可以在浏览器中通过http://master:8088来访问Yarn的WEB UI,如下图: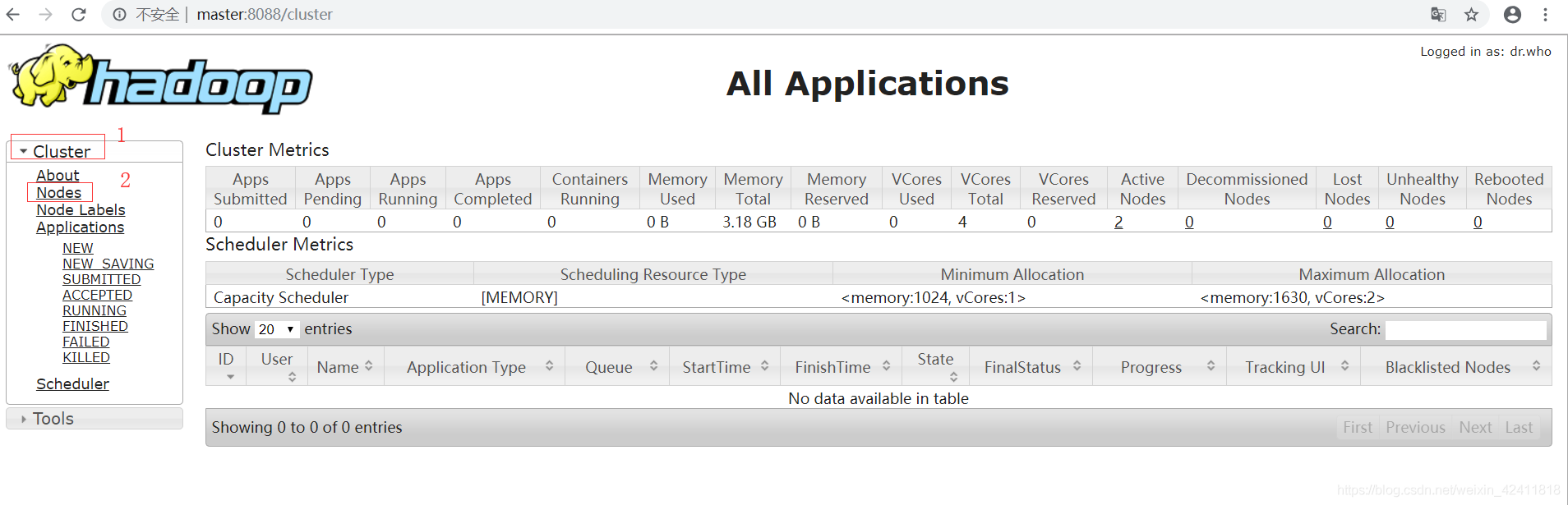
详细解释上图中标记为1(也就是cluster)和2(也就是Nodes)两个界面中和资源有关的信息
About
主要包含三块(Cluster Metrics、Scheduler Metrics、Cluster overview)
- Cluster Metrics:集群当前度量指标情况
- Apps Submitted:应用作业的提交个数
- Apps Pending:在所有队列总等待执行的作业个数
- Apps Running:正在运行的作业个数
- Apps Completed:已经运行完成的作业个数
- Containers Running:当前正在运行的容器个数
- Memory Used:集群中所有任务所耗用的内存
- Memory Total:yarn所能占用的最大内存(所有NodeManager管理的内存总和)
- Memory Reserved:预留内存,防止部分应用因为需要等待少部分内存而无限期等待情况
- VCores Used:正在运行作业所耗用的总虚拟CPU
- VCores Total:yarn所能占用的最大虚拟CPU
- Active Nodes:当前集群存活的节点个数,(其实就是NodeManager的个数)
- Decommissioned Nodes:集群退役的节点个数
- Lost Nodes:集群丢失的节点个数
- Unhealthy Nodes:集群运行状况不良的节点个数
- Rebooted Nodes:集群重启的节点个数
- Scheduler Metrics:集群调度信息
- Scheduler Type:集群使用的调度器类型(Apache默认Capacity CDH默认是Fair)
- Scheduling Resource Type:调度器资源类型内存
