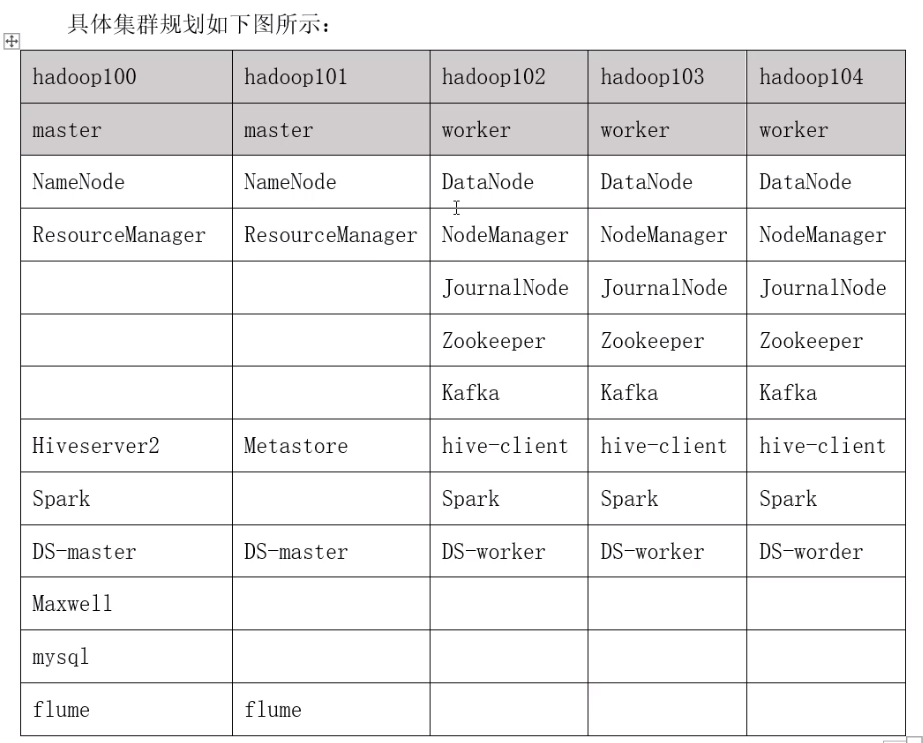
一、集群环境

二、Yarn配置


三、Spark配置
3.1、Executer配置
3.1.1、ExecuterCPU配置

3.1.1、Executer内存
内存模型:分3个部分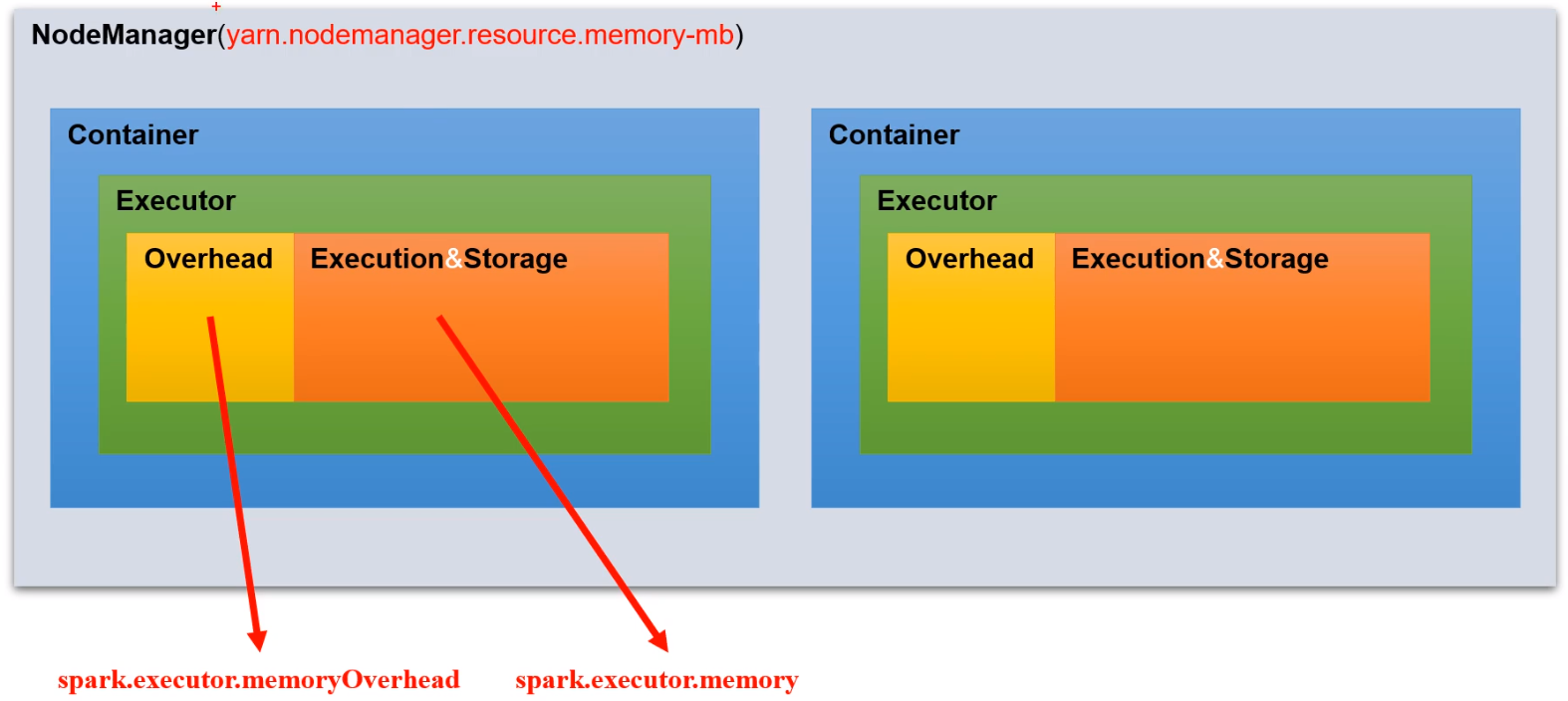


