一. 对象的创建
创建对象大致有以下四种方式
使用new关键字创建,基本方式
Object object = new Object();
使用Object的clone()方法

clone()方法是一个本地方法,被关键字native修饰,要想使用clone方法必须实现Cloneable接口,重写clone()方法,否则抛出CloneNotSupportedException异常(克隆不被支持)。
public class Person implements Cloneable, Serializable{int age ;//年龄String name;//姓名Position position;//职位信息public int getAge() {return age;}public String getName() {return name;}public void setAge(int age) {this.age = age;}public void setName(String name) {this.name = name;}public Position getPosition() {return position;}public void setPosition(Position position) {this.position = position;}//不重写,用父类的clone方法@Overrideprotected Person clone() throws CloneNotSupportedException {return (Person)super.clone();}}public class Position {String companyName;//公司名称String positionName;//职位名称public String getCompanyName() {return companyName;}public void setCompanyName(String companyName) {this.companyName = companyName;}public String getPositionName() {return positionName;}public void setPositionName(String positionName) {this.positionName = positionName;}}
这是个Person类有三个属性,年龄、姓名、职位信息,通过clone方法克隆一个对象。
public class test{public static void main(String[] arg) throws CloneNotSupportedException {Position position = new Position();position.setCompanyName("腾讯");position.setPositionName("开发工程师");Person p1 = new Person();p1.setAge(18);p1.setName("小王");p1.setPosition(position);Person p2 = p1.clone();System.out.println("p1内存地址:"+p1+",p1中position内存地址:"+p1.getPosition());System.out.println("p2内存地址:"+p2+",p2中position内存地址:"+p2.getPosition());}}
结果如下,有两个问题:
- p1,p2指向的内存地址值不一样,指向不同的对象
对p1进行克隆的时候,是完全创建了一个新对象,有自己的内存地址,p2就指向这个新创建的对象
- p1,p2中position指向的内存地址值一样,指向同一个对象,对p1的position修改,会影响p2的position
我们在重写clone方法的时候并没有,给出具体的实现细节,而是用super关键字,沿用父类的clone方法。这时的clone方法,并不会新建个position对象,而是指向的p1的position,要想创建新的position对象,两个对象互不影响,则需要我们自己实现clone()方法
@Overrideprotected Person clone() throws CloneNotSupportedException {Person person = (Person)super.clone();Position position = new Position();position.companyName = person.position.companyName;position.positionName = person.position.positionName;person.setPosition(position);return person;}