- Minimum Allocation:一个作业的最小内存为1G和1cpu核
- Maximum Allocation:一个作业的最大内存为8G和8cpu核
- Cluster overview:集群整体信息
- Cluster ID: 集群ID
- ResourceManager state: 集群ResourceManager的运行状态(STARTED表示正在运行)
- ResourceManager HA state: 只是表示ResourceManager的高可用接口正常,不表示ResourceManager已经是高可用了
- ResourceManager HA zookeeper connection state: 表示ResourceManager的高可不可
- ResourceManager RMStateStore: 集群ResourceManager的状态保存和还原接口类,参考链接(https://www.cnblogs.com/shenh062326/p/3562199.html)
- ResourceManager started on: 集群ResourceManager的启动时间
- ResourceManager version: 集群ResourceManager的版本
- Hadoop version: 集群hadoop的版本

对上面7个字段信息进行解释:
1.Active Nodes:表示Yarn集群管理的节点的个数,其实就是NodeManager的个数,我们集群有2个NodeManager
2.Memory Total:表示Yarn集群管理的内存的总大小,这个内存总大小等于所有的NodeManager管理的内存之和,每一个NodeManager管理的内存大小通过yarn-site.xml中的如下配置进行配置的:
<property><name>yarn.nodemanager.resource.memory-mb</name><value>1630</value><description>表示这个NodeManager管理的内存大小</description></property>
