RocketMQ如何集群化部署来支撑高并发访问呢?
假设RockerMQ部署在一台机器上,即使这台机器配置很高,但是一般来说一台机器也就是支撑10万左右的并发访问。
那么这个时候,假设有大量的系统都要往RocketMQ里并发写入消息,每秒几十万请求,这时该怎么办?
RocketMQ是可以集群化部署的,可以部署在多台机器上,只要将几十万请求分散到多台机器上就可以了。MQ如果要存储海量消息应该怎么做?
MQ会收到大量的消息,这些消息并不是立马被消费者获取去消费的,所以一般MQ都会把消息在自己本地磁盘存储起来,然后等待消费方获取消息去消费。
既然如此,MQ就得存储大量的消息,几百万条到几亿条不等,这么多的消息在一台机器上肯定是没法存储的。
其实发送消息到MQ的系统会把消息分散发送给多台不同的机器,一万条消息分散给十台机器,每台机器就是一千条消息。
每台机器上的RocketMQ进程一般称之为broker,每个broker会收到不同的消息,然后把这些消息在自己本地磁盘存储。
本质上RocketMQ存储海量消息的机制就是分布式存储。如何保障高可用(broker宕机了怎么办)?
broker基于主从架构以及多副本策略来保证高可用。
broker是由Master和Slave两种角色的,Master收到消息后会同步给Slave,这样Slave上就能有一模一样的一份副本数据。
这样同一条消息在RocketMQ的整个集群里就有两个副本了,这个时候如果任何一个Master发生故障,还有一个Slave上有一份副本数据,可以保证数据不丢失,继续对外提供服务。
保证了MQ的可靠性可高可用性。数据路由:怎么知道访问哪个broker?
对于系统来说,要发送消息到MQ里面去,还要从MQ中获取消息来消费,那么怎么知道有哪些broker,怎么知道要连接到哪一台broker上发送和消费消息?
RocketMQ为了解决这个问题,有一个NameServer的概念,他是独立部署在几台机器上的,然后所有的机器都会把自己注册到NameServer上去,NameServer就知道集群里有哪些broker了。
对于我们的系统而言如果他要发送消息到broker,会去NameServer去获取路由信息,如果系统要从broker获取消息,也会找NameServer获取路由消息,去找对应的broker信息。
这就是RocketMQ最基本的一个架构原理(如下图)。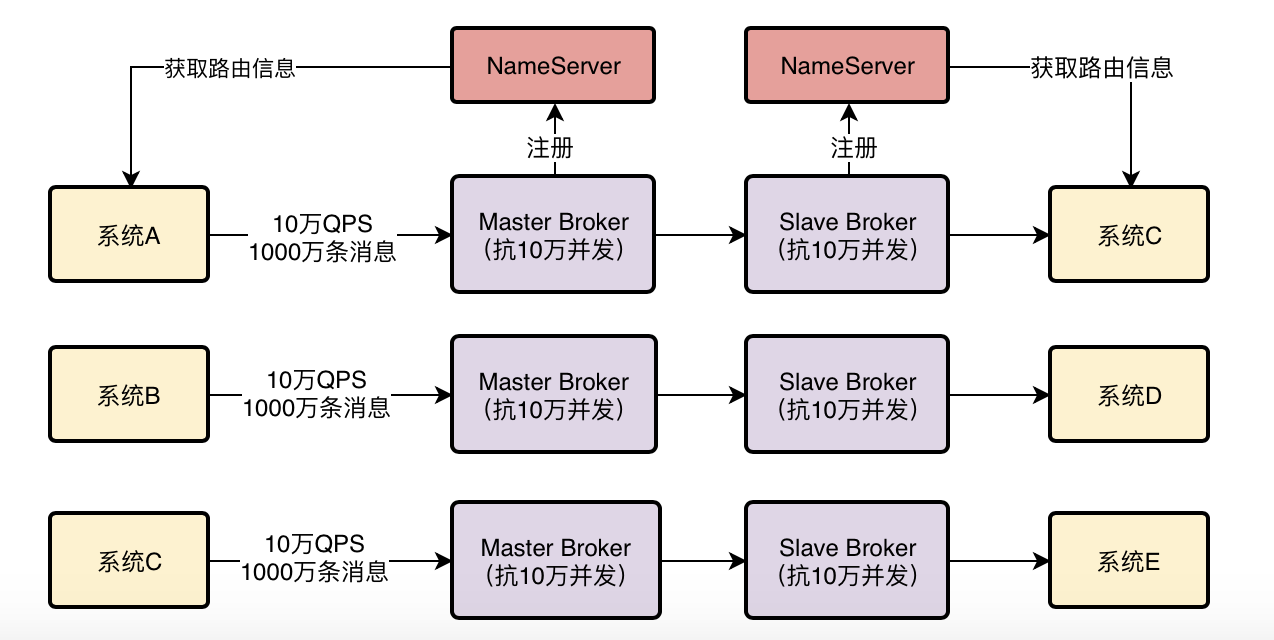

若有收获,就点个赞吧
0 人点赞
