分布式有状态应用需要持久化身份、网络、存储和有序性等特性。有状态服务(Stateful Service)模式描述了 StatefulSet 基本元素,它为这些构件提供了强有力的保证,是管理有状态应用程序的理想选择。
问题描述
到目前为止,我们已经看到了许多用于创建分布式应用的 Kubernetes 基本元素:带有健康检查和资源限制的容器、带有多个容器的 Pod、整个集群的动态放置、批处理作业、周期性作业、单例等等。所有这些基本元素的共同特点是,它们将被管理的应用视为由相同、可交换和可替换的容器组成的无状态应用,并符合 The Twelve-Factor App 原则。
虽然有一个平台负责无状态应用的放置、弹性和扩展是一个重大的提升,但仍有很大一部分工作负载需要考虑:有状态应用,其中每个实例都是唯一的,并且具有长期的特性。
在现实世界中,每一个高度可扩展的无状态服务背后都有一个有状态服务,通常是一些数据存储的形式。在 Kubernetes早 期缺乏对有状态工作负载的支持时,解决方案是将无状态应用放在 Kubernetes 上,以获得云原生模型的好处,而将有状态组件保留在集群之外,或者在公有云上,或者在企业内部硬件上,用传统的非云原生机制进行管理。考虑到每个企业都有众多的有状态工作负载(传统的和现代的),缺乏有状态工作负载的支持是 Kubernetes 的一个重要限制,因为 Kubernetes 被称为通用的云原生平台。
但是有状态应用的典型需求是什么呢?我们可以通过使用 Deployment 部署一个有状态的应用,比如 Apache ZooKeeper、MongoDB、Redis 或 MySQL,可以创建一个 ReplicaSet,并将其复本设置为 replicas=1,使其可靠;使用 Service 发现其端点;使用 PersistentVolumeClaim 和 PersistentVolume 作为其状态的永久存储。
虽然这对于单实例有状态的应用来说大多是正确的,但并不完全正确,因为 ReplicaSet 并不能保证最多一次的语义,而且复制数也会临时变化。这样的情况可能是灾难性的,会导致数据丢失。另外,当它是一个由多个实例组成的分布式有状态服务时,主要的挑战就来了。一个由多个集群服务组成的有状态应用,需要底层基础设施提供多方面的保障。让我们来看看分布式有状态应用中最常见的一些长寿命持久化的前提条件。
存储(Storage)
我们可以很容易地增加 ReplicaSet 中的副本数量,最终实现分布式有状态应用。然而,我们如何定义这种情况下的存储需求呢?通常情况下,像前面提到的分布式有状态应用需要为每个实例提供专用的持久化存储。ReplicaSet 的 replicas=3 和 PersistentVolumeClaim (PVC) 定义将导致所有三个 Pod 都连接到同一个 PersistentVolume (PV)。虽然 ReplicaSet 和 PVC 确保了实例的启动和存储被连接到实例计划的任何一个节点上,但存储并不是专用的,而是所有 Pod 实例共享的。
这里的一个变通方法是让应用实例使用共享存储,并有一个应用内机制将存储分割成子文件夹,并在不冲突的情况下使用。虽然这种方法是可行的,但这种方法会造成单一存储的单点故障。另外,由于在扩展过程中 Pod 的数量会发生变化,所以容易出错,而且在扩展过程中可能会在防止数据损坏或丢失方面造成严重的挑战。
另一种变通方法是为分布式有状态应用的每个实例设置一个单独的 ReplicaSet(replicas=1)。在这种情况下,每个 ReplicaSet 都会得到它的 PVC 和专用存储。这种方法的缺点是需要大量的手工劳动:扩展需要创建一组新的 ReplicaSet、PVC 或服务定义。这种方法缺乏一个单一的抽象,无法将有状态应用的所有实例作为一个整体来管理。
网络(Networking)
与存储要求类似,分布式有状态应用也需要一个稳定的网络身份。除了将特定应用的数据存储到存储空间中,有状态应用还存储配置细节,如主机名和对等体的连接细节。这意味着每一个实例都应该可以在一个预先决定的地址中到达,这个地址不应该像 ReplicaSet 中的 Pod IP 地址那样动态变化。在这里,我们可以通过一个变通方法来解决这个要求:为每个 ReplicaSet 创建一个 Service,并让 replicas=1。然而,管理这样的设置是一项手工工作,而且应用程序本身不能依赖一个稳定的主机名,因为每次重启后主机名都会改变,而且也不知道从哪个服务名访问。
身份(Identity)
