健康探针(Health Probe)模式是关于应用程序如何将其健康状态传达给 Kubernetes。为了实现完全自动化,云原生应用必须具有高度的可观察性,允许推断其状态,这样 Kubernetes 就可以检测到应用是否已经启动,是否已经准备好服务请求。这些观察结果会影响 Pod 的生命周期管理,以及流量被路由到应用程序的方式。
问题描述
Kubernetes 会定期检查容器进程状态,如果发现问题就会重新启动。然而,从实践中我们知道,检查进程状态并不足以决定应用程序的健康状况。在很多情况下,一个应用程序挂起了,但它的进程仍然在运行。例如,一个 Java 应用程序可能会抛出一个 OutOfMemoryError,但 JVM 进程仍在运行。或者,一个应用程序可能会因为运行到一个无限循环、死锁或一些冲击(缓存、堆、进程)而冻结。为了检测这类情况,Kubernetes 需要一种可靠的方法来检查应用程序的健康状况。也就是说,并不是要了解应用的内部工作情况,而是一种检查,表明应用是否按照预期运行,是否能够为消费者提供服务。
解决方案
软件行业已经接受了这样一个事实,即不可能写出无错误的代码。此外,在使用分散的应用程序时,发生故障的机会就更多了。因此,处理故障的重点已经从避免故障转移到检测故障和恢复上。检测故障并不是一项简单的任务,不能对所有的应用程序统一执行,因为所有的应用程序对故障都有不同的定义。此外,不同类型的故障需要不同的纠正措施。暂时性故障可能会在足够的时间内自我恢复,而其他一些故障可能需要重新启动应用程序。让我们看看 Kubernetes 用来检测和纠正故障的检查。
进程健康检查(Process Health Checks)
进程健康检查是 Kubelet 不断对容器进程进行的最简单的健康检查。如果容器进程没有运行,就会重新启动容器。因此,即使没有任何其他的健康检查,应用程序也会因为这种通用检查而变得稍微健壮。如果你的应用程序能够检测到任何类型的故障并关闭自己,那么进程健康检查就是你所需要的。然而,对于大多数情况下,这还不够,其他类型的健康检查也是必要的。
存活探针(Liveness Probes)
如果你的应用运行到一些死锁,从进程健康检查的角度来看,它仍然被认为是健康的。为了根据你的应用业务逻辑来检测这种问题和任何其他类型的故障,Kubernetes 有存活探针 — 由 Kubelet 代理执行的定期检查,要求你的容器确认它仍然是健康的。重要的是,要从外部而不是应用本身执行健康检查,因为一些故障可能会阻止应用看门狗报告其故障。关于纠正措施,这种健康检查类似于进程健康检查,因为如果检测到故障,容器就会重新启动。然而,它提供了更多的灵活性,关于使用什么方法来检查应用程序的健康状况,如下所示:
- HTTP 探针对容器的 IP 地址执行 HTTP GET 请求,并期望得到一个介于 200 和 399 之间的成功的 HTTP 响应代码。
- TCP Socket 探针假设一个成功的 TCP 连接。
- Exec 探针在容器内核名空间中执行任意命令,并期望成功的退出代码(0)。
基于 HTTP 的存活探针的例子如例 4-1 所示。
# 例 4-1 一个具有存活探针的容器实例---apiVersion: v1kind: Podmetadata:name: pod-with-liveness-checkspec:containers:- image: k8spatterns/random-generator:1.0name: random-generatorenv:- name: DELAY_STARTUPvalue: "20"ports:- containerPort: 8080protocol: TCPlivenessProbe:# 对健康检查端点的 HTTP 探测httpGet:path: /actuator/healthport: 8080# 在进行第一次活泼度检查之前,等待30秒,以便给应用程序一些时间来预热initialDelaySeconds: 30
根据您的应用程序的性质,您可以选择最适合您的方法。由您的实现来决定您的应用程序何时被认为是健康的或不健康的。但是,请记住,没有通过健康检查的结果是重启你的容器。如果重启容器无济于事,那么健康检查失败也没有好处,因为 Kubernetes 会重启你的容器,而不修复根本问题。
就绪探针(Readiness Probes)
通过杀死不健康的容器并以新的容器替换它们,有效性检查对于保持应用程序的健康非常有用。但有时一个容器可能并不健康,重启它可能也无济于事。最常见的例子是当一个容器仍在启动,还没有准备好处理任何请求。或者是一个容器超载了,它的延迟在增加,你希望它暂时屏蔽掉额外的负载。
对于这种情况,Kubernetes 有就绪探针。执行准备度检查的方法与有效性检查(HTTP、TCP、Exec)相同,但本质上的行动是不同的。失败的就绪探针不是重新启动容器,而是导致容器从服务端点中移除,并且不接收任何新的流量。当容器准备好时,就绪探针会发出信号,以便它在收到服务的请求之前有一些时间进行热身。它对于屏蔽服务在后期阶段的流量也很有用,因为准备状态探测会定期执行,类似于活力检查。例 4-2 展示了如何通过探测应用程序在准备好进行操作时创建的文件的存在来实现准备度探测。
# 例 4-2 一个具有就绪探针的容器实例
---
apiVersion: v1
kind: Pod
metadata:
name: pod-with-readiness-check
spec:
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
readinessProbe:
# 如果文件不存在, stat 会返回一个错误,让就绪检查失败
exec:
command: [ "stat", "/var/run/random-generator-ready" ]
同样,由您对健康检查的实现来决定您的应用程序何时准备好做它的工作,何时应该让它单独运行。进程健康检查和存活检查的目的是通过重启容器从故障中恢复,而就绪检查则是为您的应用程序争取时间,并期望它自己恢复。请记住,Kubernetes 会试图阻止你的容器接收新的请求(例如,当它正在关闭时),即使就绪检查在 Pod 收到 SIGTERM 信号后仍然检查成功。
在许多情况下,你有存活和就绪探针在执行同样的检查。然而,就绪探针的存在给了您的容器启动的时间。只有通过了就绪性检查,Deployment 才被视为部署成功,因此,例如,使用旧版本的 Pod 可以作为滚动更新的一部分被终止。
存活和就绪度探针是云原生应用自动化的基本构件。应用框架,如 Spring 执行器、WildFly Swarm 健康检查、Karaf 健康检查或 Java 的 MicroProfile 规范,都为提供健康探针提供了实现。
启动探针(Startup Probes)
有时候,会有一些现有的应用程序在启动时需要较多的初始化时间。要不影响对引起探测死锁的快速响应,这种情况下,设置存活探测参数是要技巧的。技巧就是使用一个命令来设置启动探测,针对 HTTP 或者 TCP 检测,可以通过设置 failureThreshold * periodSeconds 参数来保证有足够长的时间应对糟糕情况下的启动时间。
ports:
- name: liveness-port
containerPort: 8080
hostPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 1
periodSeconds: 10
startupProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 30
periodSeconds: 10
幸亏有启动探测,应用程序将会有最多 5 分钟(30 * 10 = 300s)的时间来完成它的启动。 一旦启动探测成功一次,存活探测任务就会接管对容器的探测,对容器死锁可以快速响应。 如果启动探测一直没有成功,容器会在 300 秒后被杀死,并且根据 restartPolicy 来设置 Pod 状态。
一些讨论
为了实现完全自动化,云原生应用必须具有高度可观察性,为管理平台提供读取和解释应用健康状况的方法,并在必要时采取纠正措施。健康检查在部署、自愈、扩展等活动的自动化中发挥着基础作用。然而,您的应用程序还可以通过其他手段提供有关其健康状况的更多可见性。
为此,显而易见的老方法是通过日志记录。对于容器来说,一个好的做法是将任何重大事件记录到系统出错和系统错误中,并将这些日志收集到一个中心位置,以便进一步分析。日志通常不是用来采取自动行动的,而是用来发出警报和进一步调查。日志更有用的方面是对故障的事后分析和检测不明显的错误。
除了将日志记录到标准流中,将退出容器的原因记录到 /dev/termination-log 也是一个好的做法。这个位置是容器在永久消失之前陈述其最后意愿的地方。图 4-1 显示了容器如何与运行时平台通信的可能选择。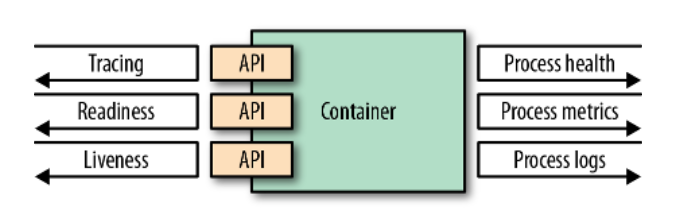
图 4-1 容器可观察性的一些选项
容器通过将其视为黑盒,为打包和运行应用程序提供了一种统一的方式。然而,任何旨在成为云原生公民的容器必须为运行时环境提供 API,以观察容器的健康状况并采取相应的行动。这种支持是以统一的方式实现容器更新和生命周期自动化的基本前提,进而提高系统的弹性和用户体验。在实际操作中,这意味着,作为最起码的要求,您的容器化应用程序必须为不同种类的健康检查(存活和就绪)提供 API。
即使是表现较好的应用程序也必须提供其他手段,以便管理平台通过集成跟踪和指标收集库(如 OpenTracing 或 Prometheus)来观察容器化应用程序的状态。把你的应用程序当作一个黑盒子,但实现所有必要的 API,以帮助平台以最好的方式观察和管理你的应用程序。
下一个模式,托管生命周期,也是关于应用和 Kubernetes 管理层之间的通信,但来自另一个方向。它是关于你的应用如何获得重要的 Pod 生命周期事件的通知。
参考资料
- Health Probe Example
- Configuring Liveness, Readiness and Startup Probes
- Setting Up Health Checks Wth Readiness and Liveness Probes
- Resource Quality of Service
- Graceful Shutdown with Node.js and Kubernetes
- Advanced Health-Check Patterns in Kubernetes
- Kubernetes and Containers Best Practices - Health Probes

若有收获,就点个赞吧
0 人点赞
