一、使用场景
前端生成word的是用场景,应该是在word展示的形式较为复杂的时候(例如word中需要出现echarts或mapbox截图的时候)
例:
或者是服务器对于接口请求时间进行了限制,但是后端对于数据的处理时间远超请求时间的情况(这种情况基本不会有,本次是情况特殊)
二、使用方法
1、创建word文档模板
普通字段: {字段名}
循环:{#数组字段名}{字段名}{/数组字段名}
图片:{%图片字段名}
word文件需要放在public文件夹下
2、添加依赖
npm install docxtemplater pizzip jszip jszip-utils file-saver docxtemplater-image-module-free -s
docxtemplater :模板
pizzip :用于获取模板文件
jszip-utils: 获取读取文件内容
jszip :用于打包文件,没有需求可不加
file-saver:保存文件
docxtemplater-image-module-free: 导入图片值docx模板
3、创建downWord.js文件
/**导出docx@param { String } tempDocxPath 模板文件路径@param { Object } data 文件中传入的数据@param { Array } imgSize 文件设置图片大小@param { String } fileName 导出文件名称*/import docxtemplater from "docxtemplater";import PizZip from "pizzip";import JSZipUtils from "jszip-utils";import ImageModule from 'docxtemplater-image-module-free';import { saveAs } from 'file-saver'export const exportDocx = (tempDocxPath, data, imgSize = [600, 900], fileName) => {// 读取并获得模板文件的二进制内容return new Promise((resolve) => {JSZipUtils.getBinaryContent(tempDocxPath, (error, content) => {// 抛出异常if (error) {console.log("no");throw error}// 创建一个JSZip实例,内容为模板的内容const zip = new PizZip(content)// 创建并加载docxtemplater实例对象const doc = new docxtemplater().loadZip(zip)// 关于模板中图片的设置const opts = {}opts.centered = true; // 图片居中,在word模板中定义方式为{%image}opts.fileType = "docx"; // 图片所放置的文件格式opts.getImage = (chartId) => {return base64DataURLToArrayBuffer(chartId);} // 官网的方法,将图片转成word适用的格式opts.getSize = function () {return imgSize // 图片大小,自定义的值[宽,高]}let imageModule = new ImageModule(opts);doc.attachModule(imageModule);// 设置模板变量的值doc.setData(data)try {// 呈现模板,通过对模板中{}的定义字段,填入相关内容,并产生文件doc.render()} catch (error) {const e = {message: error.message,name: error.name,stack: error.stack,properties: error.properties}console.log({error: e})throw error}const out = doc.getZip().generate({type: 'blob',mimeType: 'application/vnd.openxmlformats-officedocument.wordprocessingml.document'}) // 输出文件流格式的文档// 官网原生方法是在这里使用saveAs,但是因为业务需求,还需要对生成的多个文件打包,所以选择抛出文件流resolve(out)// saveAs(out, fileName)})})}const base64DataURLToArrayBuffer = (dataURL) => {const base64Regex = /^data:image\/(png|jpg|jpeg|svg|svg\+xml);base64,/;if (!base64Regex.test(dataURL)) {return false}const stringBase64 = dataURL.replace(base64Regex, "");let binaryString;if (typeof window !== "undefined") {binaryString = window.atob(stringBase64);} else {binaryString = new Buffer(stringBase64, "base64").toString("binary");}const len = binaryString.length;const bytes = new Uint8Array(len);for (let i = 