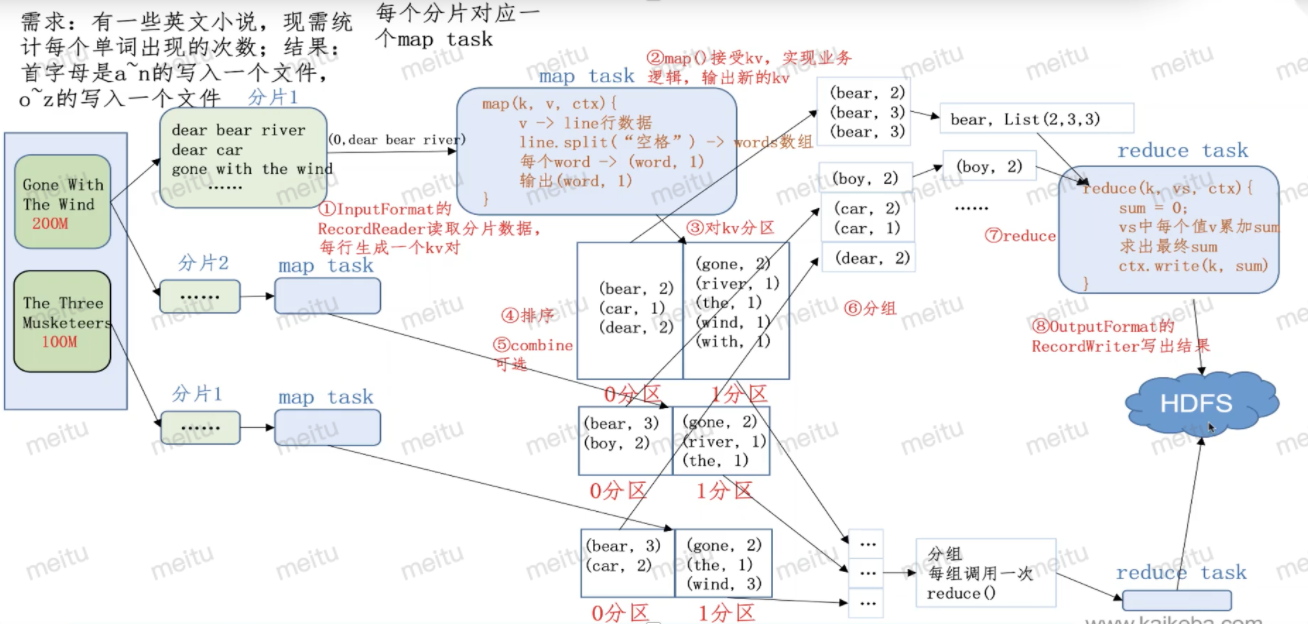
一、整个流程
1.1、Map阶段
- 第一步:设置InputFormat类,将数据切分成key,value对;此kv对作为第二步的输入;
自定义map逻辑,处理我们第一步传过来的kv对数据,然后转换成新的key、value对,并输出。
1.2、shuffle阶段4个步骤
第三步:对上一步输出的key、value对进行分区(相同的key的kv对属于同一个分区),Partitioner;
- 第四步:对每个分区的数据按照key进行排序;
- 第五步:对分区中的数据进行规约(combine操作),降低数据的网络拷贝(可选操作);
第六步:对排序后的kv对数据进行分组;分组过程中,key相同的kv对为一组;将同一组的kv对的所有value放到一个集合当中(每组数据调用一次reduce方法),WritableComparable。
1.3、reduce阶段2个步骤
第七步:对多个map任务进行合并,排序,写reduce函数自己的逻辑,对输入的key,value进行处理,转换成新的key,value对进行输出;
- 第八步:设置将输出的key、value对数据保存到文件中。

1.4、整体流程

二、MapTask的切片机制
1)一个Job的Map阶段的并行度由客户端在提交Job时的切片数决定
2)每一个split切片分配一个MapTask并行实例处理
3)默认情况下,切片大小=BlockSize
4)切片时不考虑数据集的整体性,而是逐个针对每一个文件单独切片
如下:有两个文件(一个300M,一个100M),对第一个文件切分3个分片,第二个文件切分一个分片,分别交给4个maptask进行处理。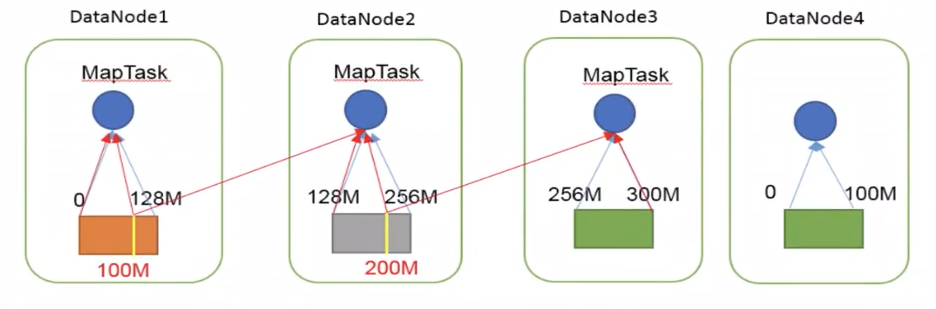
切片大小计算公式(在FileInputFormat源码中):
Math.max(minSize , Math,min(maxSize , blockSize))
mapreduce.input.fileinputformat.split.minsize = 1 默认值为1
mapreduce.input.fileinputformat.split.maxsize = Long.MAXVALUE
blockSize = 128M
三、FileInputFormat
在运行MapReduce程序时,输入的文件格式有:日志文件,二进制文件,数据库表等,那么针对不同的数据类型,MapReduce提供了相应的读取数据接口实现类:
TextInputFormat,KeyValueTextInputFormat,NLineInputFormat,CombineTextInputFormat和自定义InputFormat
3.1、TextInputFormat(Text类型)
TextInputFormat是默认的FileInputFormat实现类,按行读取每条记录。
键是存储该行在整个文件中的起始字节偏移量,LongWritable类型,值是该行内容,不包含任何终止符(换行符和回车符)
3.2、KeyValueTextInputFormat
每一行均为一条记录,被分隔符分割成key,value,在驱动类中设定分隔符,默认分隔符是tab(\t)
//获取配置信息,job对象实例 Configuration configuration=new Configuration(); configuration.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR,”\t”);

3.3、NLineInputFormat
每个map进程处理的InputSplit不再按照Block块划分,而是按照NLineInputFormat指定的行数N来划分,即输入文件的总行数/N=切片数。如果不能够整除,切片数=商+1
3.4、自定义InputFormat
Hadoop自带的InputFormat类型不能满足所有应用场景时,需要自定义InputFormat来解决
自定义InputFormat步骤
(1)自定义InputFormat类继承FileInputFormat
i)重写isSplitable方法,返回false不可切割
ii)重写RecordReader方法,创建自定义的RecordReader对象并初始化