从前面的需求中可以看出,集群有状态应用很大程度上依赖于每个实例都掌握了它的长存存储和网络身份。这是因为在有状态应用中,每个实例都是唯一的,都知道自己的身份,而这个身份的主要成分是长存存储和网络坐标。在这个列表中,我们还可以添加实例的身份/名称(一些有状态应用需要唯一的持久化名称),在 Kubernetes 中,这个名称就是 Pod 名称。使用 ReplicaSet 创建的 Pod 会有一个随机的名字,并且在重启时不会保留这个身份。
有序性(Ordinality)
除了唯一的和长期的身份之外,集群有状态应用的实例在实例集合中还有一个固定的位置。这种排序典型地影响了实例被放大和缩小的顺序。然而,它也可以用于数据分布或访问和集群内行为定位,如锁、单子或主站。
其它需求
稳定和长期的存储、网络、身份和秩序是集群有状态应用的集体需求之一。管理有状态的应用程序也有许多其他具体的要求,这些要求因情况不同而不同。例如,有些应用程序有法定人数的概念,并要求最少的实例数量始终可用;有些应用程序对有序性很敏感,而有些应用程序对并行部署没有问题;有些应用程序可以容忍重复的实例,而有些应用程序则不能。为所有这些一次性的情况进行规划并提供通用机制是一项不可能完成的任务,这就是为什么 Kubernetes 还允许创建 CustomResourceDefinition 和 Operator 来管理有状态的应用。Operators 在第 23 章中进行了解释。
我们已经看到了管理分布式有状态应用的一些常见挑战,以及一些不太理想的变通方法。接下来,让我们来看看 Kubernetes 的本地机制,它通过 StatefulSet 基本元素来解决这些需求。
解决方案
为了解释 StatefulSet 为管理有状态应用提供了什么,我们偶尔会将它的行为与 Kubernetes 用于运行无状态工作负载的熟悉的 ReplicaSet 进行比较。在很多方面,StatefulSet 是用来管理宠物的,而 ReplicaSet 是用来管理牛的。在 DevOps 世界中,宠物与牛是一个著名的(但也是一个有争议的)比喻:相同的、可替换的服务器被称为牛,而需要单独照顾的非易变的唯一服务器被称为宠物。同样,StatefulSet(最初受这个类比的启发,被命名为 PetSet)是为管理非易腐烂的 Pod 而设计的,而 ReplicaSet 则是为管理相同的可替换 Pod 而设计的。
让我们来探讨一下 StatefulSet 是如何工作的,以及它们是如何满足有状态应用程序的需求的。例 11-1 是我们的随机生成器服务作为一个 StatefulSet。
# 例 11-1 一个 StatefulSet 示例---apiVersion: apps/v1kind: StatefulSetmetadata:# StatefulSet 的名称作为生成节点名称的前缀name: rgspec:# 引用例 11-2 中定义的强制服务serviceName: random-generator# StatefulSet 中的两个 Pod 成员命名为 rg-0 和 rg-1replicas: 2selector:matchLabels:app: random-generatortemplate:metadata:labels:app: random-generatorspec:containers:- image: k8spatterns/random-generator:1.0name: random-generatorports:- containerPort: 8080name: httpvolumeMounts:- name: logsmountPath: /logs# 为每个 Pod 创建 PVC 的模板(类似于 Pod 的模板)volumeClaimTemplates:- metadata:name: logsspec:accessModes: [ "ReadWriteOnce" ]resources:requests:storage: 10Mi
我们不打算逐行检查例 11-1 中的定义,而是探讨这个 StatefulSet 定义所提供的整体行为和保证。
存储
虽然这并不总是必要的,但大多数有状态的应用程序都会存储状态,因此需要基于每个实例的专用持久性存储。在 Kubernetes 中请求并将持久化存储与 Pod 关联的方式是通过 PV 和 PVC。为了像创建 Pod 一样创建 PVC,StatefulSet 使用了一个 volumeClaimTemplates 元素。这个额外的属性是 StatefulSet 和 ReplicaSet 的主要区别之一,后者有一个 persistentVolumeClaim 元素。
StatefulSet 不是引用预定义的 PVC,而是在 Pod 创建过程中通过使用 volumeClaimTemplates 来创建 PVC。这种机制允许每个 Pod 在初始创建期间以及在扩展期间通过改变 StatefulSet 的副本数来获得自己的专用 PVC。
