实现,只需要声明即可,这样使用起来比restTempalte要优雅的多,
并且还集成了负载均衡,提高了开发效率。谈一谈网关gateway以及他的作用
网关用于统一处理一些日志,授权登录等等,由于微服务的数量众多,就必然导致跨域问题,端口问题,权限,日志的维护问题的不好处理,那么有网关之后,所有请求统一处理和管理即可。
网关的技术很多 gateway就是其中之一
主要的核心就是:路由 断言和过滤器
路由用于配置微服务的请求的转发规则。
断言用于判断转发的条件
过滤器用于配置和处理一些通用的过滤例如:日志,权限校验等elasticsearch是什么?有什么优点
es 是基于lucene开发的一款分布式海量数据存储的和搜索的搜索引擎。利用倒排索引机制,快速存储数据和检索式数据,并支持动态扩展,利用分布式的优点进行海量数据的存储和搜索。
优点:
1.搜索速度快
2.查询进准
3.支持PB级别数据
4.支持集群分布式 搭建容易简单elasticsearch的实现原理是什么
elasticsearch基于lucenece.利用了倒排索引结构实现快速检索。
具体包括两个主要流程:
1.建立倒排表的过程(分词存储) 通过分词器将数据进行分词让后将数据存储到ES中 并建立倒排索引表 内容和文档ID的映射关系
2.当检索时,通过词语,根据分词器进行从倒排索引表中进行检索查询出对应内容的文档ID 根据文档的ID获取数据即可如何实现高亮查询
高亮查询的本质就是就是将搜索到的词语进行修饰样式,所以再搜索的时候需要指定要高亮的字段,还需要设置高亮的前缀和后缀,另外查询的时候es会根据高亮的业务,将高亮数据存储到高亮的分类字段中。我们需要重新解析出高亮数据进行设置返回。
1.设置高亮字段
2.设置前缀和后缀
3.执行高亮查询获取到结果集 从结果集中获取高亮部分数据
4.将高亮部分数据截取出来存储并返回给前端说一说常用的查询以及各自的特性
1.匹配查询 匹配查询是先进行分词再查询
2.词条查询 不分词整体进行匹配的查询
3.范围查询 根据范围来进行查询
4.多字段匹配查询 根据多个字段 先分词再查询然后查询的数据合并之后返回
5.模糊查询 根据通配符进行模糊查询 比如:* ? 通配符
6.分页和排序
7.多条件组合查询 多条件组合查询是用的最多的就是在开发中有多种条件进行查询利用:
MUST MUST_NOT 和SHOULD建立条件类似于数据库中的and not和or的关系说说电商常见的模式
B2B、C2C、B2C、C2B、O2O、F2C、B2B2C简单聊聊电商行业技术特点
1、海量数据
2、业务复杂
3、技术范围广、新
4、分布式、高并发、高可用能够画出项目架构图
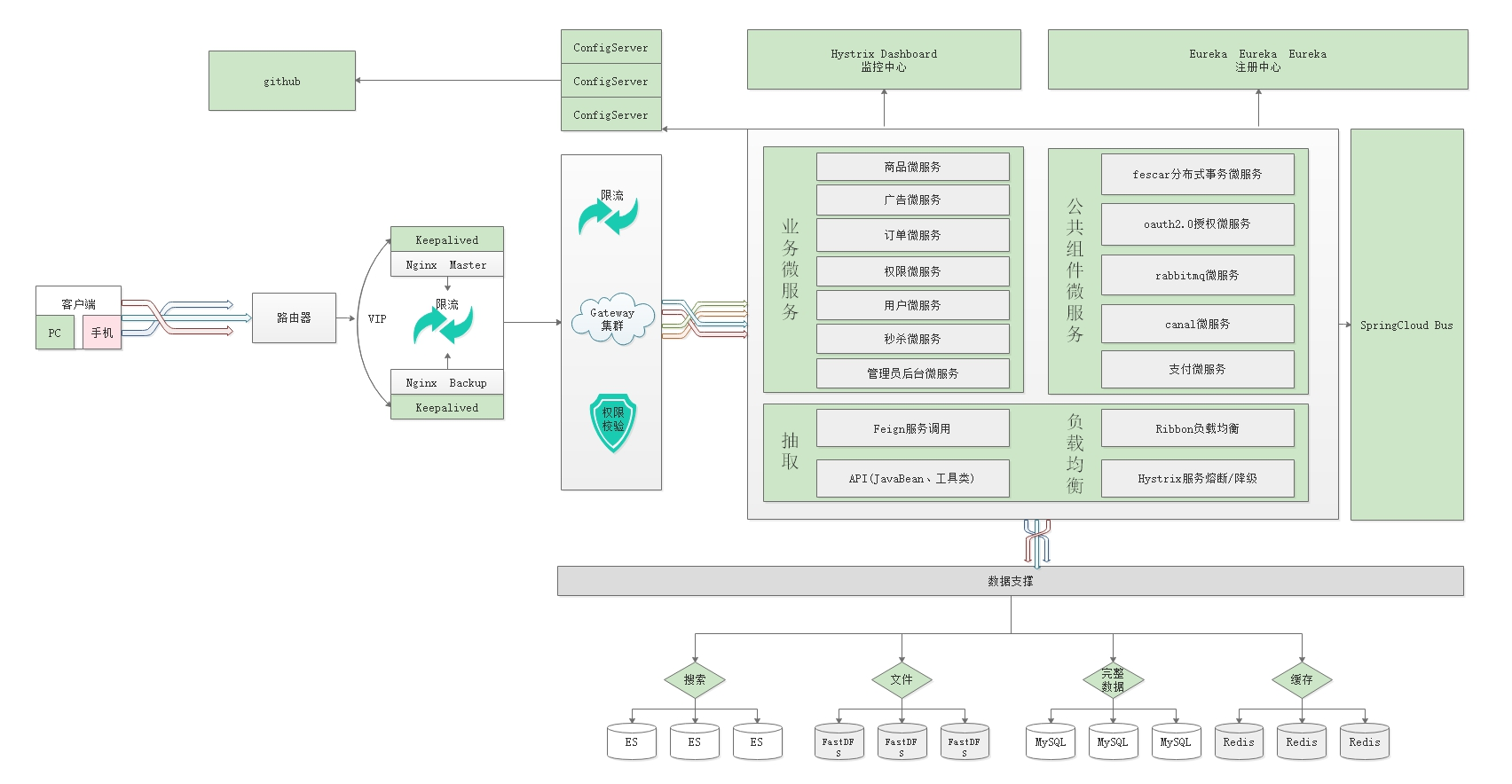
说说FastDFS相关术语以及作用
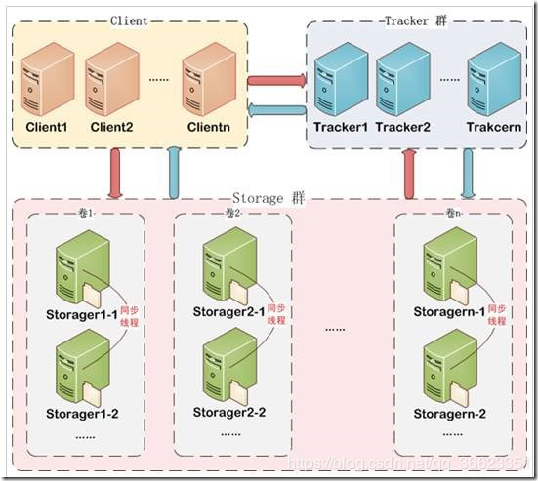
1、Client:客户端
2、Tracker Server:跟踪服务器,负载均衡作用
3、Storeage Server:存储服务器,存储资源
4、Meta Data:元数据,对附件添加的扩展信息说说FastDFS的运行原理(画图)
能够说出FastDFS的文件上传的代码步骤
1、初始化FastDFS配置文件并建立连接
2、创建跟踪服务器客户端TrackerClient3、获取跟踪服务器TrackerServer
4、创建存储服务器客户端StoreageClient
5、调用方法,完成附件上传说出SPU和SKU的概念并举例
