每个文件、目录、块都大概有150字节的元数据,文件数量的限制也由namenode内存大小决定,如果小文件过多则会造成namenode的压力过大,且HDFS能存储的数据总量也会变小。
小文件治理的方式,之前已经使用JavaAPI方式演示过,下面讲解其它方式。
一、HAR文件方案
HAR文件方案的本质是启动Mapreduce程序,所以需要启动yarn
通过命令即可完成:
hadoop archive -archiveName <NAME>.har -p <parent path> [-r <replication factor>]<src>* <dest>/*-archiveName <NAME>.har: 归档文件(许多小文件形成的一个大文件)-p <parent path>:小文件的父级目录[-r <replication factor>]:可选,副本个数<src>* <dest>:归档文件存放的路径*/
案例:
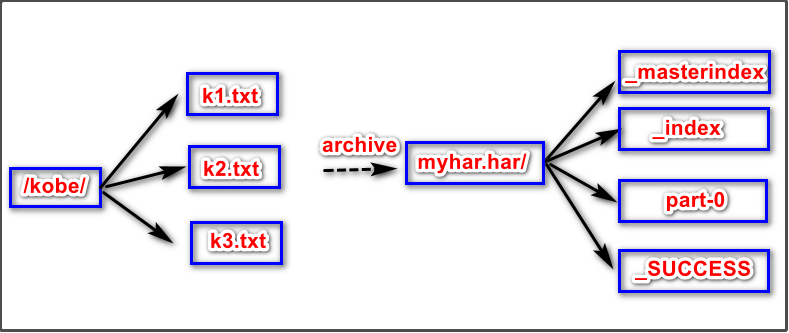
第一步:创建归档文件cd /kkb/install/hadoop-2.6.0-cdh5.14.2/binhadoop archive -archiveName myhar.har -p /user/hadoop /user第二步:查看归档文件内容[hadoop@node01 bin]$ hdfs dfs -ls -R har:///myhar.har/-rw-r--r-- 3 hadoop supergroup 0 2020-02-10 23:34 har:///myhar.har/k1.txt-rw-r--r-- 3 hadoop supergroup 0 2020-02-10 23:34 har:///myhar.har/k2.txt-rw-r--r-- 3 hadoop supergroup 0 2020-02-10 23:35 har:///myhar.har/k3.txt[hadoop@node01 bin]$ hdfs dfs -ls -R /myhar.har-rw-r--r-- 3 hadoop supergroup 0 2020-02-10 23:35 /myhar.har/_SUCCESS-rw-r--r-- 3 hadoop supergroup 326 2020-02-10 23:35 /myhar.har/_index-rw-r--r-- 3 hadoop supergroup 23 2020-02-10 23:35 /myhar.har/_masterindex-rw-r--r-- 3 hadoop supergroup 0 2020-02-10 23:35 /myhar.har/part-0//所有小文件的内容合并形成了part-0文件第三步:解压归档文件hdfs dfs -mkdir -p /user/harhdfs dfs -cp har:///user/myhar.har/* /user/har/
二、Sequence File方案
SequenceFile文件,主要由一条条record记录组成;每个record是键值对形式的,SequenceFile文件可以作为小文件的存储容器。每条record保存一个小文件的内容。
小文件名作为当前record的键,小文件的内容作为当前record的值。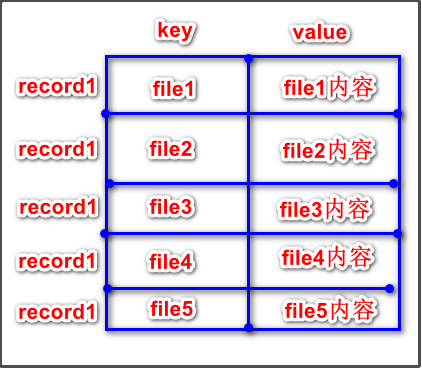
例如有10000个100KB的小文件,可以编写程序将这些文件内容放到一个SequenceFile文件。
一个SequenceFile是可分割的,所以MapReduce可将SequenceFile文件切分成块,每一块独立操作。
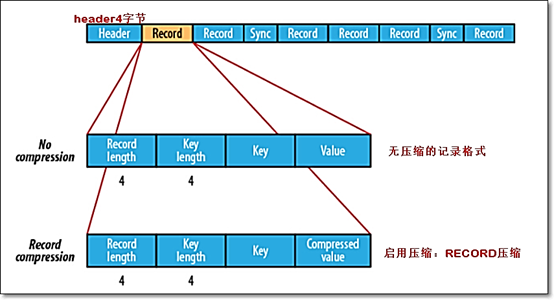
SequenceFile的详细结构
- 一个SequenceFile首先有一个4字节的header(文件版本号)
- 接着是若干record记录
记录间会随机的插入一些同步点sync marker,用于方便定位到记录边界。(同步点的作用就是如果位移点不在一个record的开始处,就会调用sync方法把位移点移到下一个record的开始处。)
压缩SequenceFile文件的方式
不像HAR,SequenceFile支持压缩。记录的结构取决于是否启动压缩,支持两类压缩:
不压缩NONE方式以及压缩RECORD
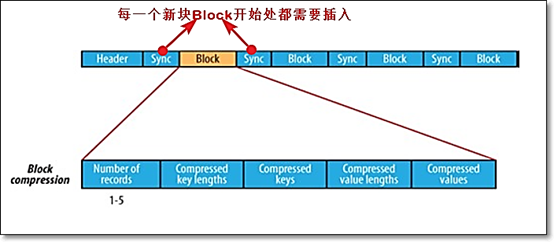
- 压缩BLOCK
- 一次性压缩多条record记录。
- 每一个新块Block开始处都需要插入同步点
- 在大多数情况下,以block(注意:指的是SequenceFile中的block)为单位进行压缩是最好的选择,因为一个block包含多条记录,利用record间的相似性进行压缩,压缩效率更高
案例一、向SequenceFile写入数据
把已有的数据转存为SequenceFile比较慢。比起先写小文件,再将小文件写入SequenceFile,一个更好的选择是直接将数据写入一个SequenceFile文件,省去小文件作为中间媒介.