从配置中可以看到每一个NodeManager管理的内存大小是1630MB,那么整个Yarn集群管理的内存总大小就是1630MB 2 = 3260MB约等于3.18GB,也就是我们看到的Memory Total
3.*Vcores Total:表示Yarn集群管理的cpu的虚拟核心的总数,这个大小等于所有的NodeManager管理的虚拟核心之和,每一个NodeManager管理的虚拟核心数是通过yarn-site.xml中的如下配置进行配置的
<property><name>yarn.nodemanager.resource.cpu-vcores</name><value>2</value><description>表示这个NodeManager管理的虚拟核心个数</description></property>
从配置中可以看到每一个NodeManager管理的虚拟核心数是2,那么整个Yarn集群管理的虚拟核心的总数就是2 2 = 4,也就是我们看到的Vcores Total
4.Scheduler Type:表示资源分配的类型,也就是我Hadoop-yarn安装文章中说到的三中资源调度
5.Minimum Allocation:最小分配资源,就是说当一个任务向Yarn申请资源的时候,Yarn至少会分配
6.*Maximum Allocation
Nodes
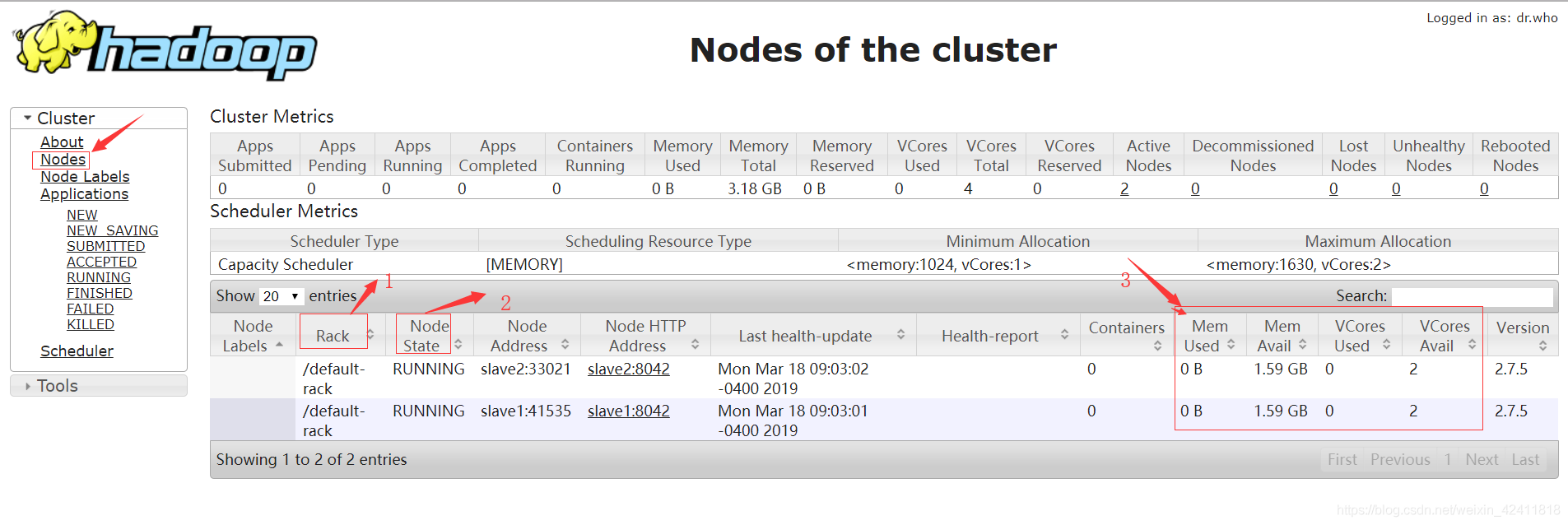
上面是Yarn集群管理的两个NodeManager的状态信息,分别如下:
1.Rack:表示NodeManager所在的机器所在的机架
2.Node State:表示NodeManager的状态
3.Node Address: NodeManager的ip地址和访问端口