SPU = Standard Product Unit (标准产品单位)SPU是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述了一个产品的特性。
例如:iPhone X 可以确定一个产品即为一个SPU。
SKU=Stock Keeping Unit(库存量单位), 可以是以件、盒、托盘等为单位。SKU是物理上不可分割的最小存货单元
例如:iPhone X 64G 银色 则是一个SKU。说出商品保存整个过程涉及到的表
1、tb_category:商品分类表
2、tb_category_brand:分类与品牌中间表
3、tb_template:商品模板表
4、tb_para:商品参数表
5、tb_spec:商品规格表
6、tb_album:商品图片表
7、tb_spu:商品表
8、tb_sku:库存表说出商品保存的代码实现的步骤
1、初始化商品分类数据
2、初始化品牌列表数据
3、初始化商品模板数据
4、初始化商品参数列表数据
5、初始化商品规格列表数据
6、SPU+SKU保存通过学习的lua语法,定义一个返回两个数的最大的函数(需要对所写语句进行说明)
function max(v1, v2)
if(v1 > v2)
then
result = v1
else
result = v2
end
return result
end能够说出前台系统广告的加载流程
1、用户发送请求首先加载本地缓存数据
2、如果本地没有数据,则从Redis服务中加载,并且将数据压入本地缓存中
3、如果Reids没有,则从数据库中查询,并且将数据写入Redis缓存中什么是限流以及nginx限流方式
限流:一般情况下,首页的并发量是比较大的,即使 有了多级缓存,当用户不停的刷新页面的时候,也是没有必要的,另外如果有恶意的请求 大量达到,也会对系统造成影响。而限流就是保护措施之一。
1、nginx控制速率
2、nginx控制并发量说出canal工作原理和实现广告同步过程
原理:
1、canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
2、mysql master收到dump请求,开始推送binary log给slave(也就是canal)
3、canal解析binary log对象(原始为byte流)
步骤:
1、搭建canal服务
2、编写监听器,监听数据库的变化
3、编写Feign接口,提供数据
4、在业务层,监听具体某个库的表数据,如果该表数据发送改变,则将数据写入Redis中说出ES中常见的过滤方式
1、term、terms过滤
2、range过滤
3、exists过滤
4、bool过滤说出数据导入索引库的代码步骤
1、编写Feign接口,获取sku列表数据
2、将sku导入索引库:
2.1 编写文档映射的Bean
2.2 Dao层代码编写(继承ElasticsearchRepository)
2.3 Service层代码编写
2.4 Controller层代码编写如何实现关键字检索(业务层代码)
1、将检索条件的方法单独抽取,然后通过NativeSearchQueryBuilder对象封装检索条件
2、通过elasticsearchTemplate模板对象调用queryForPage方法进行查询
3、获取到结果集对象AggregatedPage
4、对结果集进行处理,将该对象中的数据取出并且封装到Map中(商品列表、总页数、总条数)说出ES统计查询的步骤