下列代码主要步骤是创建SequenceFile.Writer类的对象,然后使用该对象的append()方法
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IOUtils;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.SequenceFile;import org.apache.hadoop.io.Text;import org.apache.hadoop.io.compress.BZip2Codec;import java.io.IOException;public class T1 {//模拟数据源private static final String[] DATA = {"I love you krystal","i love you kob3","lakers champion","hahahahhahaha"};public static void main(String[] args) throws IOException {//创建hadoop配置文件对象Configuration conf = new Configuration();//conf.set("fs.defaultFS","hdfs://node01:8020");//-->此行可写可不写,可能是默认调用系统的一些资源/*创建向SequenceFile文件写入数据时的一些选项,为等会创建SequenceFile.Writer对象提供参数*///要写入的SequenceFile的路径SequenceFile.Writer.Option pathOption= SequenceFile.Writer.file(new Path("hdfs://node01:8020//Seq1"));//record的key类型选项SequenceFile.Writer.Option keyOption= SequenceFile.Writer.keyClass(IntWritable.class);//record的value类型选项SequenceFile.Writer.Option valueOption= SequenceFile.Writer.valueClass(Text.class);//SequenceFile压缩方式:NONE | RECORD | BLOCK三选一//方案一:RECORD压缩、不指定压缩算法SequenceFile.Writer.Option compressOption= SequenceFile.Writer.compression(SequenceFile.CompressionType.RECORD);SequenceFile.Writer writer = SequenceFile.createWriter(conf, pathOption, keyOption, valueOption, compressOption);/* //方案二:BLOCK压缩、不指定压缩算法SequenceFile.Writer.Option compressOption = SequenceFile.Writer.compression(SequenceFile.CompressionType.BLOCK);SequenceFile.Writer writer = SequenceFile.createWriter(conf, pathOption, keyOption, valueOption, compressOption);//方案三:使用BLOCK压缩、指定压缩算法:BZip2Codec;压缩耗时间BZip2Codec codec = new BZip2Codec();codec.setConf(conf);SequenceFile.Writer.Option compressAlgorithm = SequenceFile.Writer.compression(SequenceFile.CompressionType.RECORD, codec);//创建写数据的Writer实例SequenceFile.Writer writer = SequenceFile.createWriter(conf, pathOption, keyOption, valueOption, compressAlgorithm);*///因为SequenceFile每个record是键值对的//指定key类型,value类型:IntWritable key = new IntWritable();Text value = new Text();//IntWritable是Java的int类型的对应Hadoop的的可序列化类型//Text是Java的String类型的对应Hadoop的可序列化类型for (int i = 0; i < DATA.length; i++) {//分别设置key、value值key.set(i);value.set(DATA[i]);System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);//在SequenceFile末尾追加内容writer.append(key, value);}//关闭流IOUtils.closeStream(writer);}}
案例二、查看SequenceFile
shell命令方式: hadoop fs -text /writeSequenceFile
JavaApi方式
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IOUtils;import org.apache.hadoop.io.SequenceFile;import org.apache.hadoop.io.Writable;import org.apache.hadoop.util.ReflectionUtils;import java.io.IOException;public class T1 {public static void main(String[] args) throws IOException {Configuration conf = new Configuration();//创建Reader对象,赋初值为nullSequenceFile.Reader reader = null;try {//读取SequenceFile的Reader的路径选项SequenceFile.Reader.Option pathOption = SequenceFile.Reader.file(new Path("hdfs://node01:8020/writeSequenceFile"));//实例化Reader对象reader = new SequenceFile.Reader(conf, pathOption);//根据反射,求出key类型(hadoop对应的什么类型的可序列化类型)Writable key = (Writable)ReflectionUtils.newInstance(reader.getKeyClass(), conf);//根据反射,求出value类型Writable value = (Writable)ReflectionUtils.newInstance(reader.getValueClass(),conf);long position = reader.getPosition();System.out.println(position);while (reader.next(key, value)) {String syncSeen = reader.syncSeen() ? "*" : "";System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);position = reader.getPosition();// beginning of next record定位到下一个record}} finally {//关闭资源IOUtils.closeStream(reader);}}}

若有收获,就点个赞吧
0 人点赞