public class WholeInputFormat extends FileInputFormat<NullWritable, BytesWritable>{@Overrideprotected boolean isSplitable(JobContext context, Path filename) {return false;}@Overridepublic RecordReader<NullWritable, BytesWritable> createRecordReader(InputSplit inputSplit, TaskAttemptContext context)throws IOException, InterruptedException {WholeRecordReader recordReader=new WholeRecordReader();recordReader.initialize(null, context);return recordReader;}}
(2)改写RecordReader,实现一次读取一个完整文件封装为KV
i)采用IO流一次读取一个文件输出到value中,因为设置了不可切片,最终把所有文件都封装在value中
ii)获取文件路径信息+名称,并设置key
public class WholeRecordReader extends RecordReader<Text,BytesWritable>{private BytesWritable value=new BytesWritable();private Text key=new Text();private boolean isProcess=false;private FileSplit fileSplit;private Configuration configuration;@Overridepublic void close() throws IOException {}@Overridepublic Text getCurrentKey() throws IOException, InterruptedException {return key;}@Overridepublic BytesWritable getCurrentValue() throws IOException, InterruptedException {return value;}@Overridepublic float getProgress() throws IOException, InterruptedException {return isProcess?1:0;}@Overridepublic void initialize(InputSplit inputSplit, TaskAttemptContext context) throws IOException, InterruptedException {fileSplit=(FileSplit) inputSplit;configuration = context.getConfiguration();}@Overridepublic boolean nextKeyValue() throws IOException, InterruptedException {if(!isProcess){FSDataInputStream inputStream=null;FileSystem fileSystem=null;try {byte[] bs=new byte[(int) fileSplit.getLength()];//获取文件系统Path path = fileSplit.getPath();fileSystem = path.getFileSystem(configuration);//打开文件流inputStream = fileSystem.open(path);IOUtils.readFully(inputStream, bs, 0,bs.length);value.set(bs, 0, bs.length);key.set(path.toString());}catch(Exception e){e.printStackTrace();}finally {if(inputStream!=null){inputStream.close();}if(fileSystem!=null){fileSystem.close();}}isProcess=true;return true;}return false;}}