1、设置分组条件
2、添加分组查询添加
3、执行检索
4、获取分组查询的结果集
5、获取分组数据
6、编写分组结果数据buckets
7、将结果封装到list中说出实现关键字高亮显示
1、指定高亮域,也就是设置哪个域需要高亮显示设置高亮域的时候,需要指定前缀和后缀,也就是关键词用什么html标签包裹,再给该标签样式
2、高亮搜索实现
3、将非高亮数据替换成高亮数据什么是Thymeleaf
Thymeleaf提供了一个用于整合Spring MVC的可选模块,在应用开发中,你可以使用Thymeleaf来完全代替JSP或其他模板引擎,如Velocity、FreeMarker等。
Thymeleaf的主要目标在于提供一种可被浏览器正确显示的、格式良好的模板创建方式,因此也可以用作静态建模。
你可以使用它创建经过验证的XML与HTML模板。相对于编写逻辑或代码,开发者只需将标签属性添加到模板中即可。
这些标签属性就会在DOM(文档对象模型)上执行预先制定好的逻辑。说出所学的thymeleaf的语法以及作用
1、th:action,指定from表请求地址
2、th:text,显示文本内容
3、th:each,进行遍历
4、th:if,逻辑判断
5、th:fragment,定义一个模块
6、th:include,引入其他模块说出回显商品列表数据思路
1、前端表单提交检索的关键字
2、后端根据关键字进行检索
3、将检索结果封装到Model域中
4、页面通过thymeleaf语法遍历输出数据
5、页面回显商品相关的数据说出网关的好处
1、安全 ,只有网关系统对外进行暴露,微服务可以隐藏在内网,通过防火墙保护。
2、易于监控。可以在网关收集监控数据并将其推送到外部系统进行分析。
3、易于认证。可以在网关上进行认证,然后再将请求转发到后端的微服务,而无须在每个微服务中进行认证。
4、减少了客户端与各个微服务之间的交互次数
5、易于统一授权什么是JWT以及它的组成部分
概念:JSON Web Token(JWT)是一个非常轻巧的规范。这个规范允许我们使用JWT在用户和服务器之间传递安全可靠的信息。
组成部分:
1、头部:头部用于描述关于该JWT的最基本的信息
2、载荷:载荷就是存放有效信息的地方
3、签证:这个部分需要base64加密后的header和base64加密后的payload使用.连接组成的字符串,然后通过header中声明的加密方式进行加盐secret组合加密说出鉴权的代码实现思路
1、用户通过访问微服务网关调用微服务,同时携带头文件信息
2、在微服务网关这里进行拦截,拦截后获取用户要访问的路径
3、识别用户访问的路径是否需要登录,如果需要,识别用户的身份是否能访问该路径[这里可以基于数据库设计一套权限]
4、如果需要权限访问,用户已经登录,则放行
5、如果需要权限访问,且用户未登录,则提示用户需要登录
6、用户通过网关访问用户微服务,进行登录验证
7、验证通过后,用户微服务会颁发一个令牌给网关,网关会将用户信息封装到头文件中,并响应用户
8、用户下次访问,携带头文件中的令牌信息即可识别是否登录什么是单点登录?
单点登录(Single Sign On),简称为 SSO,是目前比较流行的企业业务整合的解决方案之一。 SSO的定义是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。说说Oauth2.0认证流程,画面说明

Oauth2授权模式有几种?
