| - 分享主题:Multi-source - 论文标题:Multi-source Distilling Domain Adaptation - 论文链接:https://arxiv.org/pdf/1911.11554.pdf - 分享人:唐共勇 |
|---|
1. Summary
【必写】,推荐使用 grammarly 检查语法问题,尽量参考论文 introduction 的写作方式。需要写出
- 这篇文章解决了什么问题?
- 作者使用了什么方法(不用太细节)来解决了这个问题?
- 你觉得你需要继续去研究哪些概念才会加深你对这篇文章的理解?
This paper is also to solve the problem of multi-source domain adaptation. The author believes that the previous MDA method has the following problems: in order to learn the domain invariant feature, the performance of the feature extractor is sacrificed;. It is considered that the contributions of multiple source domains are consistent, ignoring the different discreteness between different source domains and target domains. It is considered that the contribution of different samples in the same source domain is the same, ignoring that different samples have different similarities with the target domain. Based on the adaptive learning method, when the classifier has good performance, the gradient problem will appear
2. 你对于论文的思考
需要写出你自己对于论文的思考,例如优缺点,你的takeaways
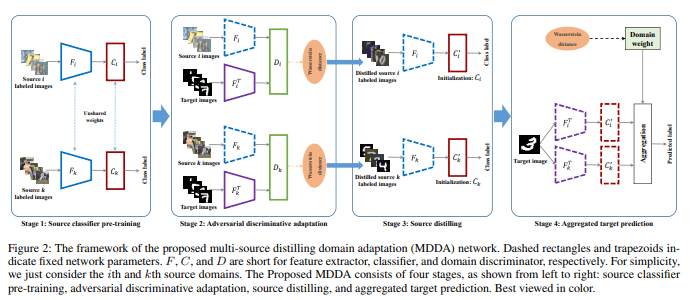
- Source Classifier Pre-training. 不用于以往的方法使用共享的backbone来提取多个源域的特征,作者认为采用共享的参数会让特征提取关注domain invariant feature从而对损失提取discriminative 的特征的能力。这里对每一个源域都训练一个独立的特征提取器F i 和分类器C i(没有共享参数)并且采用交叉熵来优化
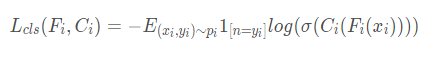
- Adversarial Discriminative Adaptation. 在pre-train阶段后,学习独立的target encoder将特征映射到源域空间S i,不同于以往的方法将所有域都映射到同一个domain。这里将target分别映射到N个source domain,来进行adversarial 的学习,并采用wassertein distance来优化target encoder尽量让domain d分辨器D i,通过最小化target的feature和source的feature之间Wasserstein距离。这样不同source domain的target domain之间的差距就可以通过wassertein distance来量化
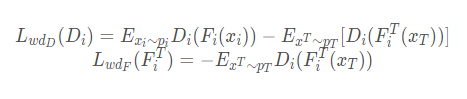
- Source distilling. 在distilling 不同域的区别后,作者进一步关注同一个domain中不同样本和target domain之间的差异。也是基于Wassertein distance来选择和target domain接近的样本来finetune 分类器。对于每一个样本x i j
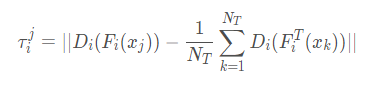
选择那些距离比较大的样本来finetune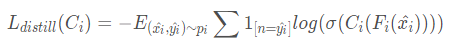
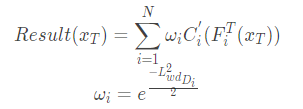

若有收获,就点个赞吧
0 人点赞
