一、hdfs调优以及yarn参数调优
1.1、HDFS参数调优hdfs-site.xml
- dfs.namenode.handler.count=20*log2(Cluster Size):调整namenode处理客户端的线程数,比如集群规模为8台时,此参数设置为60;NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。设置该值的一般原则是将其设置为集群大小的自然对数乘以20。
- 编辑日志存存储路径dfs.namenode.edits.dir设置镜像文件存储路径dfs.namenode.name.dir尽量分开,达到最低写入延迟
- 元数据信息fsimage多目录冗余存储配置
1.2、Yarn参数调优yarn-site.xml
- 根据实际调整每个节点和单个任务申请内存值
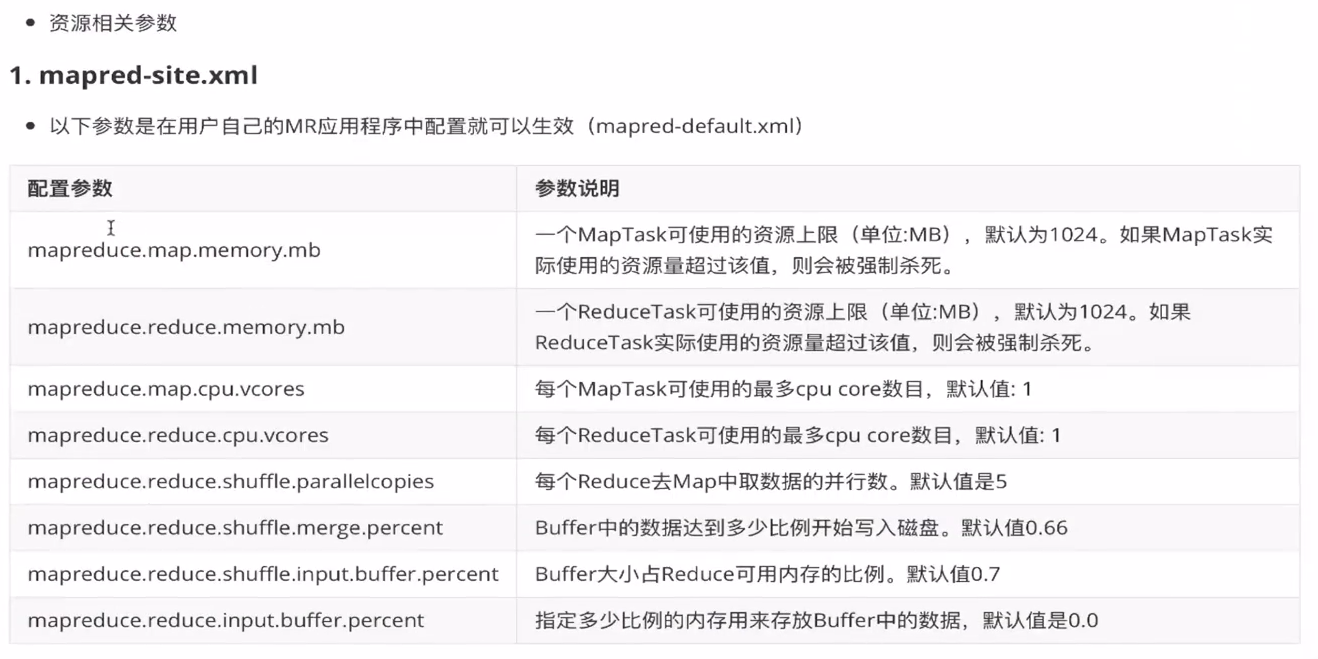
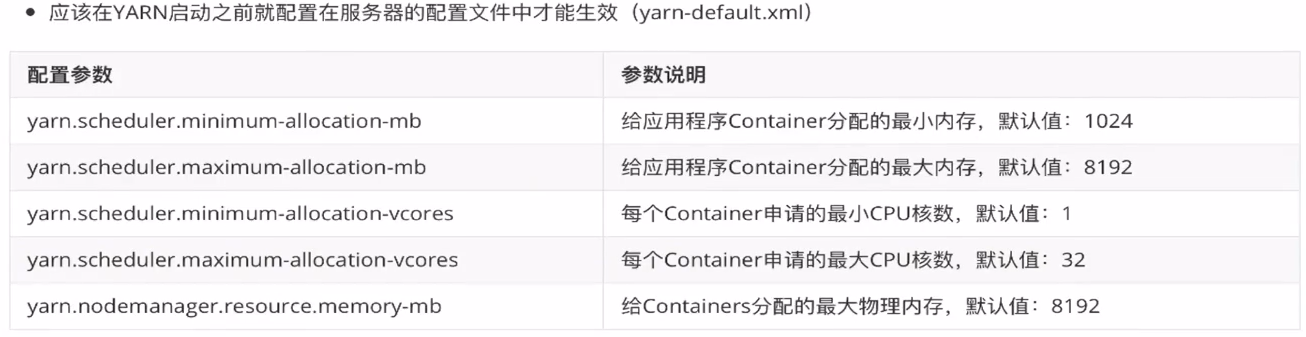
- yarn.nodemanager.resource.memory-mb:表示该节点上YARN可使用的物理内存总量,默认是8192MB,(注意:如果节点的内存资源不够8GB,则需要减小这个值,而Yarn不会智能的探测节点的物理内存总量)。
- yarn.scheduler.maximum-allocation-mb:单个任务可申请的最多物理内存量,默认是8192MB。
- Hadoop宕机
- 如果MR造成系统宕机,此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。降低参数:yarn.scheduler.maximum-allocation-mb 的值
- 如果写入文件过量造成NameNode宕机,那么调高kafka的存储大小,控制从kafka到HDFS的写入速度,高峰期的时候用kafka进行缓存,高峰期过去数据同步会自动跟上。
二、MR运行慢的主要原因可能性有哪些
2.1、计算机性能:CPU、内存、磁盘健康、网络
2.2、I/O操作优化:数据倾斜、map和reduce数设置不合理、map运行实际过长、小文件过多、大量不可分割的超大文件、spill次数过多、merge次数过多。
三、mapreduce的优化方法
3.1、数据输入阶段
- 合并小文件:在执行mr任务前将小文件进行合并,因为大量的小文件产生大量的map任务,会占用过多资源,导致运行缓慢。