1.授权码模式(Authorization Code)
2.隐式授权模式(Implicit)
3.密码模式(Resource Owner Password Credentials)
4.客户端模式(Client Credentials)介绍下非对称加密算法中的公钥与私钥(图解)
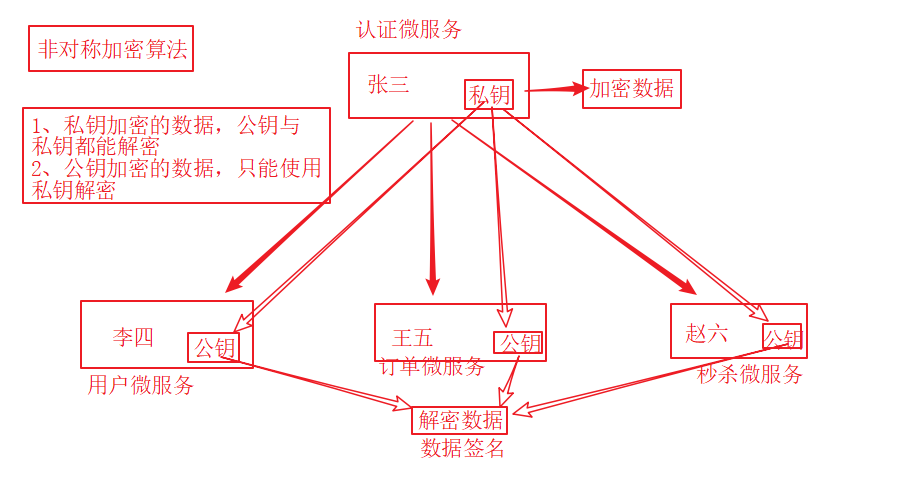
资源服务授权配置有哪些步骤?
1、添加spring-boot-starter-actuator依赖
2、配置公钥
3、配置Http请求路径安全控制与公钥读取OAuth认证微服务对接普通微服务?
1.用户登录成功后,会将令牌信息存入到cookie中(一般建议存入到头文件中)
2.用户携带Cookie中的令牌访问微服务网关
3.微服务网关先获取头文件中的令牌信息,如果Header中没有Authorization令牌信息,则取参数中找,参数中如果没有,则取Cookie中找Authorization,最后将令牌信息封装到Header中,并调用其他微服务
4.其他微服务会获取头文件中的Authorization令牌信息,然后匹配令牌数据是否能使用公钥解密,如果解密成功说明用户已登录,解密失败,说明用户未登录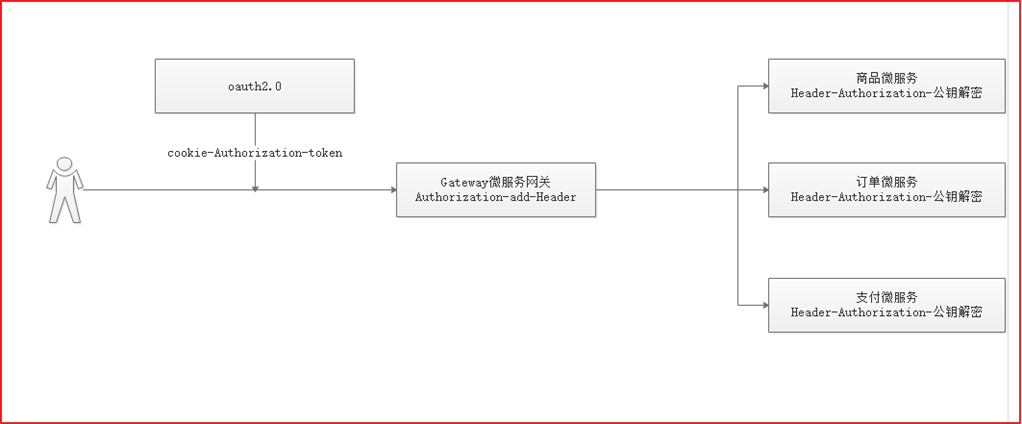
说明购物车的类型
购物车类型:2种
1.用户未登录和已登录都可以使用购物车
不登录,购物车数据存入到客户端(Cookie|WebSQL[H5])
已登录,可以存储到服务端(MySQL、Redis、MongoDB)
状态切换:用户未登录,商品加入购物车->登录(之前可以存着购物车数据),购物车合并
2.用户未登录不能使用购物车,已登录才能使用购物车
已登录,可以存储到服务端(MySQL、Redis、MongoDB)介绍下hystrix隔离模式
hystrix隔离模式目前有两种方式:信号量模式(SEMAPHORE)和线程池模式(THREAD)。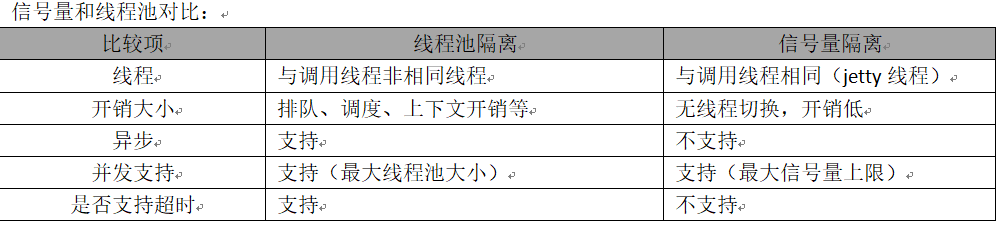
Oauth中如何保持登录会话?