先计算每个节点可以运行多少个Executer,nodeManager内存 / Executer个数 = Executer内存
3.1.1、Executer个数




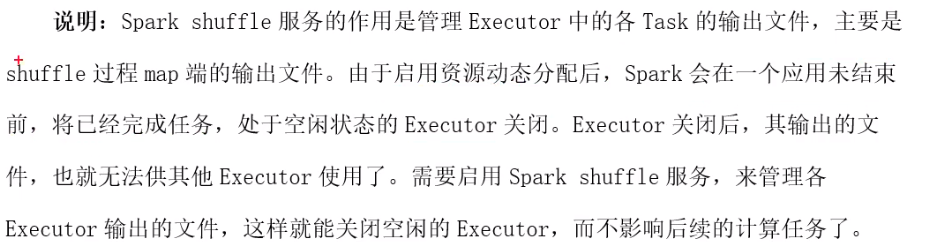
3.2、Driver配置


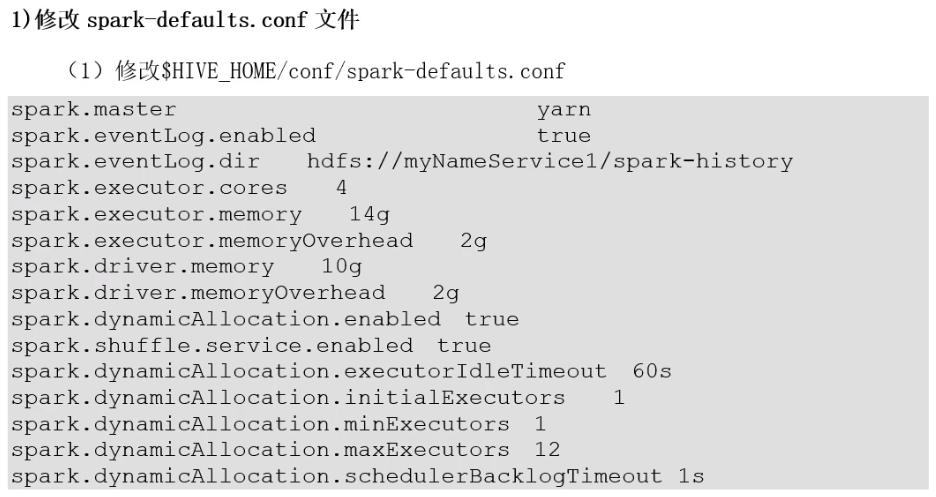
3.3、配置实操


四、分组聚合优化
