摘要:
我们干了什么?
提出了一个新的简单的架构
We propose a new simple network architecture,the Transformer,based solely on attention mechanisms,dispensing with recurrence and convolutions entirely.
这个模型有什么用?
在机器翻译上效果非常好
Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizabel and requiring significantly less time to train.
结论:
我们介绍的Transformer模型,是第一个做序列转录的模型,仅仅使用了注意力机制,它把之前所有的循环层全部换成了multi-headed self-attention。
他认为这个模型可以用在更多的方向上,例如图片,语音,视频上。
介绍:
在其中有两个主流模型,一个是语言模型,另一个是编码器和解码器的架构。
RNN的特点:在RNN中它把之前的信息全部放在隐藏状态中,从左往右一步一步向右移动,对第t个词,它的隐藏状态由前面一个词的隐藏状态和当前词来决定的。
RNN的缺点:因为需要得到前面的序列的信息,无法并行执行,性能较差。如果时序比较长,可能对内存开销比较大。
Transformer模型基于纯注意力机制,所以并行度比较高,可以在比较短的时间内得到更好的结果。
模型介绍:
什么是编码器?
会将一个输入序列表示为一个向量序列,例如一个句子,则会将每一个字或词都表示为一个向量,最终整个句子表示为向量序列。
什么是解码器?
通过编码器的输出,生成一个序列,其中每个字或词都需要一个一个生成。
由于在前面序列的输出,又会作为当前序列的输入,使用也被称之为自回归模型。
自回归模型(auto-regressive):你的输入又是你的输出。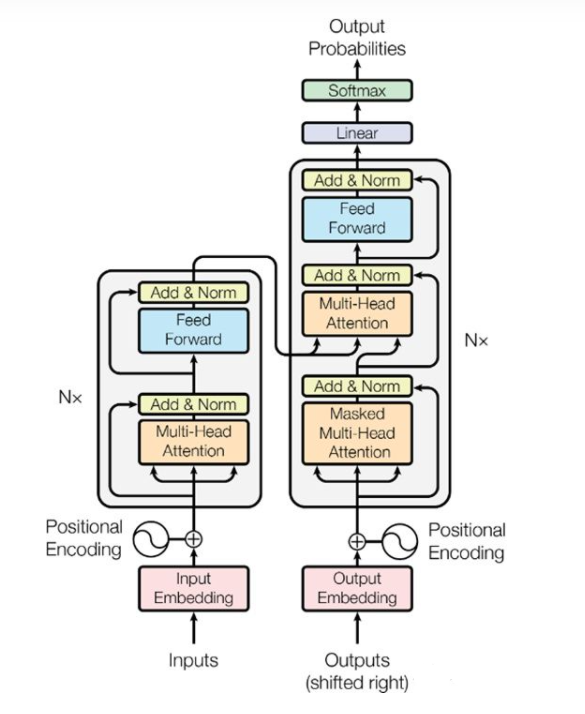
在上图中,左侧为编码器,右侧为解码器
当输入的时候,先进入一个嵌入层,把词表示为向量
之后再经过Positional Encoding
最后编码器经过N层之后进入解码器,解码器通过Liner和Softmax然后输出。

若有收获,就点个赞吧
0 人点赞