1、用户登录后,我们将用户信息存入到Cookie中。
2、微服务网关将Cookie中的令牌取出,并添加到请求头中。
3、经过网关后,再继续访问其他微服务,可以获取到令牌信息。说说订单结算功能涉及的表。
tb_address 收件人列表
tb_order 订单信息
tb_order_item 订单购物明细
tb_sku 修改库存
tb_user 修改积分微信扫码支付申请流程有哪些?
第一步:注册公众号(类型须为:服务号)
请根据营业执照类型选择以下主体注册:个体工商户| 企业/公司| 政府| 媒体| 其他类型。
第二步:认证公众号
公众号认证后才可申请微信支付,认证费:300元/次。
第三步:提交资料申请微信支付
登录公众平台,点击左侧菜单【微信支付】,开始填写资料等待审核,审核时间为1-5个工作日内。
第四步:开户成功,登录商户平台进行验证
资料审核通过后,请登录联系人邮箱查收商户号和密码,并登录商户平台填写财付通备付金打的小额资金数额,完成账户验证。
第五步:在线签署协议
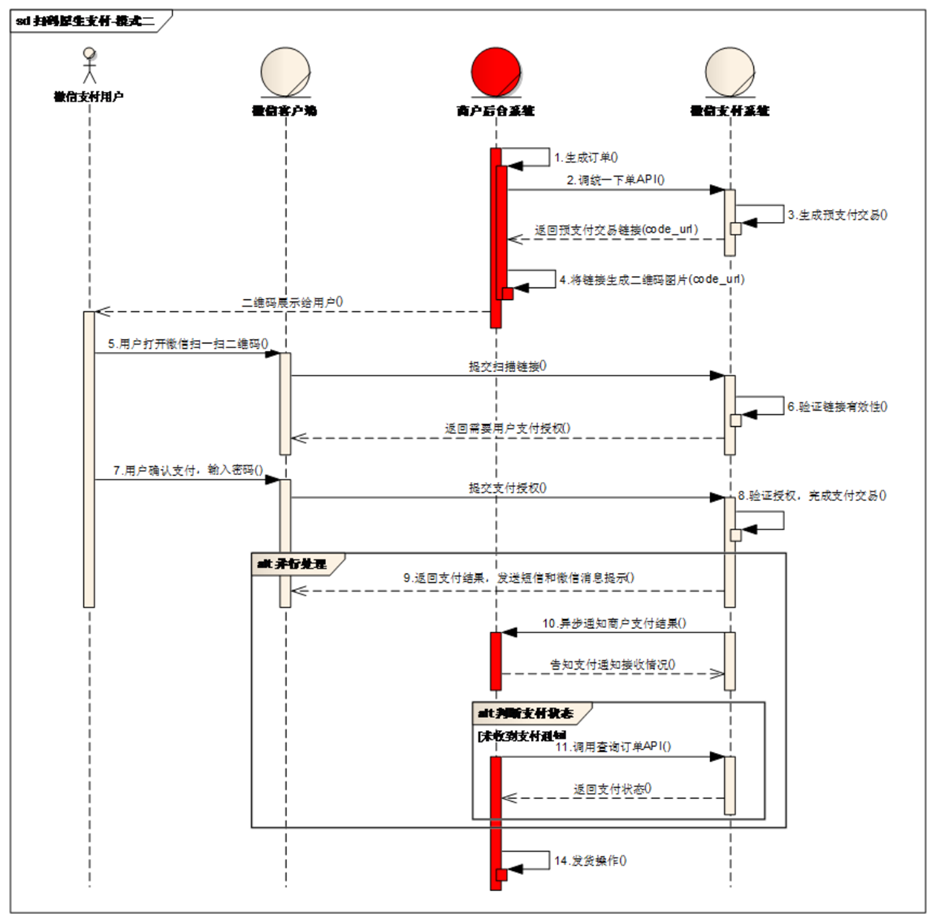
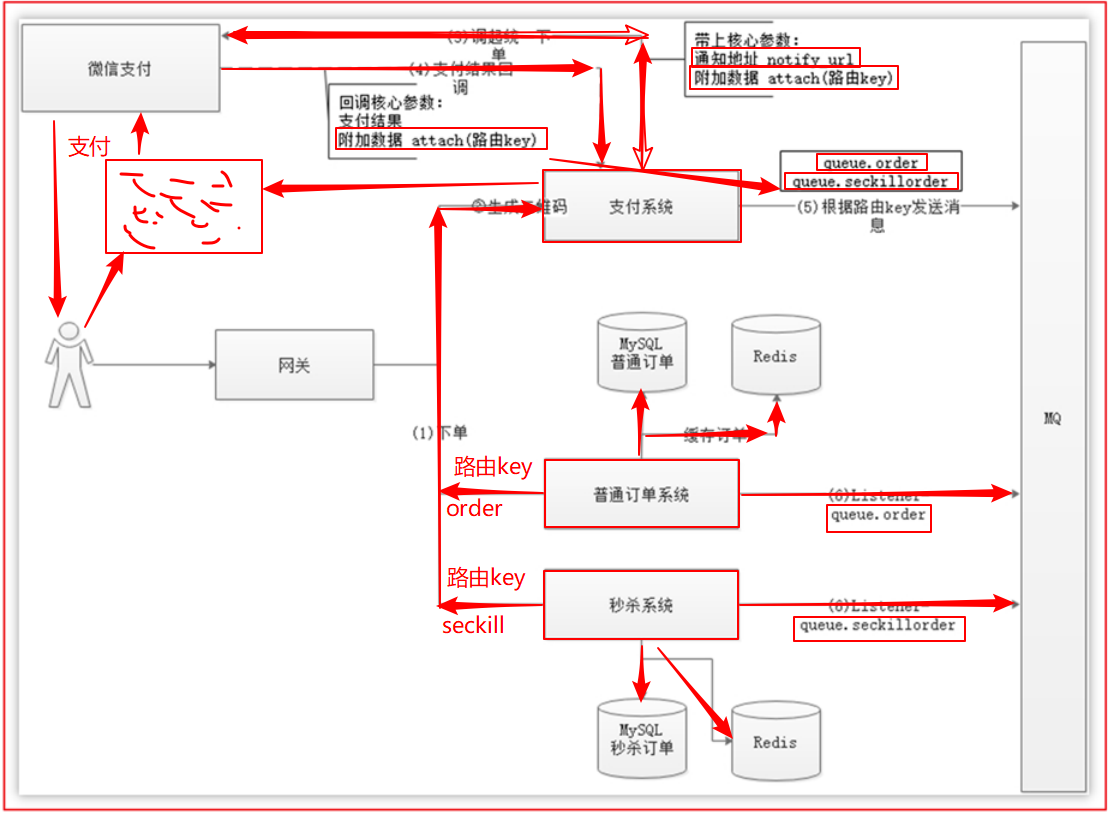
本协议为线上电子协议,签署后方可进行交易及资金结算,签署完立即生效。说说项目中使用的微信支付模式整体流程。
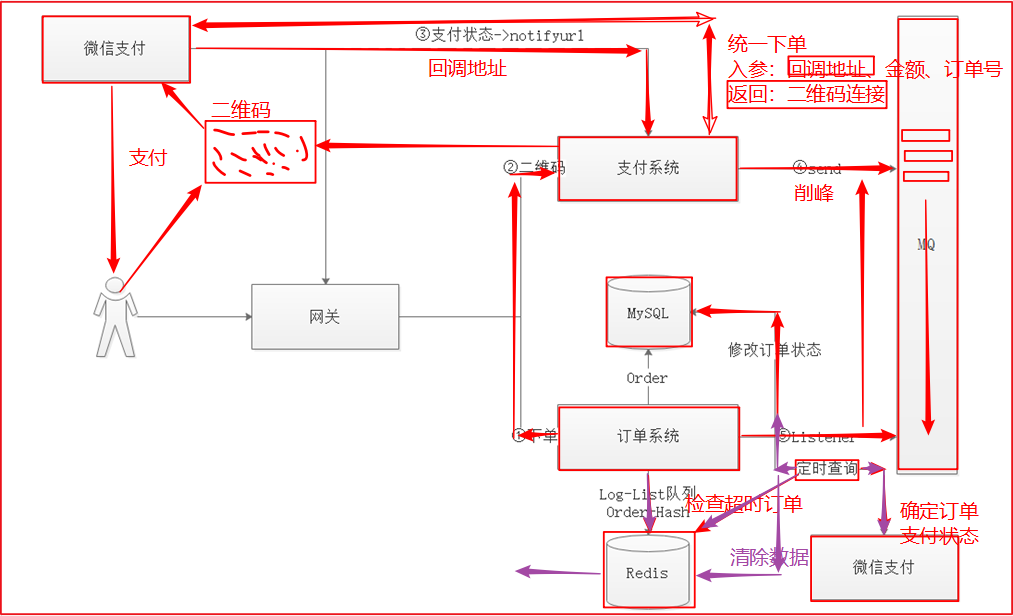
说明项目中整体如何对接微信支付,画图说明。
秒杀是什么?