4.Node HTTP Address:NodeManager的web应用HTTP访问地址(可以点进去查看该节点的信息,后续讲解)
5.Last health-update:节点最近心跳时间
6.Health-report:心跳报告的存储路径
7.Containers:节点内正在运行的Containers个数
8.Mem Used:表示每个NodeManager已经使用了的内存大小。
9.Mem Avail:表示每个NodeManager还剩多少可以使用的内存大小。
10.VCores Used:表示每个NodeManager已经使用了的VCores数量。
11.VCores Avail:表示每个NodeManager还剩多少可以使用的VCores数量。
12.Version:版本信息
点击一个Node Address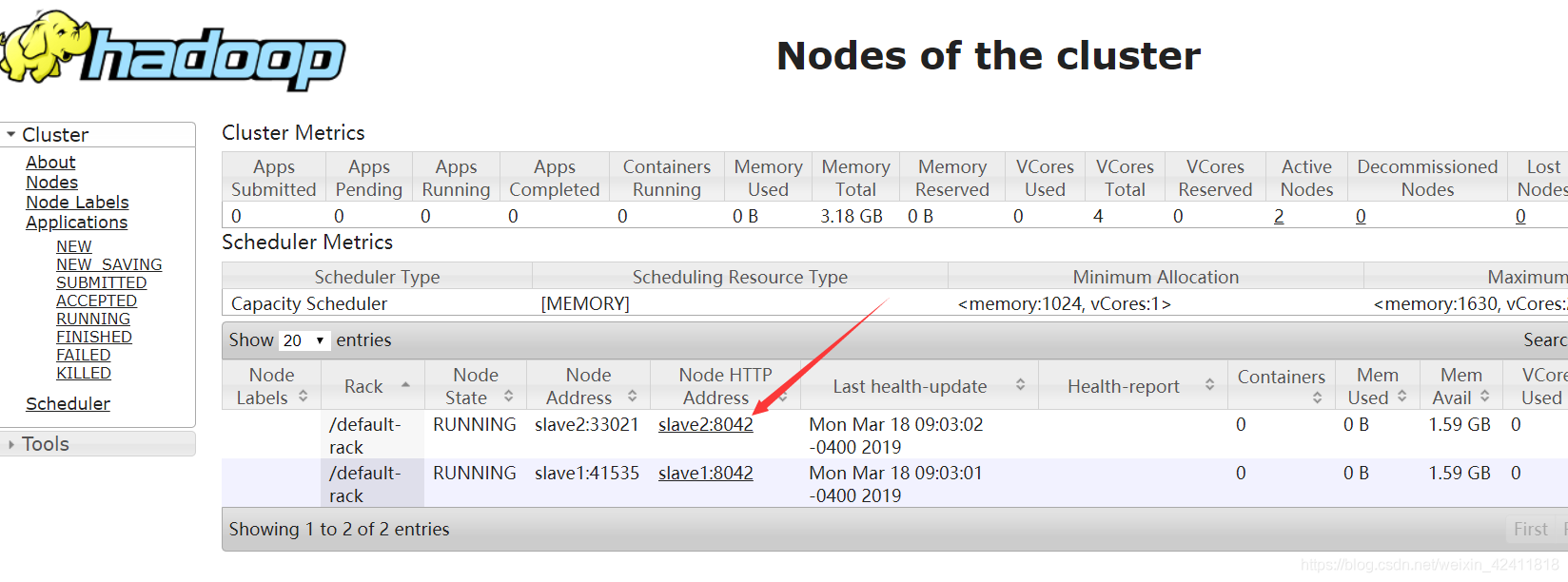
进入到如下的界面: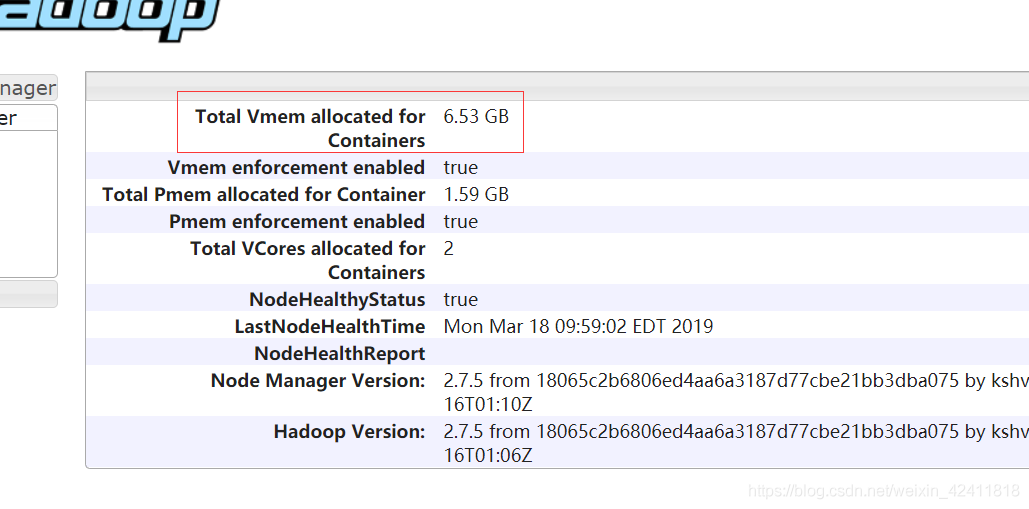
这个界面上的信息是slave2上的NodeManager的详细信息,其中,Total Vmem allocated for Containers表示这个NodeManager管理的虚拟内存的大小,虚拟内存大小由yarn-site.xml中的配置来设置的:
<property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>4.1</value><description>表示这个NodeManager管理的虚拟内存和物理内存大小的比例</description></property>
上面配置yarn.nodemanager.vmem-pmem-ratio就是虚拟内存和物理内存大小的比例为4.1,也就是说虚拟内存的大小是物理内存大小的4.1倍,所以虚拟内存大小是1630MB * 4.1 = 6683MB,约等于6.53GB
Node Labels
节点标签
Applications