重写后,p1,p2指向的内存地址就不一样了,这要就不会相互影响了。
- 反射
所谓反射其实就是,通过类对象来获取类本身的信息,比如有几种构造方法, 有多少属性,有哪些普通方法,每个类都有自己的类对象,通过类对象,我们就能够从反射的角度来创建对象了。
Person p1 = Person.class.newInstance();
- 反序列化
序列化是指将对象转换成字节序列(byte[]数组)的过程称为对象的序列化,反序列化则是将字节序列恢复为对象的过程
实现序列化之前,被序列化的对象要实现Serializable接口才能序列化成功
public class test{public static void main(String[] arg){try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("person.txt"))) {//序列化Person person = new Person();person.setName("小张");person.setAge(18);oos.writeObject(person);//反序列化ObjectInputStream ois = new ObjectInputStream(new FileInputStream("person.txt"));Person person1 = (Person) ois.readObject();System.out.println(person1.getName() +"," + person1.getAge());} catch (Exception e) {e.printStackTrace();}}}//输出结果:小张,18
2. 对象的使用
使用对象有两种方式,一是通过句柄访问,而是通过直接指针访问。
对象实例数据(堆):对象中各个实例字段的数据 对象类型数据(方法区):对象的类型、父类、实现的接口、方法等
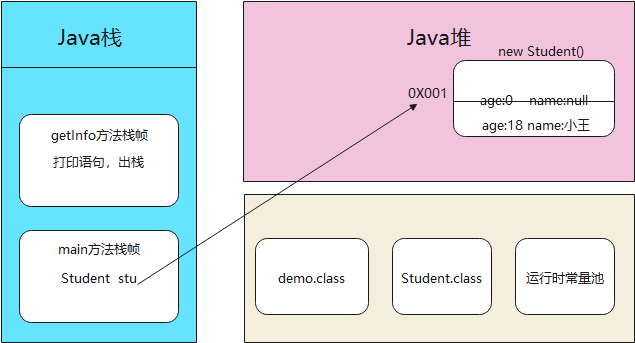
public class Student{int age ;//年龄String name;//姓名public void getInfo(){System.out.println("姓名:"+name+",年龄:"+age);}}public class demo {public static void main(String[] args){Student stu = new Student();stu.name = "小王";stu.age = 18;stu.getInfo();}//输出结果:姓名:小王,年龄:18}
我们可以分析下这段代码在虚拟机的内存流程:
①启动程序,demo.java被编译成字节码文件demo.class,将字节码文件放入方法区,查看字节码文件中是否有常量,有则放入常量池
②执行main方法,创建main方法栈帧,入Java栈,执行main方法程序
③按main方法顺序执行,创建student对象,方法区中没有类student的字节码文件,加载Student.class到方法区,然后创建对象,Student stu 引用在main栈帧中,堆中创建一个区域存放对象实例,地址为0X001,age默认值是0,name默认值为null
④通过stu引用指向的地址,拿到对象进行赋值
⑤调用getInfo()方法,getInfo()方法的栈帧入Java栈,执行getInfo方法,打印了一句话“姓名:小王,年龄:18”,方法执行结束,出栈。剩余main方法栈帧在里面
⑥main方法执行完成,main方法栈帧出栈,程序运行完成。
注意: JDK1.7 及之后版本的 JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池。
- 通过句柄访问
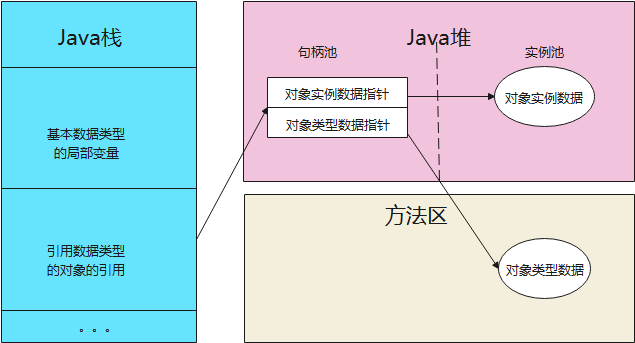
我们在创建对象的时候,Java堆中会划分出一块内存来作为句柄池,引用变量中存储的就是对象的句柄地址,而句柄中包含了对象实例数据和类型数据各自的具体地址信息,
- 通过**直接指针访问**
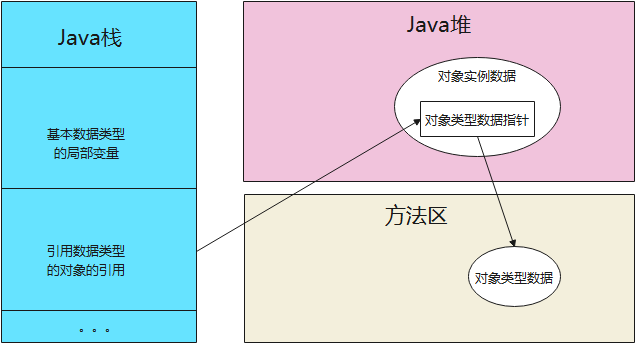
在堆中就不会分句柄池了,直接指向了对象的地址,对象中包含了对象类型数据的地址。
3. 对象的回收
几乎所有的对象实例都存放在堆中,那JVM怎么知道那些对象需要进行回收清除?首先要判断这个对象是否已经不在被使用,判断对象是否被使用有两种方法。
- 引用计数法
创建对象之后,会给每个对象添加一个引用计数器,每当这个对象被引用时,引用计数器加1;引用失效时,引用计数器减1。当这个对象的引用计数器为0,不在变化时,则该对象没有被引用,可回收。虽然这种方法实现简单,但是如果两个对象之间相互调用,引用计数器都不会为0,他们都不会被回收,显然Java虚拟机并没有选择这种方法来管理内存。
- 可达性分析法
通过一些被称为GC Roots的对象作为起点,从这些节点开始向下搜索,搜索走过的路径被称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连时(即从GC Roots节点到该节点不可达),则证明该对象是不可用的。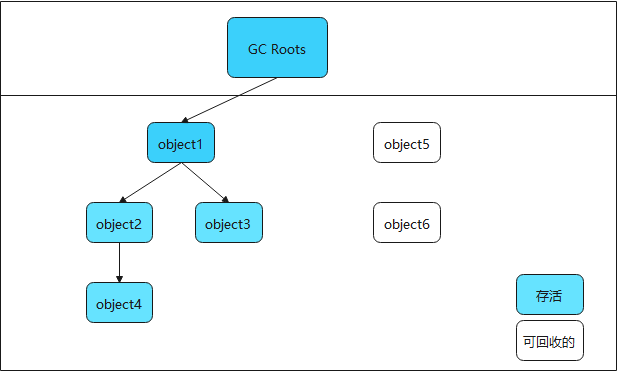

若有收获,就点个赞吧
0 人点赞