(3)在输出时使用SequenceFileOutputFormat输出合并文件
job.setInputFormatClass(WholeInputFormat.class);job.setOutputFormatClass(SequenceFileOutputFormat.class);
3.5、CombineTextInputFormat实现切片个数控制
- 框架默认的TextInputFormat切片机制是对任务按照文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask。
- 这样如果有大量的小文件,就会产生大量的MapTask,处理效率极其低下。
- 1、应用场景
- 用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中
- 这样多个文件就可以交给一个MapTask处理,降低资源占用率
- 切片机制
- 生成切片过程包括:虚拟存储过程、切片过程。
- 虚拟储存过程
- 将输入目录下所有文件按照文件名称字典顺序排序,将每个文件的大小,依次和设置的setMaxInputSplitSize值比较;
- 如果不大于设置的值,逻辑上划分一个虚拟存储块;
- 如果输入文件大于最大值,小于最大值的两倍,那么将文件平分分为2个虚拟储存块;
- 如果输入文件大于最大值两倍,那么以最大值单位切割出虚拟储存块;
- 当剩余数据大小大于设置的最大值,且小于等于最大值2倍时,此时将剩余数据均分为2个虚拟储存块(防止出现太小切片)
- 例1:setMaxInputSplitSize为4M,有一个8.02M的文件,会先切分一个4M的,再切分两个2.01M的;
- 例2:setMaxInputSplitSize为4M,有一个6.32M的文件,会切分两个3.16M的;
- 切片过程
- 判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于单独形成一个切片
- 如果不大于则跟下一个虚拟存储文件进行合并;如果合并后还不大于setMaxInputSplitSize,则继续与下一个存储文件进行合并;当合并后,大于setMaxInputSplitSize后,共同形成一个切片;
- 例1:setMaxInputSplitSize为4M,有4个小文件,大小分别为1.7M、5.1M、3.4M、6.8M,则虚拟存储之后形成6个虚拟存储块;大小分别为1.7M、(2.55M+2.55M)、3.4M、(3.4M+3.4M);最终合并形成3个文件,大小分别为(1.7M+2.55M)、(2.55M+3.4M)、(3.4M+3.4M)。
job.setInputFormatClass(CombineTextInputFormat.class);CombineTextInputFormat.addInputPath(job,new Path(inputFile,inputFile2));CombineTextInputFormat.setMaxInputSplitSize(job,4*1024*1024);//4M 虚拟存储切片最大值设置
四、分组和分区的区别
分区:在Mapper的输出时进行,默认会采用HashPartitioner,会根据key值和reduce数进行分组;在写入MapOutputBuffer的缓冲区之前每个kv对就已经获取了对应的分区索引,在溢写时默认会根据分区索引从小到大,key值从小到大进行排序;并且rudecer数决定了分区数量,因为一个reducer只能处理一个分区。自定义分组器通过Job.setPartitionerClass()指定。
默认hash分区规则:(key.HashCode() & Interger.MAX_VALUE ) % reduceTaskNum
分组:在Reducer端进行,默认使用的是WritableComparator比较器进行对key值的比较,key值相同的会被分在一组。而reduce()函数是按照组为操作对象进行统计的,也就是有多少个组,则调用几次reduce()函数。这就与Mapper.run()不同,Mapper的操作对象是kv对,有多少个kv对则调用几次map()方法。自定义分组器通过Job.setGroupingComparatorClass()指定。(分组的有点像是在同一个Reducer内进行”分区”,这在自定义分组器对组合键进行分组很有优势。)

若有收获,就点个赞吧
0 人点赞