集群历史和当前运行的job概述,Applications下面有job在Yarn的各种状态(NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED)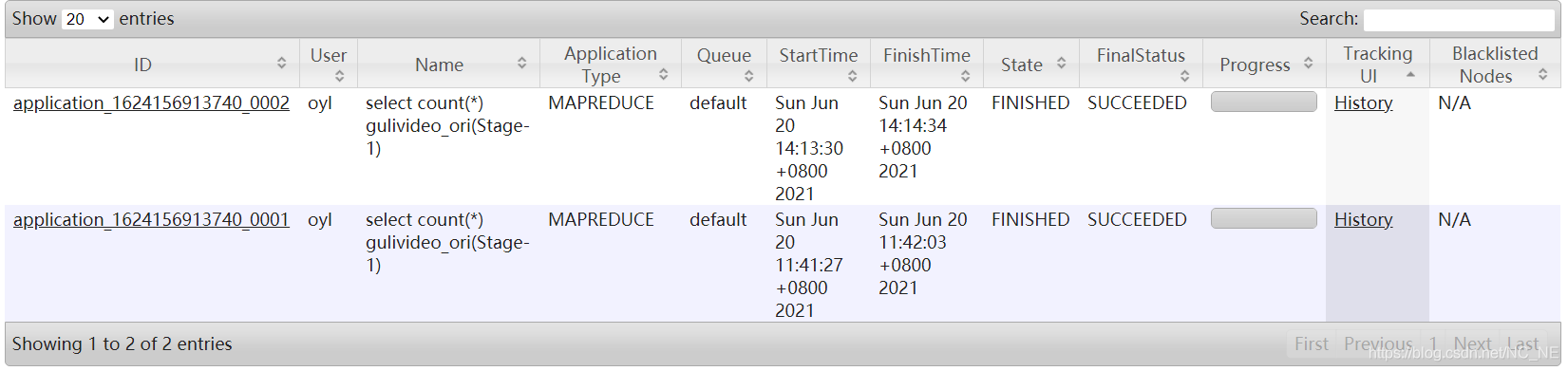
各种状态显示的界面都是一样的,如上图就用已完成的作业来描述相关信息
ID:当前应用的ID
User:提交应用的用户
Name:作业内容(sql语句)
Application Type:计算引擎类型(mapreduce、tez、spark)
Queue:应用所提交的队列
Start Time:应用执行的开始时间
Finish Time:应用执行完成时间
State:当前应用的状态
FinalStatus:当前应用的最终状态
Progress:运行时候显示的进度条
Tracking UI:历史追踪连接(点进去能够显示当前应用的详细信息,后续讲解)
Blacklisted Nodes:黑名单节点
Scheduler
Yarn的调度器相关的信息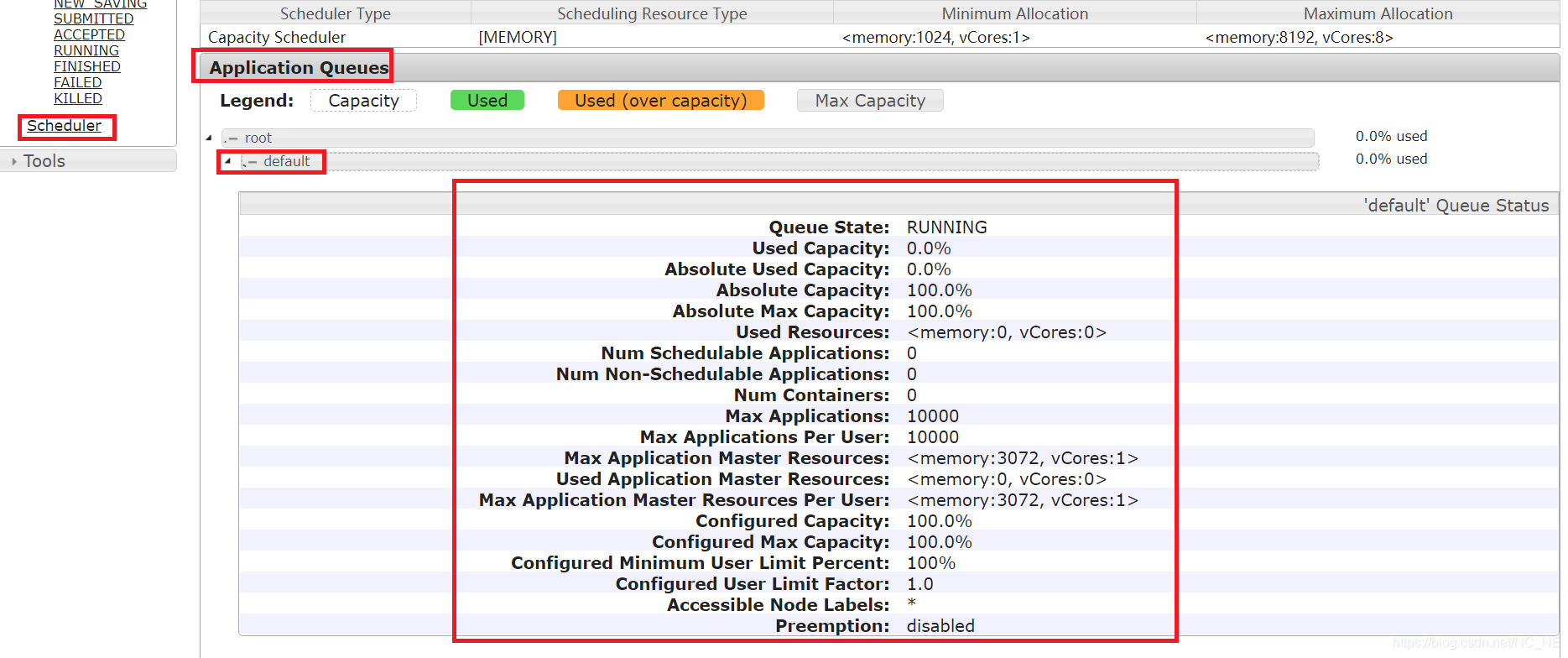
Queue State: 队列运行状态,Running表示正常运行
Used Capacity: 已使用资源占队列配置值的百分比
Absolute Used Capacity: 已使用资源占集群的百分比
Absolute Capacity: queue 至少可以使用系统资源占集群的百分比
Absolute Max Capacity: queue 最多可以使用系统资源占集群的百分比
Used Resources: 已使用的memory和CPU
Num Schedulable Applications: 正在被调度的app应用个数
Num Non-Schedulable Applications: 没有被调度的app应用个数
Num Containers: 已启用的container容器数量