0; i < len; i++) {const ascii = binaryString.charCodeAt(i);bytes[i] = ascii;}return bytes}//图片链接转base64export const UrlToBase64 = (url) => {return new Promise((resolve) => {// 设置需要文件大小的定值var targSize = 512 * 1024 //512KBlet timeStamp = new Date().getTime();// 通过构造函数来创建的 img 实例,在赋予 src 值后就会立刻下载图片// 这里也可以使用 createElement() 创建 <img>标签,但是多了append()这一步,增加了冗余let Img = new Image();// 处理缓存,fix缓存bug,有缓存,浏览器会报错;Img.src = url + '?' + timeStamp;// 解决控制台跨域报错的问题,设置允许跨域Img.crossOrigin = 'Anonymous';// 获取后缀,这里不用这一步的原因是jpeg对于图片的压缩比更大,let ext = Img.src.substring(Img.src.lastIndexOf('.') + 1).toLowerCase();ext = "jpeg"Img.onload = function () {// 设置初始的压缩比var quality = 0.5;var canvas = document.createElement('canvas'); //创建canvas元素// 确保canvas的尺寸和图片一样canvas.width = Img.width;canvas.height = Img.height;// 将图片绘制到canvas中canvas.getContext('2d').drawImage(Img, 0, 0, Img.width, Img.height);// 转换图片为dataURLvar base64 = canvas.toDataURL(`image/${ext}`, quality); //压缩语句// 判断文件大小是否符合targSize设置大小,没有就进行循环压缩while (base64.length > targSize) {quality -= 0.05;base64 = canvas.toDataURL(`image/${ext}`, quality);}// console.log("-----转换成功");resolve(base64);};});}/**导出docx@param { String } tempDocxPath 模板文件路径@param { Object } data 文件中传入的数据@param { Array } imgSize 文件设置图片大小@param { String } fileName 导出文件名称*/import docxtemplater from "docxtemplater";import PizZip from "pizzip";import JSZipUtils from "jszip-utils";import ImageModule from 'docxtemplater-image-module-free';import { saveAs } from 'file-saver'export const exportDocx = (tempDocxPath, data, imgSize = [600, 900], fileName) => {// 读取并获得模板文件的二进制内容return new Promise((resolve) => {JSZipUtils.getBinaryContent(tempDocxPath, (error, content) => {// 抛出异常if (error) {console.log("no");throw error}// 创建一个JSZip实例,内容为模板的内容const zip = new PizZip(content)// 创建并加载docxtemplater实例对象const doc = new docxtemplater().loadZip(zip)// 关于模板中图片的设置const opts = {}opts.centered = true; // 图片居中,在word模板中定义方式为{%image}opts.fileType = "docx"; // 图片所放置的文件格式opts.getImage = (chartId) => {return base64DataURLToArrayBuffer(chartId);} // 官网的方法,将图片转成word适用的格式opts.getSize = function () {return imgSize // 图片大小,自定义的值[宽,高]}let imageModule = new ImageModule(opts);doc.attachModule(imageModule);// 设置模板变量的值doc.setData(data)try {// 呈现模板,通过对模板中{}的定义字段,填入相关内容,并产生文件doc.render()} catch (error) {const e = {message: error.message,name: error.name,stack: error.stack,properties: error.properties}console.log({error: e})throw error}const out = doc.getZip().generate({type: 'blob',mimeType: 