所谓“秒杀”,就是网络卖家发布一些超低价格的商品,所有买家在同一时间网上抢购的一种销售方式。通俗一点讲就是网络商家为促销等目的组织的网上限时抢购活动。由于商品价格低廉,往往一上架就被抢购一空,有时只用一秒钟。
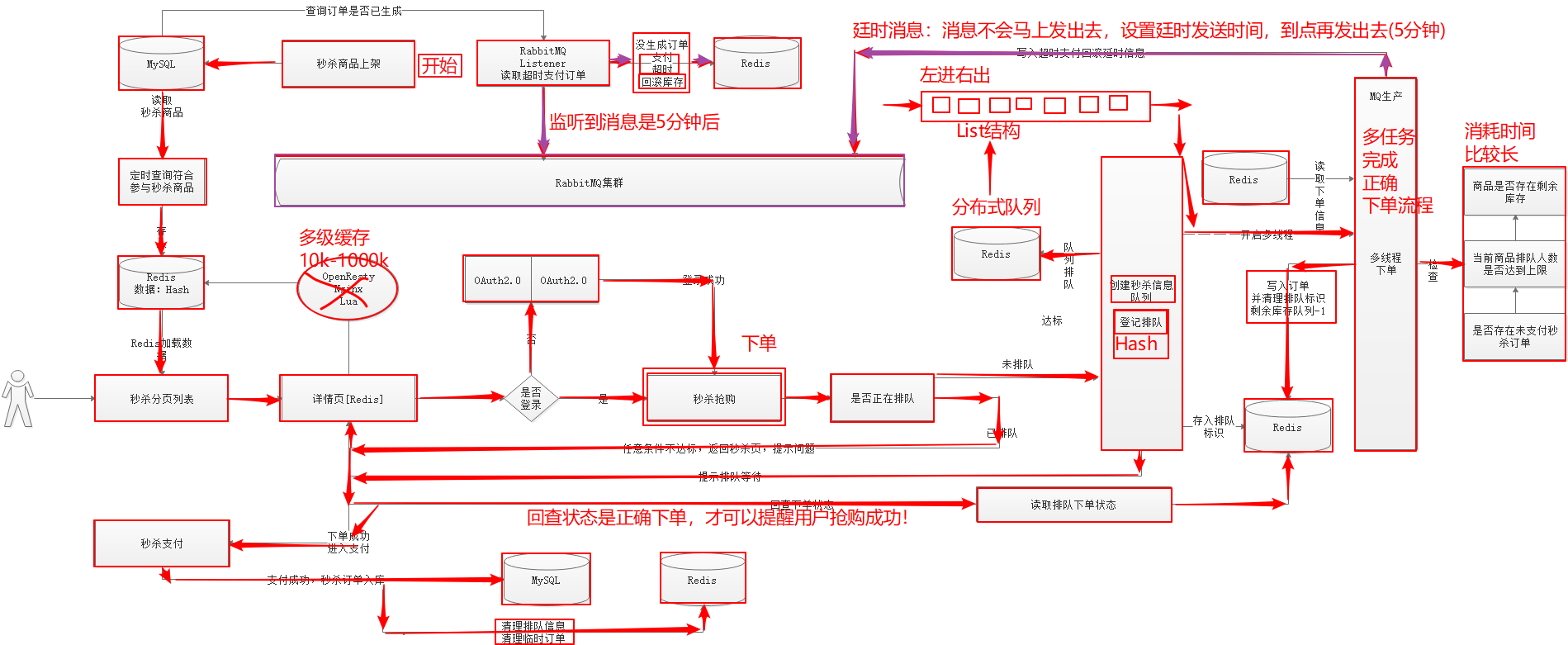
秒杀商品通常有两种限制:库存限制、时间限制。说说秒杀整体设计思路,画图说明。
秒杀中如何防止超卖?
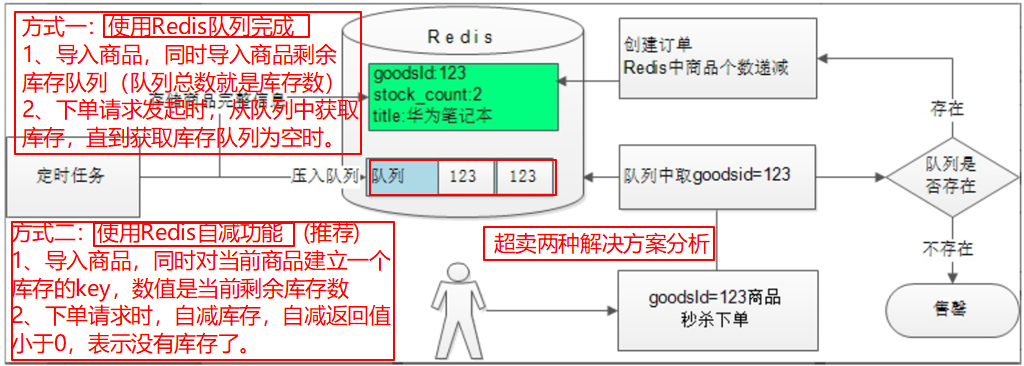
普通订单与秒杀订单如何共用一个支付微服务,说说思路。
什么是事务?