Max Applications: 最大可运行的应用数量(处于pending和running状态的
Max Applications Per User: 每个user最多可以运行的应用数量
Max Application Master Resources: 该queue使用的最大的内存和core
Used Application Master Resources: 该queue已经被使用的内存和core
Max Application Master Resources Per User:每个user最多可以使用该queue的最大内存和core
Configured Capacity: 配置该队列capacity
Configured Max Capacity: 配置该队列最大可使用capacity
Configured Minimum User Limit Percent: 每个user最多可以使用队列资源的百分比
Configured User Limit Factor: 队列中的用户允许占用队列值的多少,默认值是0.0~1如果将值设置为1,它代表:最大可以占用整个队列资源,如果将值设置为2,它代表:允许队列所占资源增长到最多为队列容量的两倍
Accessible Node Labels: 标记节点
Preemption: 多用户是否抢占队列
Tool菜单
Configuration:集群所有的配置参数信息,包含(yarn-site.xml,mapred-default.xml,core-site.xml,hdfs-site.xml)
Local logs:查看本地的日志信息
Server stacks:服务的堆栈信息
Server metrics:服务指标信息
某个任务详细日志
1.1、任务日志在哪
就在Applications下的几个状态中,只要你是提交到yarn来管理的任务那一定在这几个状态中的某一个,所以弄清楚这几个状态的日志信息那我们就能知道某个任务的运行状况了。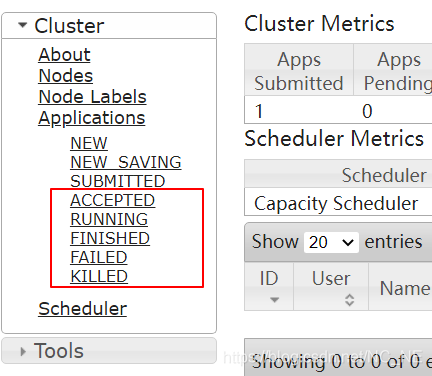