测试SQL: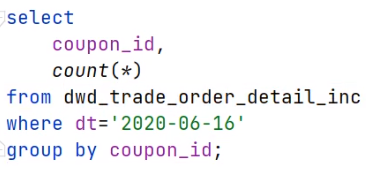
desc formatted dwd_trade_order_detail_inc;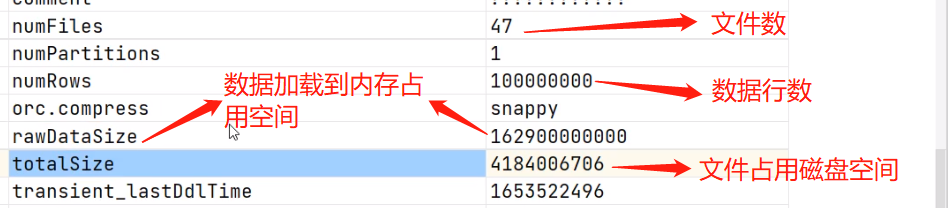
优化前执行计划: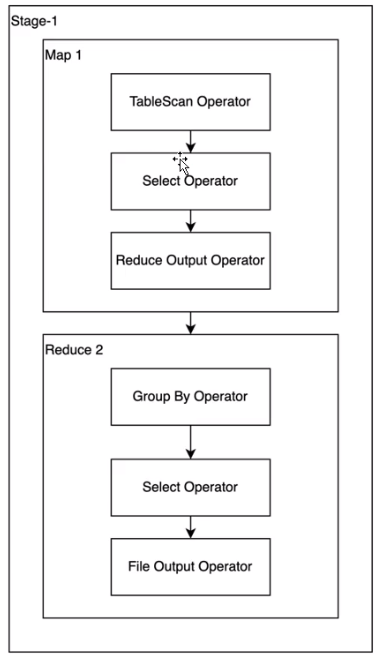
优化思路:
可以看到只有一个shuffle,减少该部分shuffle即可