数据库事务(简称:事务,Transaction)是指数据库执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
事务拥有以下四个特性,习惯上被称为ACID特性:
原子性(Atomicity):整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性(Consistency):一个事务可以封装状态改变(除非它是一个只读的)。事务必须始终保持系统处于一致的状态,不管在任何给定的时间并发事务有多少。
举例:如果事务是并发多个,系统也必须如同串行事务一样操作。其主要特征是保护性和不变性(Preserving an Invariant),以转账案例为例,假设有五个账户,每个账户余额是100元,那么五个账户总额是500元,如果在这个5个账户之间同时发生多个转账,无论并发多少个,比如在A与B账户之间转账5元,在C与D账户之间转账10元,在B与E之间转账15元,五个账户总额也应该还是500元,这就是保护性和不变性。
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行,如同只有这一个操作在被数据库所执行一样。
持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。在事务结束时,此操作将不可逆转。什么是分布式事务?
分布式事务指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上,且属于不同的应用,分布式事务需要保证这些操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。分布式事务的解决方案有哪些?
1.基于XA协议的两阶段提交(2PC)
2.TCC编程事务
3.本地消息表-异步确保
4.MQ 事务消息
5.Seata集群与分布式的区别?
相同点:
分布式和集群都是需要有很多节点服务器通过网络协同工作完成整体的任务目标。
不同点:
分布式是指将业务系统进行拆分,即分布式的每一个节点都是实现不同的功能。而集群每个节点做的是同一件事情。说说Eureka集群的架构

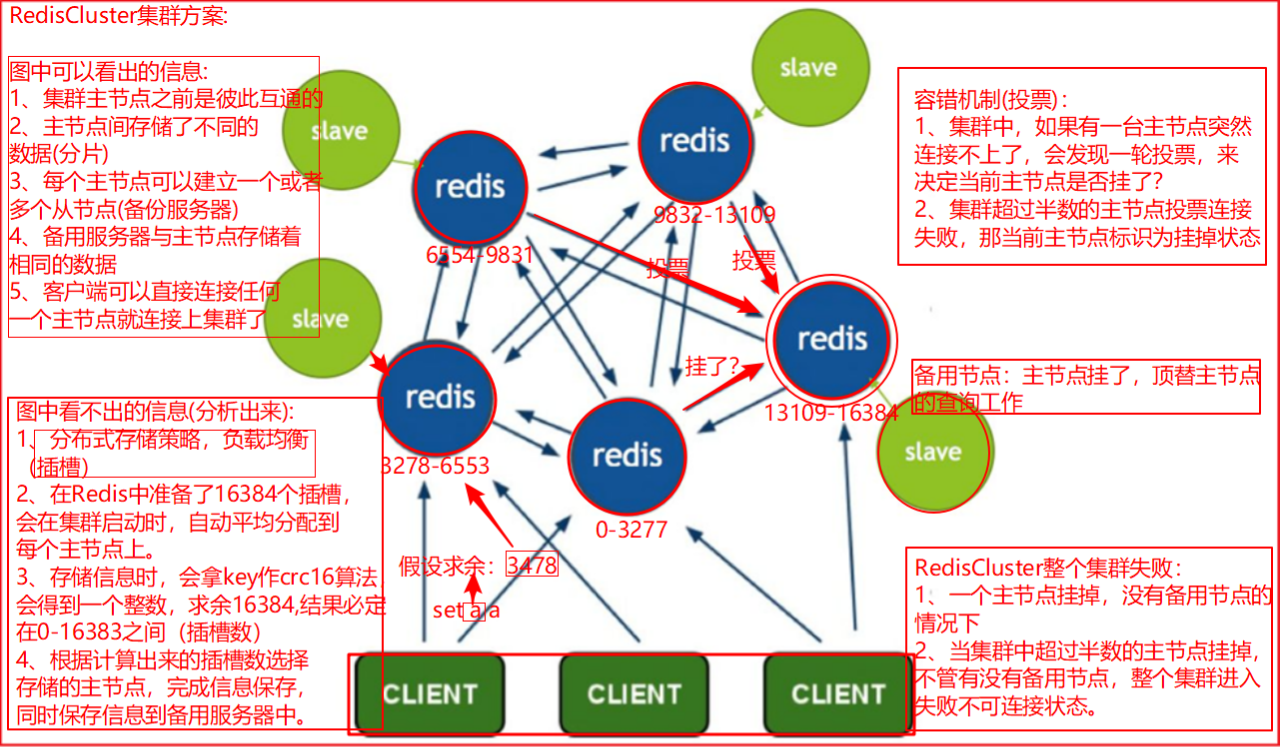
说说Redis-Cluster整体原理
什么是缓存雪崩?
缓存同一时间大面积失效,导致后面的请求会落到数据库上,造成数据库短时间内产生大量请求而崩掉。什么是缓存穿透?
黑客故意去请求缓存中不存在的数据,导致所有的请求落到数据库上,造成数据库短时间内承受大量请求而崩掉。

若有收获,就点个赞吧
0 人点赞