'application/vnd.openxmlformats-officedocument.wordprocessingml.document'}) // 输出文件流格式的文档// 官网原生方法是在这里使用saveAs,但是因为业务需求,还需要对生成的多个文件打包,所以选择抛出文件流resolve(out)// saveAs(out, fileName)})})}const base64DataURLToArrayBuffer = (dataURL) => {const base64Regex = /^data:image\/(png|jpg|jpeg|svg|svg\+xml);base64,/;if (!base64Regex.test(dataURL)) {return false}const stringBase64 = dataURL.replace(base64Regex, "");let binaryString;if (typeof window !== "undefined") {binaryString = window.atob(stringBase64);} else {binaryString = new Buffer(stringBase64, "base64").toString("binary");}const len = binaryString.length;const bytes = new Uint8Array(len);for (let i = 0; i < len; i++) {const ascii = binaryString.charCodeAt(i);bytes[i] = ascii;}return bytes}//图片链接转base64export const UrlToBase64 = (url) => {return new Promise((resolve) => {// 设置需要文件大小的定值var targSize = 512 * 1024 //512KBlet timeStamp = new Date().getTime();// 通过构造函数来创建的 img 实例,在赋予 src 值后就会立刻下载图片// 这里也可以使用 createElement() 创建 <img>标签,但是多了append()这一步,增加了冗余let Img = new Image();// 处理缓存,fix缓存bug,有缓存,浏览器会报错;Img.src = url + '?' + timeStamp;// 解决控制台跨域报错的问题,设置允许跨域Img.crossOrigin = 'Anonymous';// 获取后缀,这里不用这一步的原因是jpeg对于图片的压缩比更大,let ext = Img.src.substring(Img.src.lastIndexOf('.') + 1).toLowerCase();ext = "jpeg"Img.onload = function () {// 设置初始的压缩比var quality = 0.5;var canvas = document.createElement('canvas'); //创建canvas元素// 确保canvas的尺寸和图片一样canvas.width = Img.width;canvas.height = Img.height;// 将图片绘制到canvas中canvas.getContext('2d').drawImage(Img, 0, 0, Img.width, Img.height);// 转换图片为dataURLvar base64 = canvas.toDataURL(`image/${ext}`, quality); //压缩语句// 判断文件大小是否符合targSize设置大小,没有就进行循环压缩while (base64.length > targSize) {quality -= 0.05;base64 = canvas.toDataURL(`image/${ext}`, quality);}// console.log("-----转换成功");resolve(base64);};});}
4、转换图片格式
这一步用于将图片链接转为base64
echarts和mapbox生成图片直接就是base64格式,可以跳过这一步
引入downWord.js中的UrlToBase64方法
//方法是异步的,有需要可选加awaitlet img = await UrlToBase64(url)
5、调用导出函数
data数据格式需要与word模板对应(仅供参考)
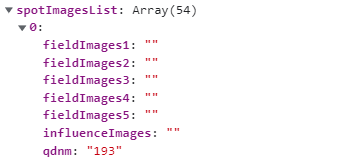

代码:
/**/waterMinistry是网址后缀,不清楚的可以去vue.config.js文件找一下/temp.docx是文件名@param { Object } data 导出需要的数据*/let doc = await exportDocx('/waterMinistry/temp.docx', data, [150, 100])let name = '已核查图斑.docx'saveAs(doc, name)
6、实现效果
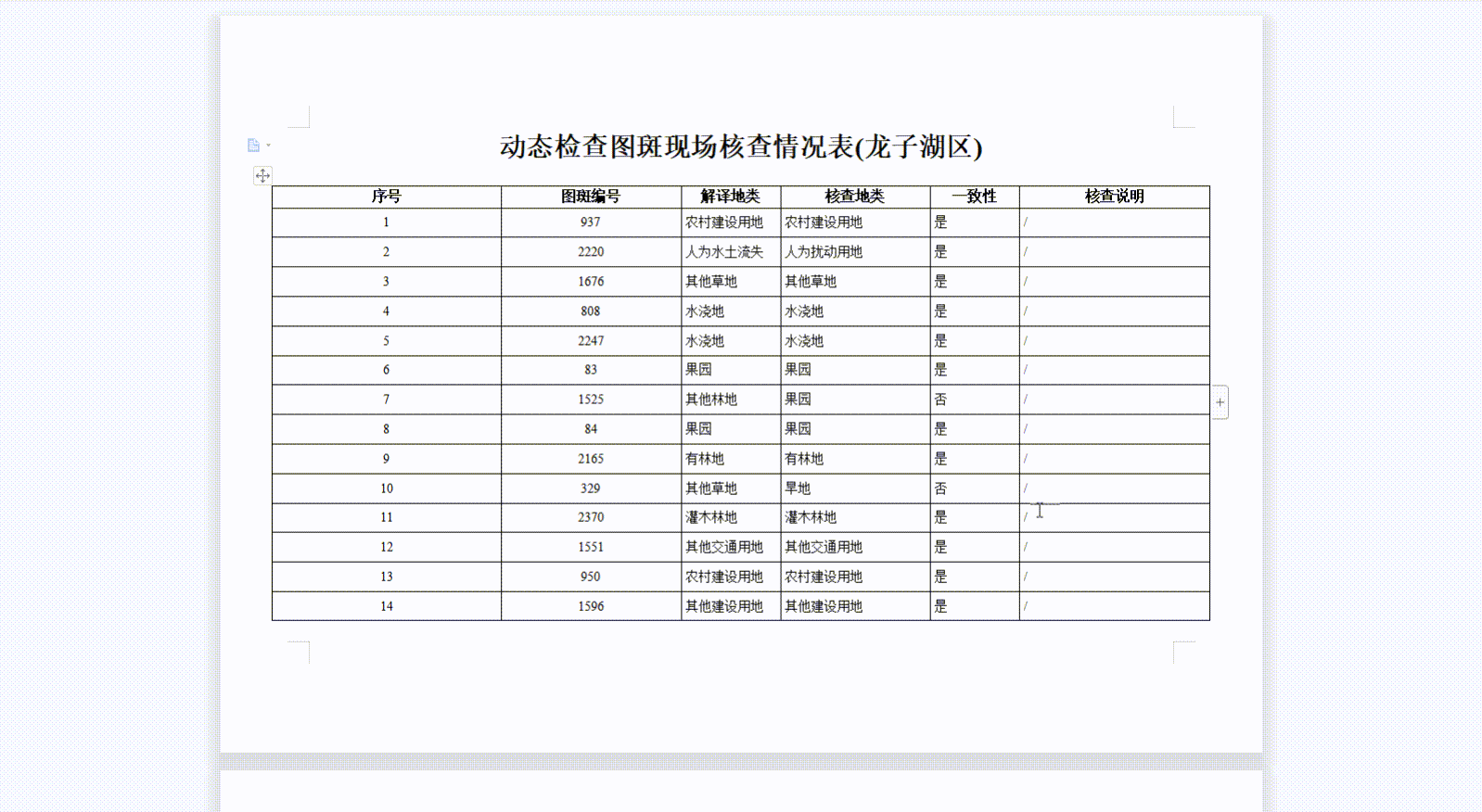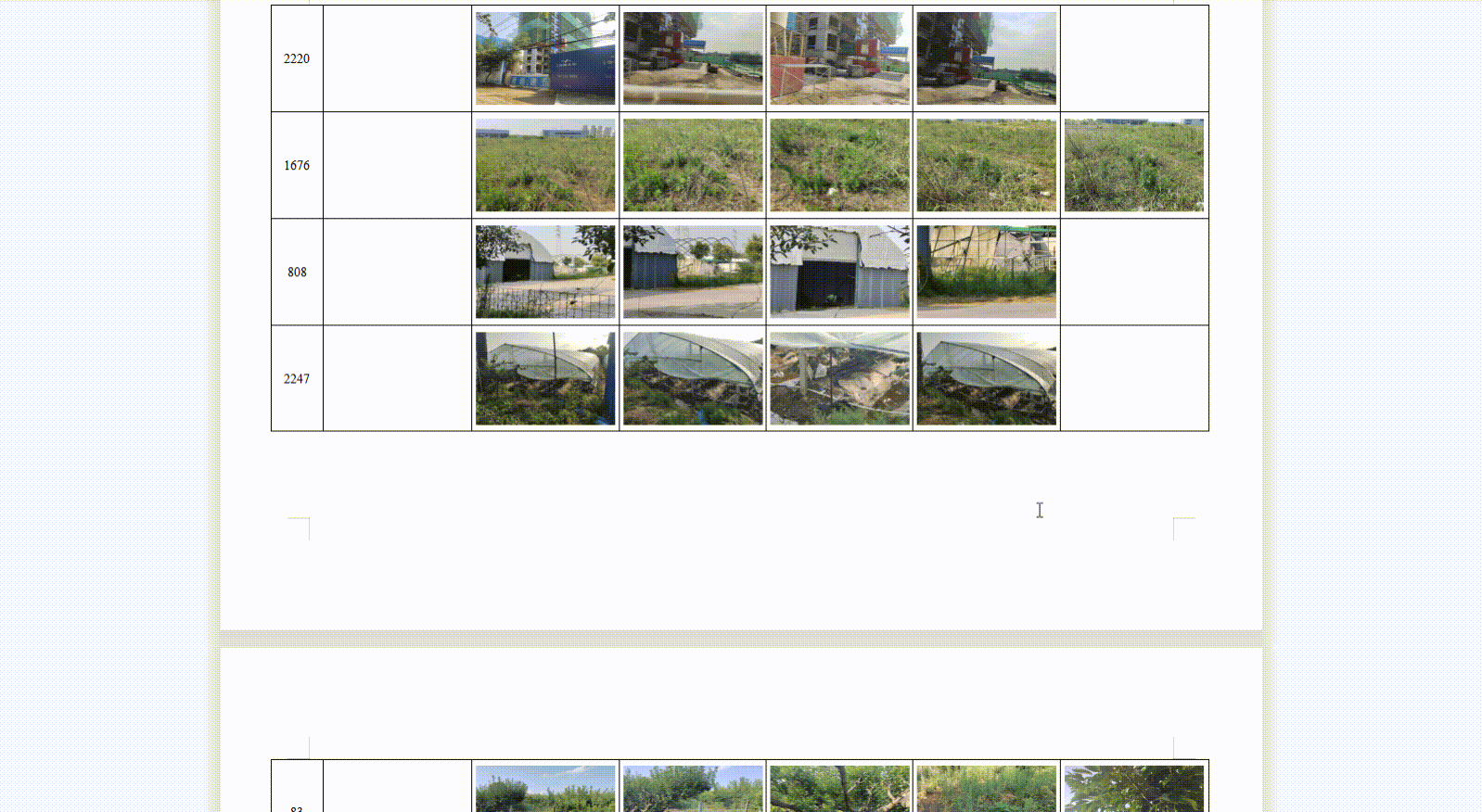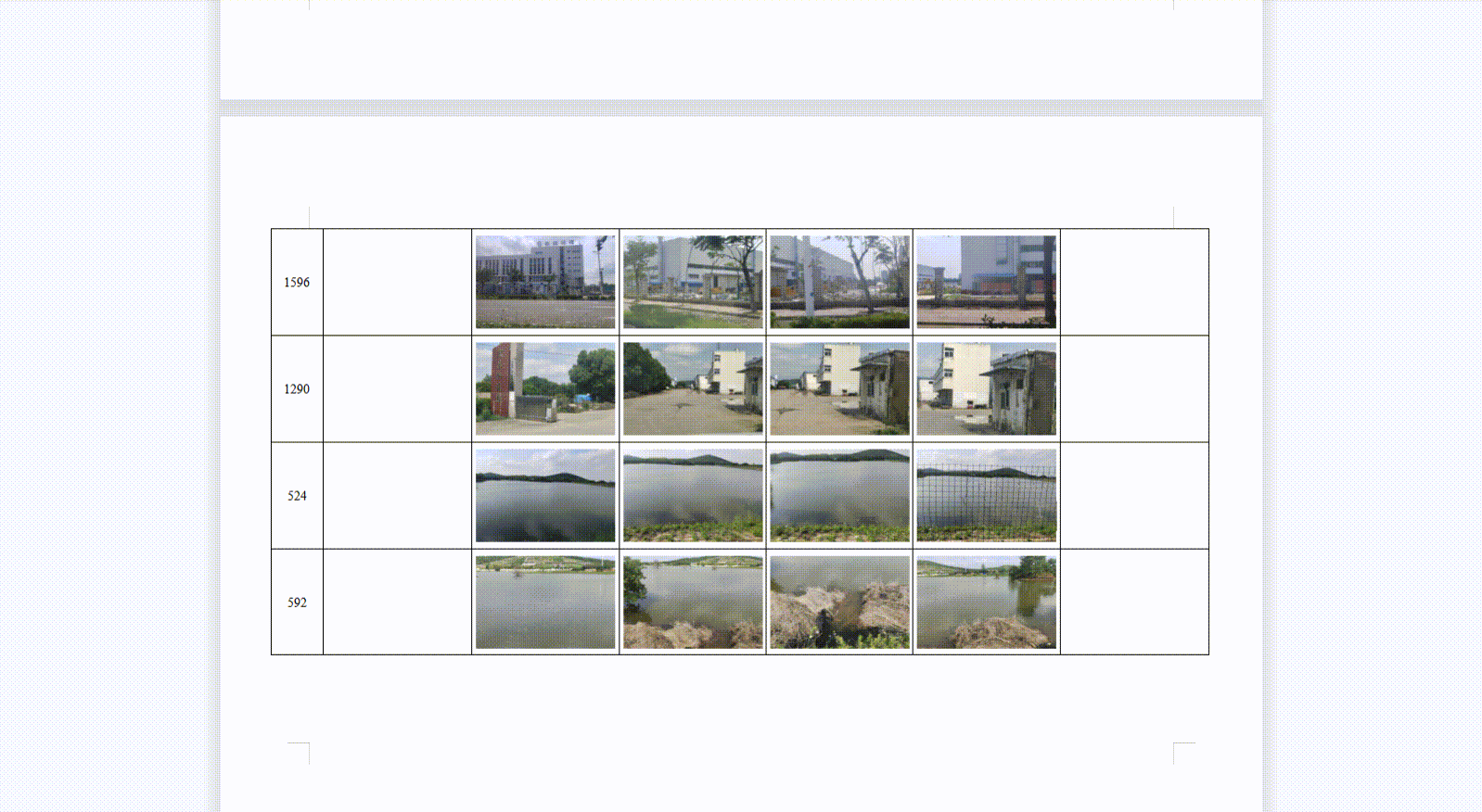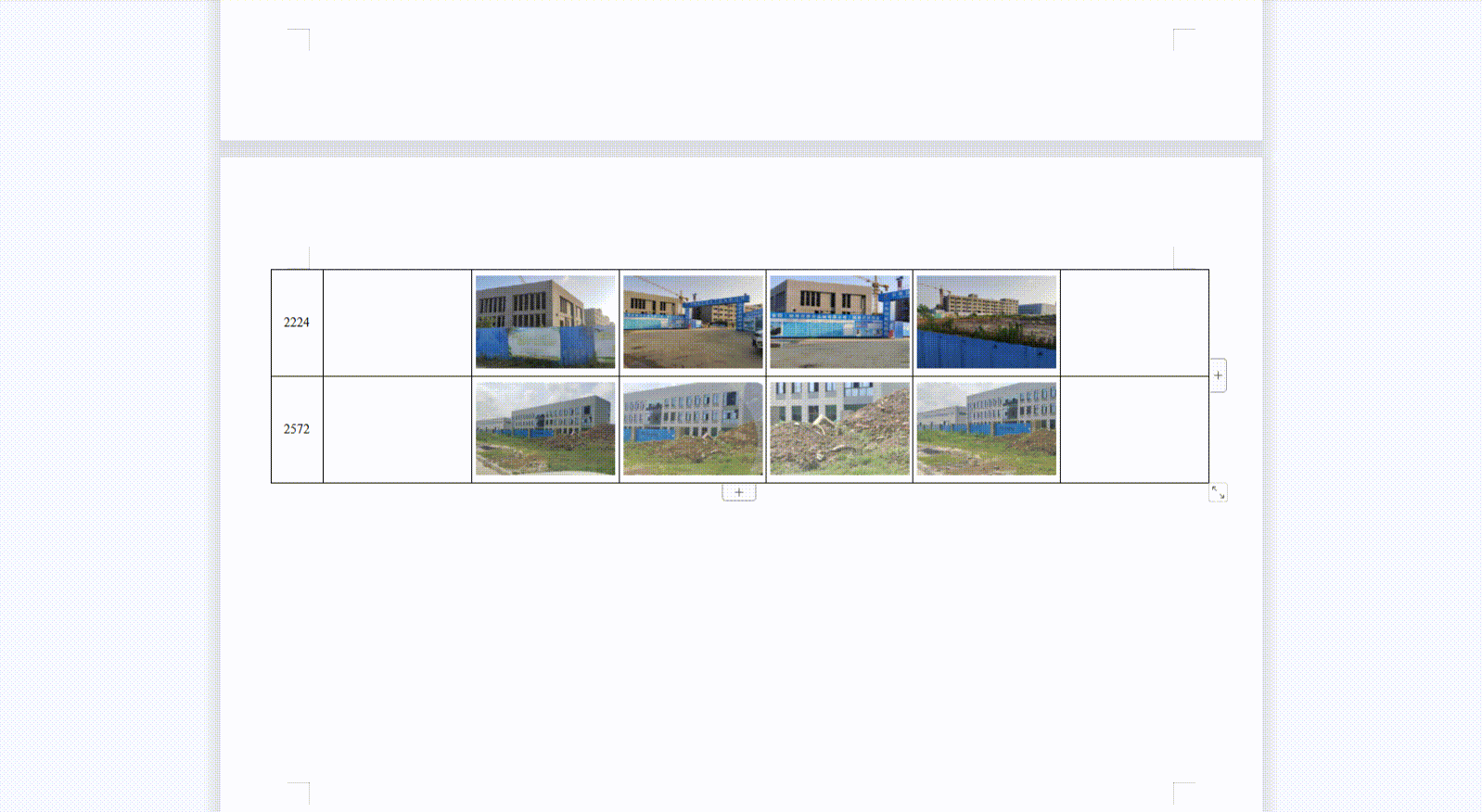
注:浏览器对于图片的处理和临时存储数量是有极限的,目前测试结果,最多存储13080张400KB的图片(约5G)。考虑到还有其他网页在共用浏览器缓存,图片总大小最好不要超过4G

若有收获,就点个赞吧
0 人点赞