- 采用CombineTextInputFormat来作为输入,解决输入端大量小文件场景。
3.2、MapTask运行阶段
- 减少spill溢写次数:通过调整 mapreduce.task.io.sort.mb 及 mapreduce.map.sort.spill.percent 参数的值,增大出发spill的内存上限,减少spill次数,从而减少磁盘io的次数。
- 减少merge的合并次数:调整 mapreduce.task.io.sort.factor 参数,增大merge的文件数,减少merge的次数,从而缩短mr处理时间。
- 在map之后,不影响业务逻辑的情况下,先进行combine操作,减少IO操作。
3.3、ReduceTask运行阶段
- 设置合理的map、reduce个数:两个数值都不能太小,也不能太大
- 设置map、reduce共存
- 调整mapreduce.job.reduce.slowstart.completedmaps参数(默认0.05),是map运行到一定程度后,reduce也开始运行,减少reduce的等待时间
- 比如调整到0.8。
- 规避使用reduce
- 因为reduce在用于连接数据集的时候会产生大量的网络消耗
- 合理设置reducer端的buffer
- 默认情况下,数据达到一定阈值的时候,Buffer中的数据会写入磁盘,然后reduce会从磁盘中获得所有的数据。即Buffer于reduce没有关联的、中间多次写磁盘、读磁盘的过程。那么可以通过调整参数,使得Buffer中的数据可以直接输送到 reduce,从而减少IO开销;mapreduce.reduce.input.buffer.percent 默认为0.0,当值大于0的时候,会保留指定比例的内存读Buffer中的数值直接拿给reducer使用。
四、IO传输阶段
- 进行数据压缩:减少网络IO的数据量,安装snappy和lzo的压缩编码器
- 使用SequenceFile二进制文件
五、数据倾斜问题
- 数据倾斜问题
- 数据频率倾斜:某一分区的数据量要远远大于其他分区
- 数据大小倾斜:部分记录的大小远远大于平均值
- 减少数据倾斜的方法
- 方法1:抽样和范围分区:对原视数据进行抽样,根据抽样数据集,预设分区边界值
- 方法2:自定义分区:基于map输出key的背景知识,进行自定义分区。
- 方法3:combine:减少数据倾斜,聚合并精简数据
- 方法4:采用map join,尽量避免reduce join
六、常见调优参数


若有收获,就点个赞吧
0 人点赞