五、Join优化
5.1、Join算法概述

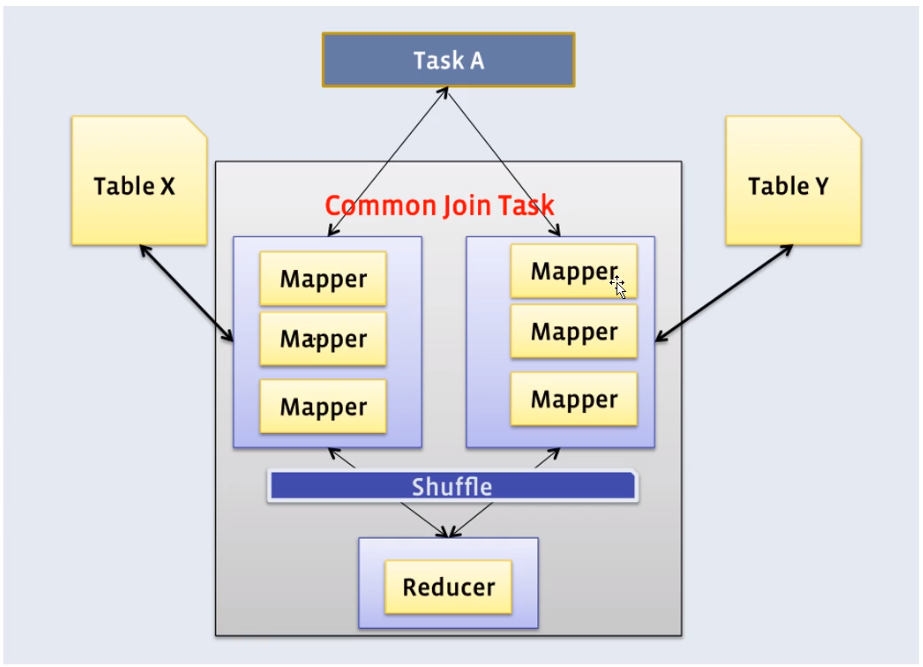
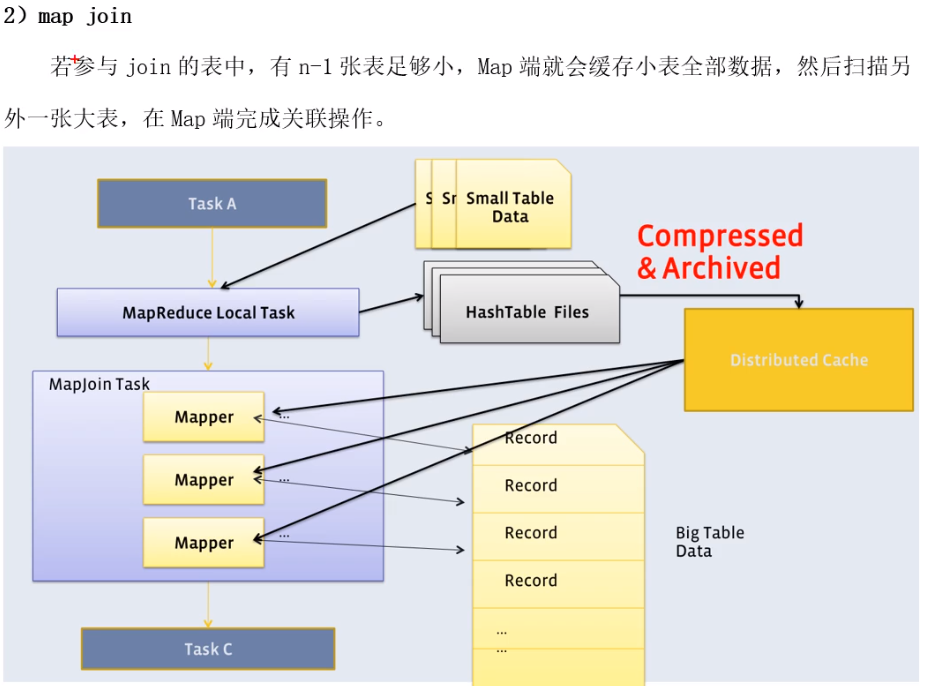