在实际工作中NEW、NEW_SAVING、SUBMITTED这三个用到的概率还是非常低的,而ACCEPTED、RUNNING、FINISHED、FAILE、KILLED这五个那是经常使用的,所以我们重点关注:
ACCEPTED:接受状态,已经被队列(queue)接受,但是还没有开始执行。如果生产中有任务一直停留在这个状态,那就可能是队列资源是不充足。
RUNNING:运行状态,获得我集群资源正在计算,我们也看一下点进去查看运行的日志。
FINISHED:完成状态,表示任务运行完成。
FAILE:失败状态,表示任务运行失败,这个时候我们就应该点进去查看日志寻找失败的原因。
KILLED:被杀死状态,这个一般都是人为强制kill的
。
1.2、某个任务Finished状态详解
点击FINISHED如图: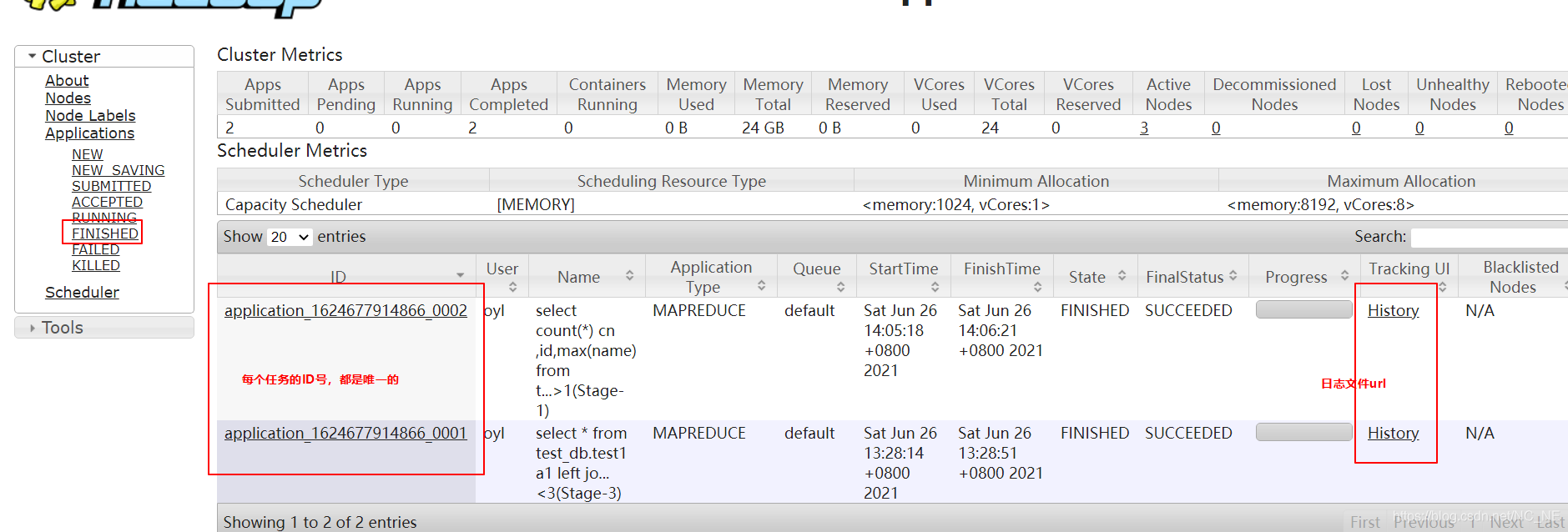
点击History就可以跳转到当前任务详细信息界面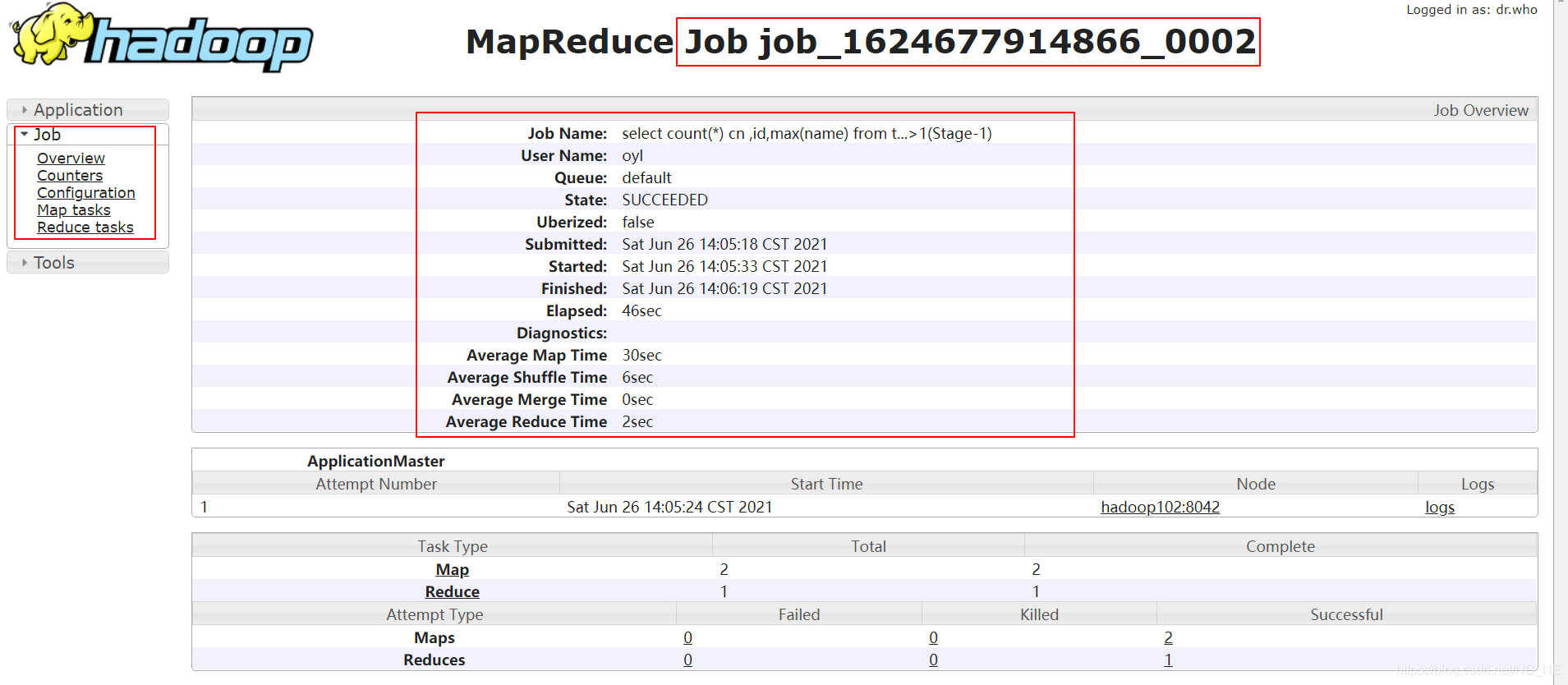
看到三个重要的框,左边框Job是当前任务信息的菜单,每一个都是非常重要的对于了解当前任务的运行情况,我们详细讲解。
1.2.1、Overview
也就是我们上面看到的这张图,当前任务的概况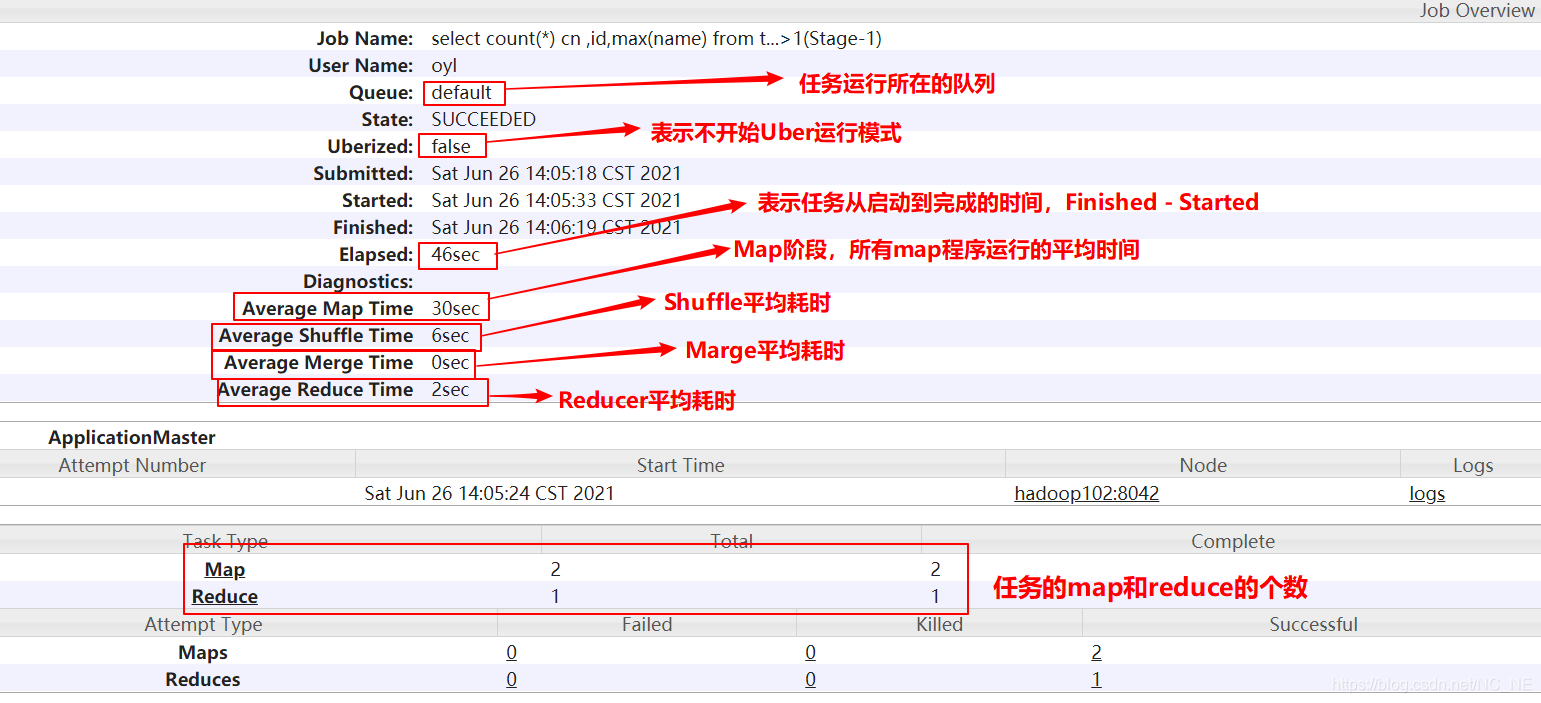
1.2.2、Counters
作业计数器,表示hive作业在Input,Map,Shuffle,Reduce,Output等各个阶段的定量数据,我们能够非常直观的看到任务处理的数据量,处理耗时和使用资源,这个非常有利于开发定位问题和后期性能优化
我们点击Counters链接,可以看到任务计数器的页面,分为如下7个部分(因为图太长我们分段讲解):
1、File System Counters:文件系统计数器

注意:
