基本数据类型,有存放在栈中的,也有存放堆中的,这取决去基本类型声明的位置。
一:在方法中声明的变量,即该变量是局部变量,每当程序调用方法时,系统都会为该方法建立一个方法栈,其所在方法中声明的变量就放在方法栈中,当方法结束系统会释放方法栈,其对应在该方法中声明的变量随着栈的销毁而结束,这就局部变量只能在方法中有效的原因
在方法中声明的变量可以是基本类型的变量,也可以是引用类型的变量。(1)当声明是基本类型的变量的时,其变量名及值(变量名及值是两个概念)是放在方法栈中(2)当声明的是引用变量时,所声明的变量(该变量实际上是在方法中存储的是内存地址值)是放在方法的栈中,该变量所指向的对象是放在堆类存中的。
二:在类中声明的变量是成员变量,也叫全局变量,放在堆中的(因为全局变量不会随着某个方法执行结束而销毁)。
同样在类中声明的变量即可是基本类型的变量 也可是引用类型的变量(1)当声明的是基本类型的变量其变量名及其值放在堆内存中的(2)引用类型时,其声明的变量仍然会存储一个内存地址值,该内存地址值指向所引用的对象。引用变量名和对应的对象仍然存储在相应的堆中
比较一下八个基本数据类型的区别吧。
| 基本类型 | 大小 | 最小值 | 最大值 | 默认值 | 包装类 | 如何定义 |
|---|---|---|---|---|---|---|
| boolean | - | - | - | false | Boolean | boolean a = true; |
| char | 16bit | 0 | 2 | null | Character | char a = ‘c’; |
| byte | 8bit | -128 | 127 | 0 | Byte | byte a = 10; |
| short | 16bit | -2 | 2 | 0 | Short | short a = 10; |
| int | 32bit | -2 | 2 | 0 | Integer | int a = 10; |
| long | 64bit | -2 | 2 | 0 | Long | long a = 10L; |
| float | 32bit | -2 | 2 | 0.0 | Float | float a = 10.0f; |
| double | 64bit | -2 | 2 | 0.0 | Double | double a = 10.0; |
8 bit(位) = 1 Byte (字节)
整 型:byte,short,int,long
浮点型:float,double
逻辑型:boolean
字符型:char
我们先来看几个例子。
奇怪的精度问题
public class demo {public static void main(String[] arg){System.out.println(2.00f-1.10f);System.out.println(2.00-1.10);}/* 输出:0.90.8999999999999999*/}
你可能以为程序打印出来的都是0.9,但事实却不是,为什么会出现这种情况呢。
原来2.00和1.10在计算机里存储的时候,需要转换成二进制,浮点型默认是double类型的(即没有加f),从上面的列举的区别表格中知道,float占4个字节32位,double占8个字节64位,而1.10在转换成二进制的时候,是1.000110…….,而double类型表示小数部分只有52位,当向后计算 52位后基数还不为0,那后面的部分只能舍弃,从这里可以看出float、double并不能准确表示每一位小数,对于有的小数只能无限趋向它,所以计算后的结果是0.8999999999999999。
当加上f之后,规定了类型为float精度,并没有double精度那么大,小数部分0.1二进制表示被舍去的比较多。长整除问题
public class demo {public static void main(String[] arg){final long a = 24 * 60 * 60 * 1000 * 1000;final long b = 24 * 60 * 60 * 1000;System.out.println(a/b);}//输出: 5}
1000???错是5,这有是什么情况
24606010001000 的结果计算时为int类型,计算后再转成long型,明显结果超出了int类型的表达范围,在运算的过程中运算结果仍然为int型,超出范围就截取后64位作为运算的结果。因此,我们看到虽然定义了long型变量,但结果仍然是截取后的结果。其实 a = 500654080,b = 86400000 ,得到的结果也就是5。
当我们修改成这样:public class demo {public static void main(String[] arg){final long a = 24l * 60 * 60 * 1000 * 1000;final long b = 24l * 60 * 60 * 1000;System.out.println(a/b);}//输出: 1000}
24后面加上L后,结果就是我们所预期的结果了。
因此,我们中写代码中,如果对精度要求很高的,建议使用BigDecimal来运算,一般用来计算高精度的数据。
为什么需要包装类
因为基本数据类型不是对象,在有些时候使用对象是最方便的,比如List的add(Object e)方法,参数是Object类型,是引用数据类型,那我们想放入基本数据类型怎么办,为了方便操作基本数据类型,所以引入了包装类。
自动装箱和自动拆箱
自动装箱其实就是将基本数据类型转换成包装类,反之自动拆箱就是把包装类转换成基本数据类型。
public static void main(String[] args) {Integer i = 10;//自动装箱int i2 = i;//自动拆箱}
public static void main(String[] args) {int i = 100;Integer i1 = 100;Integer i2 = 100;Integer i3 = 200;Integer i4 = 200;System.out.println(i == i1);// trueSystem.out.println(i1 == i2);// trueSystem.out.println(i3 == i4);// false}
为什么一个true,一个false呢,我们分析下源码,查看编译后的字节码文件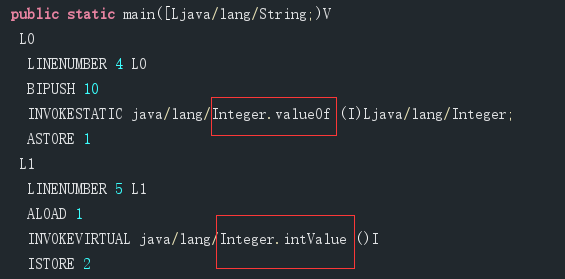
从字节码文件中,我们可以得知,装箱调用的Integer.valueOf方法,拆箱调用Integer.intValue方法,我们快来看下这两个方法的源码和他的构造函数。
public Integer(int value) {this.value = value;}public static Integer valueOf(int i) {if (i >= IntegerCache.low && i <= IntegerCache.high)return IntegerCache.cache[i + (-IntegerCache.low)];return new Integer(i);}public int intValue() {return value;}
i与i1用==比较的时候,会自动将i1自动拆箱,比较的是基本数据类型。
这里没有放出IntegerCache的相关代码,从这个类中可以得知,IntegerCache.low为-128,IntegerCache.high为127,当在这个范围内的基本类型,转换成Integer的时候,就直接从缓存取,所以i1和i2是相等的,但是i3,i4都不在这个范围内,所以都新建了Integer对象,所以不相等。
其实Byte、Short、Integer、Long、Character的valueOf()方法实现机制和Integer类似,但是Float、Double中的valueOf(),永远返回新创建的对象,因为一个范围内的整数是有限的,但是小数却是无限的,无法保存在缓存中,Boolean中只有两个对象,要么是true的Boolean,要么是false的Boolean,只要boolean的值相同,Boolean就相等。
()

若有收获,就点个赞吧
0 人点赞