5.2、MapJoin优化
测试SQL: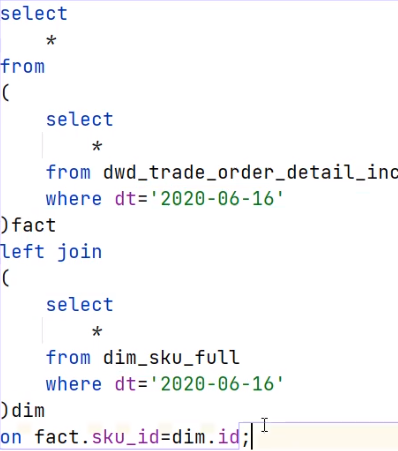
优化前执行计划:
有一个Stage,有Map和Reduce之间的Shuffle阶段
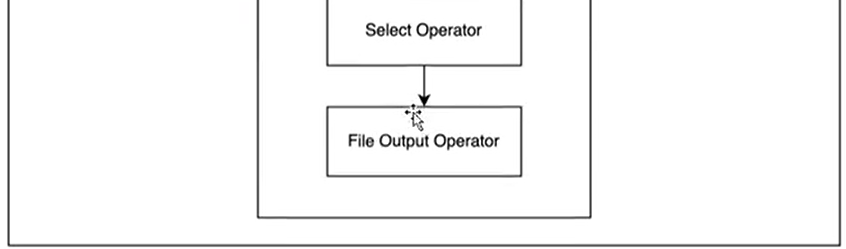
优化思路:
优化后执行计划:
有两个Stage,但是都是只有map阶段。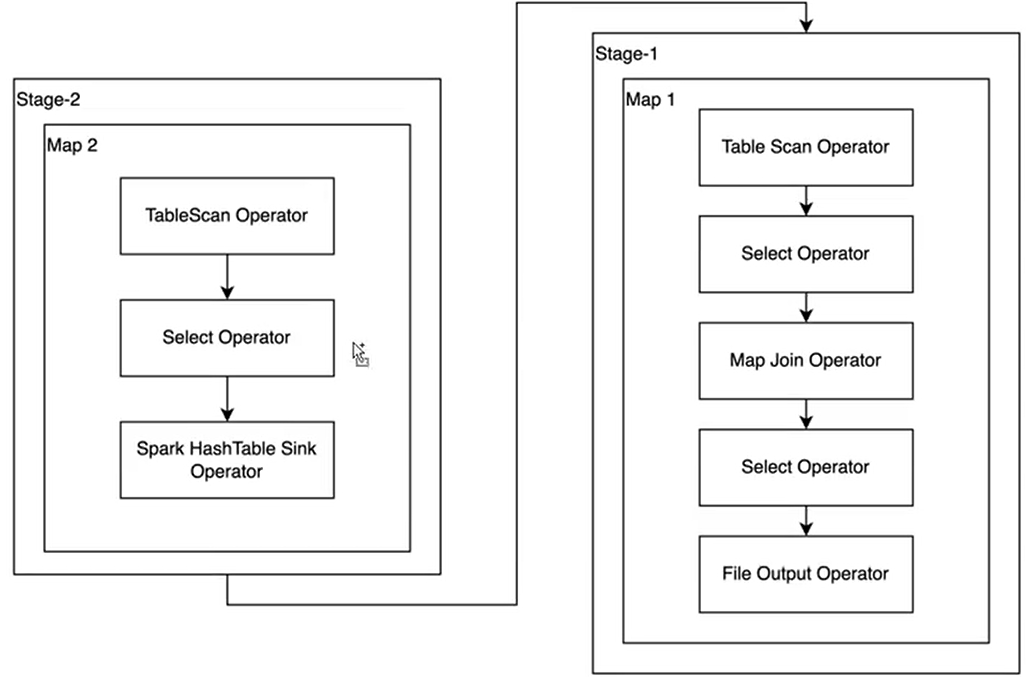
六、数据倾斜优化
6.1、数据倾斜说明

6.2、分组聚合导致的数据倾斜
测试SQL: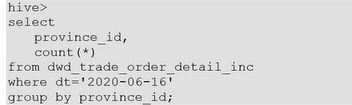
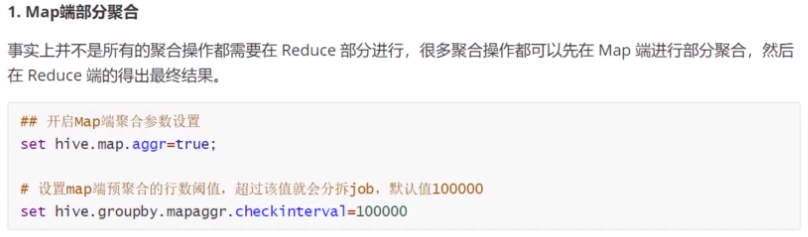

