| - 分享主题:Transformer for Time-Series Forecasting - 论文标题:REFORMER : THE EFFICIENT TRANSFORMER - 论文链接:https://openreview.net/pdf?id=rkgNKkHtvB - 分享人:唐共勇 |
|---|
1. Summary
【必写】,推荐使用 grammarly 检查语法问题,尽量参考论文 introduction 的写作方式。需要写出
- 这篇文章解决了什么问题?
- 作者使用了什么方法(不用太细节)来解决了这个问题?
- 你觉得你需要继续去研究哪些概念才会加深你对这篇文章的理解?
This paper is a paper on the improvement of the transformer. In the past, in some papers based on transformer structure, the total parameters of the model are very large, and some models can’t run on a single card GPU at all. In order to solve the problem of GPU resource consumption when the transformer model deals with long sequences, a more memory-saving and faster transformer model structure is proposed. There are two main improvements: using locality sensitive hashing instead of dot product attention, the computational complexity is directly reduced from O (L ^ 2) to O(LlogL), where l is the sequence length; The reversible residual layers are used to replace the traditional residual layer so that the storage of the value of the activation function in the training process is reduced from n times to 1 time, where n is the number of layers. The experimental results of this paper also confirm that reformer can be more efficient and has little loss of accuracy.
2. 你对于论文的思考
需要写出你自己对于论文的思考,例如优缺点,你的takeaways
优点:
1. 使用局部敏感哈希代替原本的q和k之间的点积操作,大幅降低了运算量
2. 可逆层解决了多层attention都需要存储起来的大内存消耗
缺点:
1.局部敏感哈希的流程是先计算相似性,将相似分到一个桶里,在这个桶内计算attention。问题在于需要采用多个哈希函数来映射,这些运算的开销也很大。
3. 其他
【可选】
LSH(局部敏感哈希)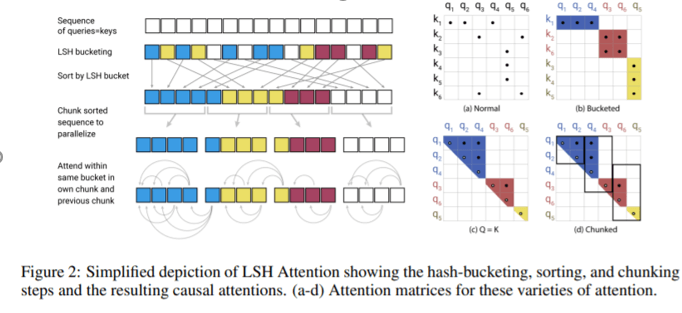
可逆层
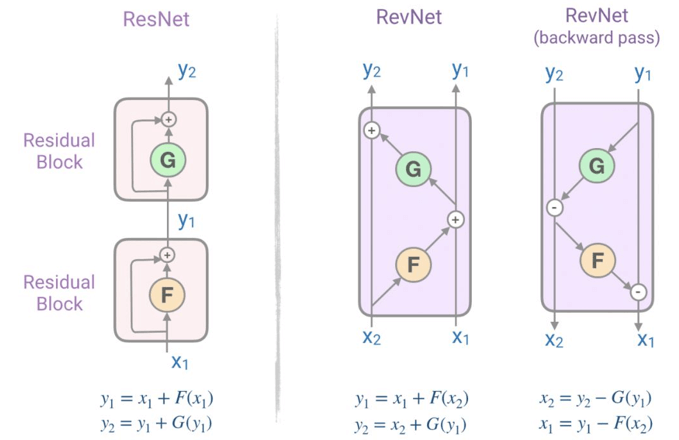
通过LSH可以将attention的复杂度减少为序列长度的线性级,但是参数量占的复杂度依旧很高(层数过多)。可逆层使用的是2017年的一个网络Revnets,主要思想是每一层的activation可以根据下一层的activation推导获得,从而不需要在内存中存储每层的activation。
在原本的Resnet中,得到输出的方法是
Y = x + F(x)
而在Revnets中,
同理,将其运用在Transformer中,有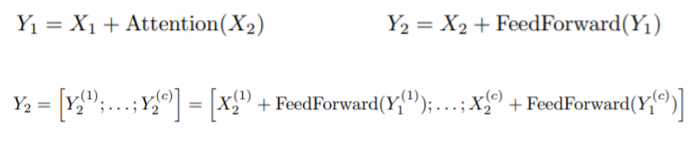
Transformer是一个基于encoder-decoder结构的模型。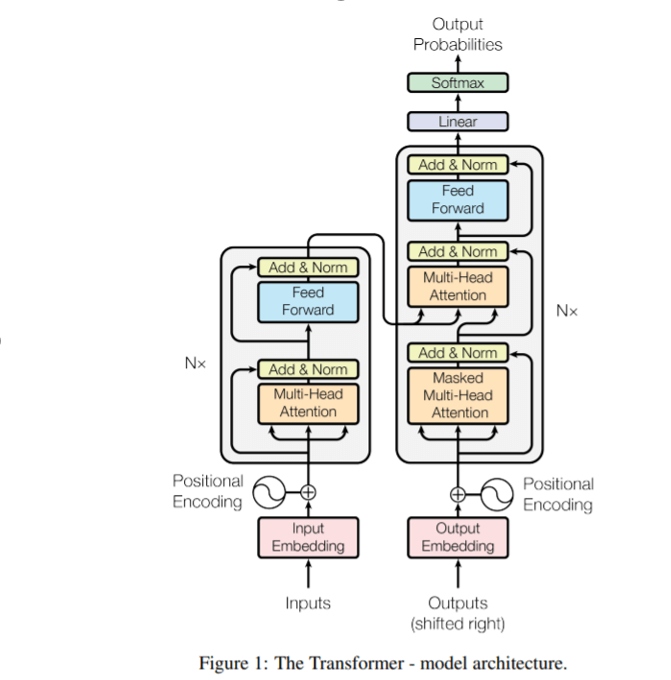
在encoder中主要由自注意力层和前馈神经网络层组成。输入的句子会通过自注意力层,在自注意力层会对单词进行编码时关注句子的其他单词。之后输出会传递到前馈神经网络中。每个位置的单词对应的前馈神经网络都完全一样。Decoder中也具有这两层,除此之外中间还有注意力层,来关注句子的重要部分。
自注意力的计算:Q、K、V。词向量与WQ、WK、WV矩阵相乘得到QKV。对于当前词的q与所有单词的k进行运算,得到对每个单词得分,每个单词的v与得分相乘,再归一化,作为最终的单词的表示。
多头自注意力机制:多头就是多个计算自注意力的模块。将输出的Z拼接组成最后的表示。到目前为止,还缺少一个表示位置关系的方法。
为了解决这个问题,Transformer为每个输入的词嵌入添加了一个向量。这些向量遵循模型学习到的特定模式,这有助于确定每个单词的位置,或序列中不同单词之间的距离。这里的假设是,将位置向量添加到词嵌入中使得它们在接下来的运算中,能够更好地表达的词与词之间的距离。

若有收获,就点个赞吧
0 人点赞