HDFS: Number of read operations:表示一个作业内读取HDFS的次数,读取HDFS操作都是在map阶段,所以读取次数等于所操作表在Hdfs中的文件个数
HDFS: Number of write operations:表示一个作业写入HDFS的次数,写HDFS操作一般只发生在reduce阶段,所以写入次数就等于HDFS 的文件个数
FILE: Number of read operations:表示一个作业内读取本地文件的次数,读取本地文件一般只发生在reduce阶段读取数据操作(如果数据源来自本地那么map阶段会被统计到)
FILE: Number of write operations:表示一个作业写入本地文件次数,写入本地文件发生在shuffle阶段,还有reduce拉取数据阶段。
2、Job Counters:作业计数器
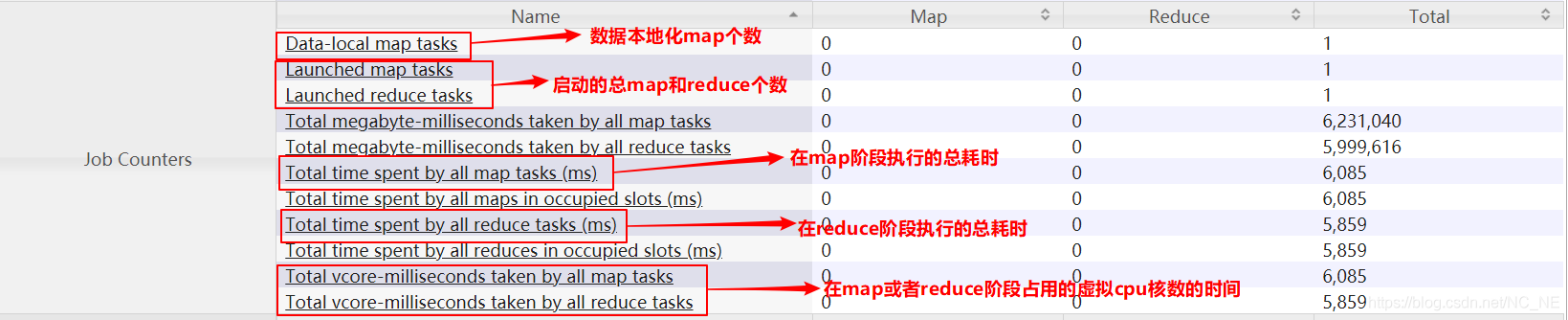
3、Map-Reduce Framework:MapReduce框架计数器
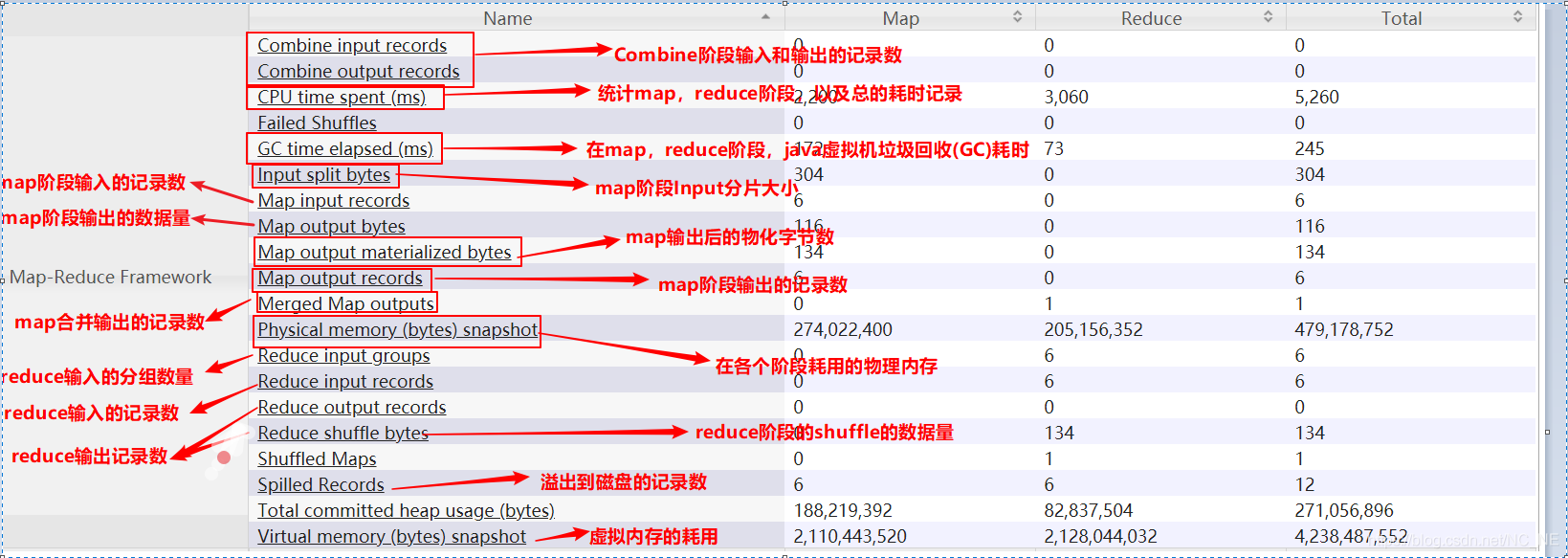
4、HIVE:hive计数器

5、Shuffle Errors:shuffle错误计数器
6、File Input Format Counters:文件输入格式的计数器
7、File Output Format Counters:文件输出格式计数器

1.2.3、Configuration
就是任务提交的时候的xml配置文件,里面都是一些相关的参数配置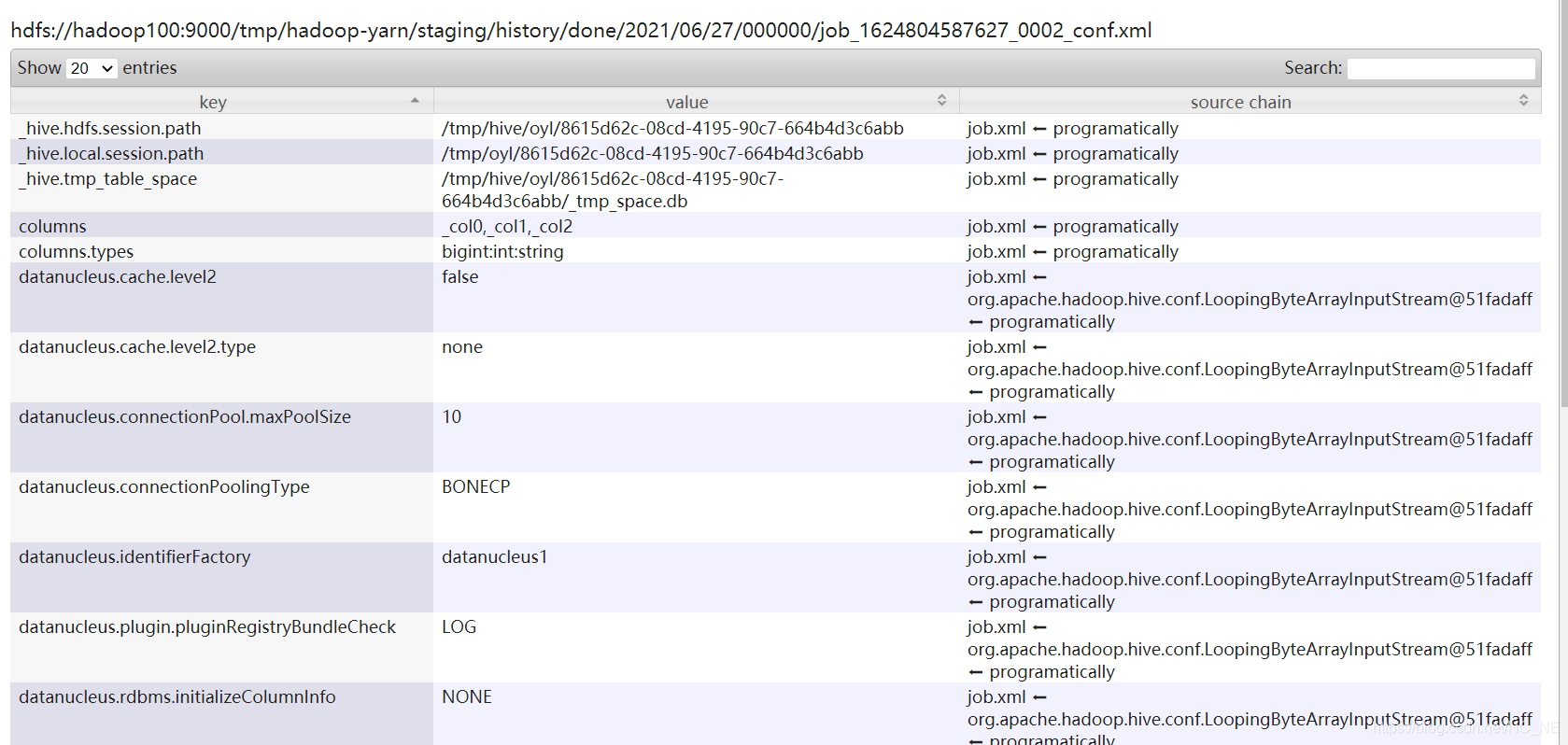
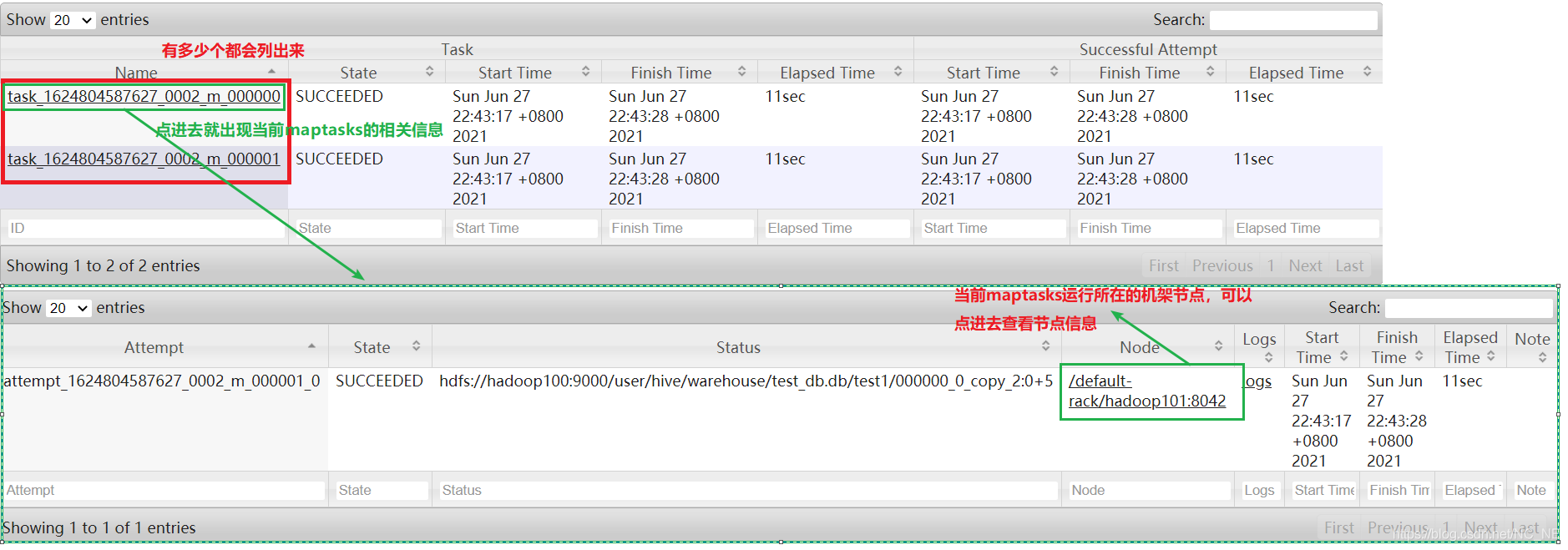
1.2.4、Map tasks:当前任务的map tasks的详细信息
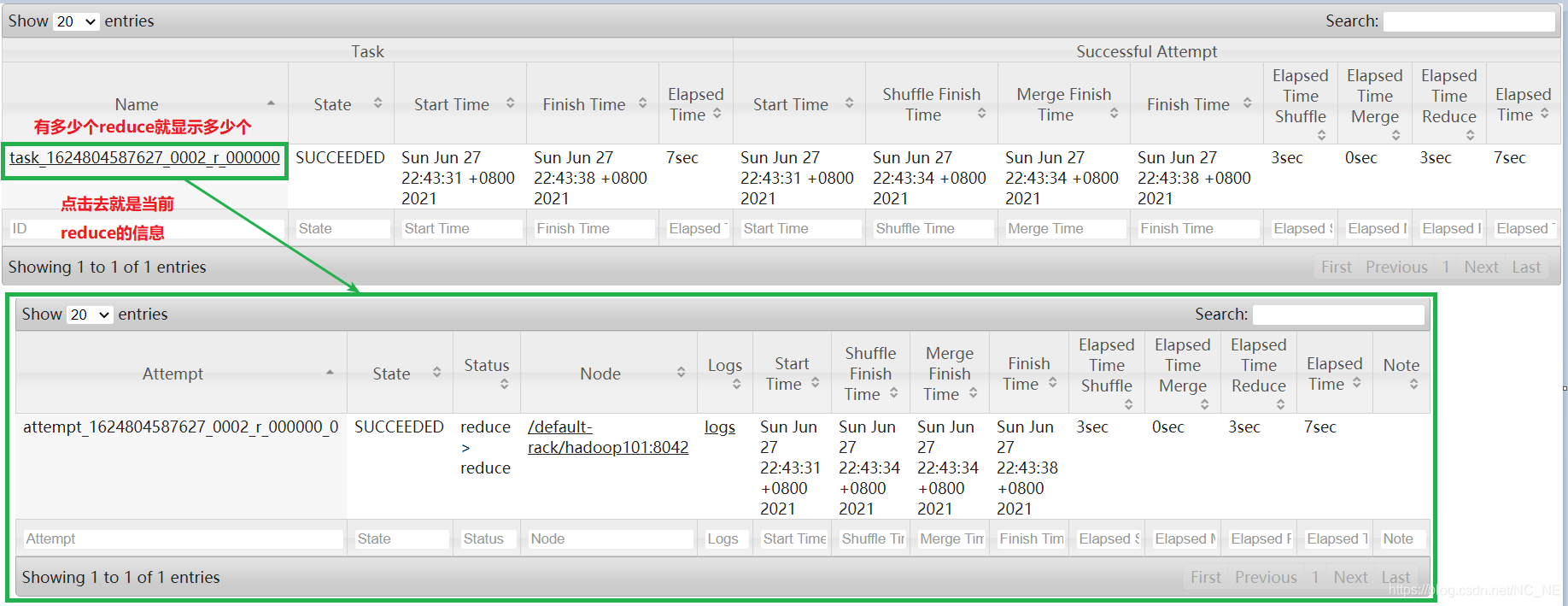
1.2.5、Reduce tasks:当前任务的reduce的详细信息

若有收获,就点个赞吧
0 人点赞