6.3、Join导致的数据倾斜
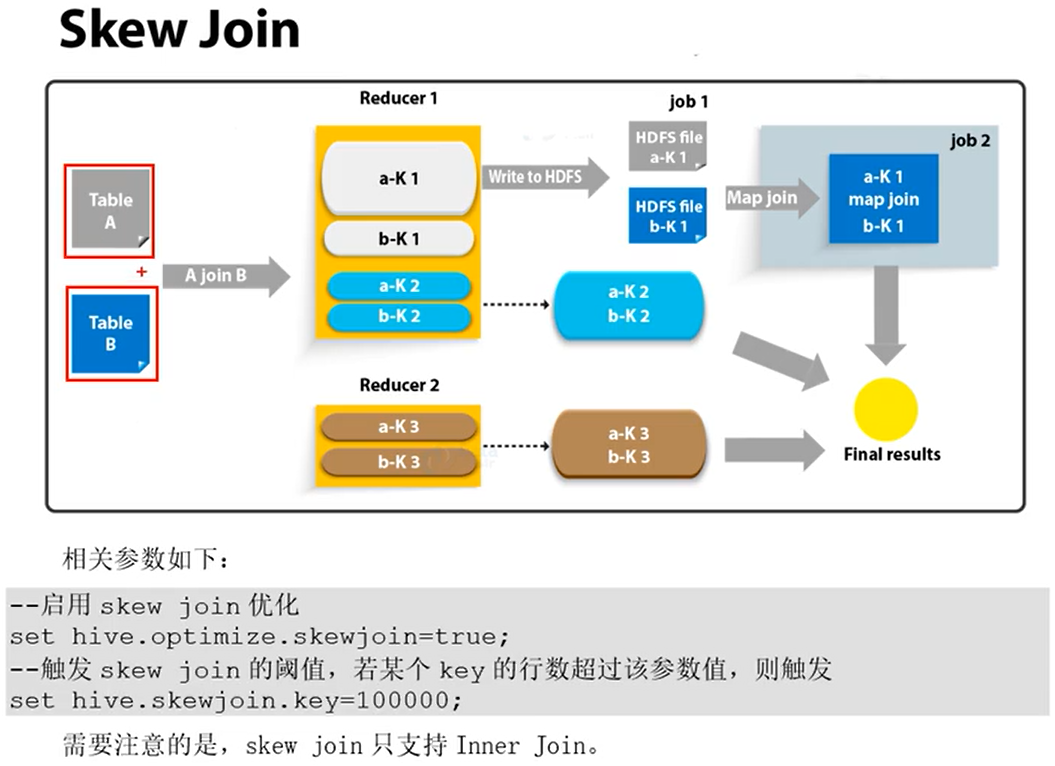

整体思路是使用独立的作业和mapjoin来处理倾斜的键
在执行JOIN的过程中,会将一个表中的大key(也就是倾斜的那部分数据,判断是否倾斜由配置项hive.skewjoin.key指定,默认是100000)输出到一个对应的目录中,同时该key在其他表中的数据输出到其他的目录中(每个表一个目录)。整个目录结构类似下面这样:
- T1表中的大key存储在目录 dir-T1-bigkeys中,这些key在T2表的数据存储在dir-T2-keys中,这些key在T3表的数据存储在dir-T3-keys中,以此类推。。。
- T2表中的大key在T1中的数据存储在 dir-T1-keys,T2表中的大key存储在目录dir-T2-bigkeys中,这些key在T3表的数据存储在dir-T3-keys中,以此类推。。。
- T3表中的大key在T1中的数据存储在 dir-T1-keys,这些key在T2表的数据存储在dir-T2-keys中,T3表中的大key存储在目录dir-T3-bigkeys中,以此类推。。。
对于每个表,都会单独启动一个mapjoin作业处理,输入的数据,就是该表的大key的目录和其他表中这些key对应的目录,对于上面情况基本就是会启动三个map join作业(一行对应一个)
对于每个表中每一个倾斜键(skew key一个表中可能会有多个倾斜键)首先会写入到本地的一个临时文件中,最后将这些文件上传到HDFS中。
测试验证
在开启倾斜优化后,会在task(hive on spark)中看到如下的日志信息:
上面的日志说明,hive对这些超过了hive.skewjoin.key配置项指定阈值的key从本地拷贝到了一个HDFS目录中,这一点和文章开头的分析一致
然后看一下,对应的HDFS目录中的结构,可以看到两张表的数据,大表的数据会划分到了多个目录中,另一张较小的表的目录结构与大表的目录结构一致
小表中每个子目录中数据是完全一样的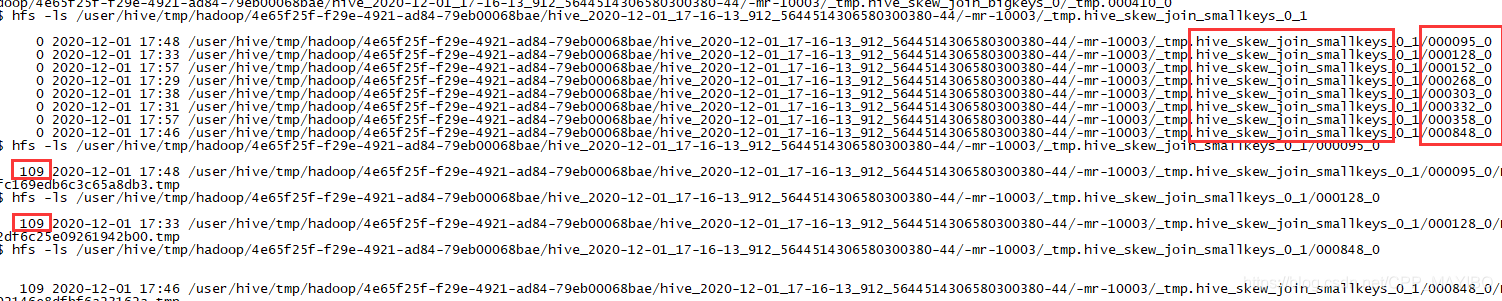
另外从task的执行日志可以看到其使用了skewjoin优化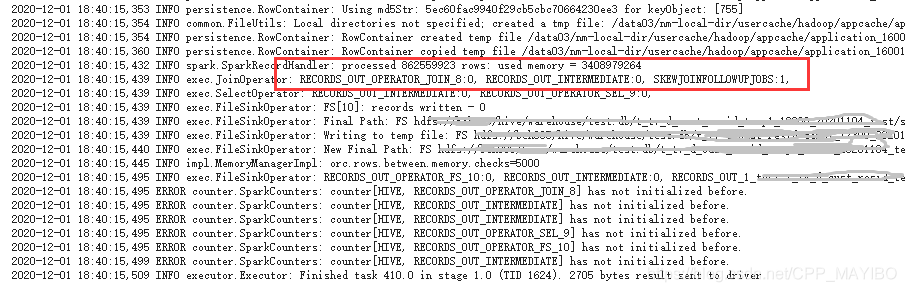
七、并行度优化

7.1、Map端的并行度

7.2、Reduce端的并行度

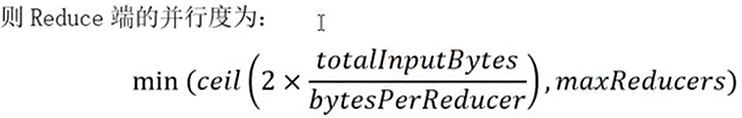 spark估算策略,x2是为了更多地创建Task,保证并行度。
spark估算策略,x2是为了更多地创建Task,保证并行度。
totalInputBytes:
但是开启了该参数会对元数据库压力比较大
八、小文件合并优化



若有收获,就点个赞吧
0 人点赞