正如你可能意识到的,我们说 PVC 是创建并与 Pod 相关联的,但我们没有说任何关于 PV 的事情。这是因为 StatefulSet 不以任何方式管理 PV。Pod 的存储必须由管理员提前供应,或者由 PV 供应者根据请求的存储类按需供应,并准备好供有状态的 Pod 消费。
:::tips 注意这里的不对称行为:扩大 StatefulSet 的规模(增加副本数)会创建新的 Pod 和相关的 PVC。此外,缩小规模会删除 Pod,但不会删除任何 PVC(也不会删除 PV),这意味着 PV 不能被回收或删除,而 Kubernetes 不能释放存储。这种行为是设计出来的,是由以下假设驱动的:有状态应用的存储是至关重要的,意外的缩减不应导致数据丢失。如果你确定有状态的应用是故意缩减的,并且已经将数据复制/耗尽到其他实例中,你可以手动删除 PVC,这样可以进行后续的 PV 回收。 :::
网络
:::info
StatefulSet 创建的每个 Pod 都有一个稳定的标识,由 StatefulSet 的名称和一个序数索引(从 0 开始)生成。基于前面的例子,这两个 Pod 被命名为 rg-0 和 rg-1。Pod 名称以可预测的格式生成,与 ReplicaSet 的 Pod 名称生成机制不同,后者包含一个随机后缀。
:::
专用的可扩展持久性存储是有状态应用的一个重要方面,网络也是如此。在例 11-2 中,我们定义了一个无头 Service。在无头 Service 中,clusterIP:None,这意味着我们不需要 kube-proxy 来处理 Service,也不需要集群 IP 分配,也不需要负载均衡。那么我们为什么需要一个 Service 呢?
# 例 11-2 访问 StatefulSet 的服务示例
---
apiVersion: v1
kind: Service
metadata:
name: random-generator
spec:
# 声明该服务为无头(Headless)服务
clusterIP: None
selector:
app: random-generator
ports:
- name: http
port: 8080
通过 ReplicaSet 创建的无状态 Pod 被认为是相同的,请求落在哪一个 Pod 上并不重要(因此有普通 Service 的负载均衡)。但是有状态的 Pod 之间是不同的,我们可能需要通过它的坐标到达特定的 Pod。
一个带有选择器的无头 Service(注意 .selector.app == random-generator)恰恰可以实现这一点。这样的 Service 在 API Server 中创建 Endpoint 记录,并创建 DNS 条目以返回 A 记录(地址),直接指向支持该 Service 的 Pod。长话短说,每个 Pod 都会得到一个 DNS 条目,客户可以以可预测的方式直接接触到它。例如,如果我们的随机生成器服务属于默认的命名空间,我们可以通过其完全限定的域名到达我们的 rg-0 Pod:rg-0.random-generator.default.svc.cluster.local,其中 Pod 的名称被预置在服务名称前。这种映射允许集群应用的其他成员或其他客户机在他们愿意的情况下到达特定的 Pod。
我们还可以对 SRV 记录进行 DNS 查找(例如,通过 [dig](https://www.linode.com/docs/networking/dns/use-dig-to-perform-manual-dns-queries/) SRV random-generator.default.svc.cluster.local),发现所有在 StatefulSet 的管理服务中注册的运行 Pod。如果任何客户端应用程序需要这样做,这种机制允许动态发现集群成员。无头 Service 和 StatefulSet 之间的关联不仅是基于选择器,StatefulSet 还应该以 serviceName: random-generator 的名称链接回 Service。
通过 volumeClaimTemplates 定义专用存储并不是强制性的,但通过 serviceName 字段链接到 Service 是强制性的。治理 Service 必须在 StatefulSet 创建之前就存在,并负责集的网络身份。如果你想要的话,你总是可以另外创建其他类型的 Service,在你的有状态 Pod 上进行负载平衡。
如图 11-1 所示,StatefulSet 提供了在分布式环境中管理有状态应用程序所需的一组构件和保证行为。您可以根据您的有状态使用案例选择和使用它们。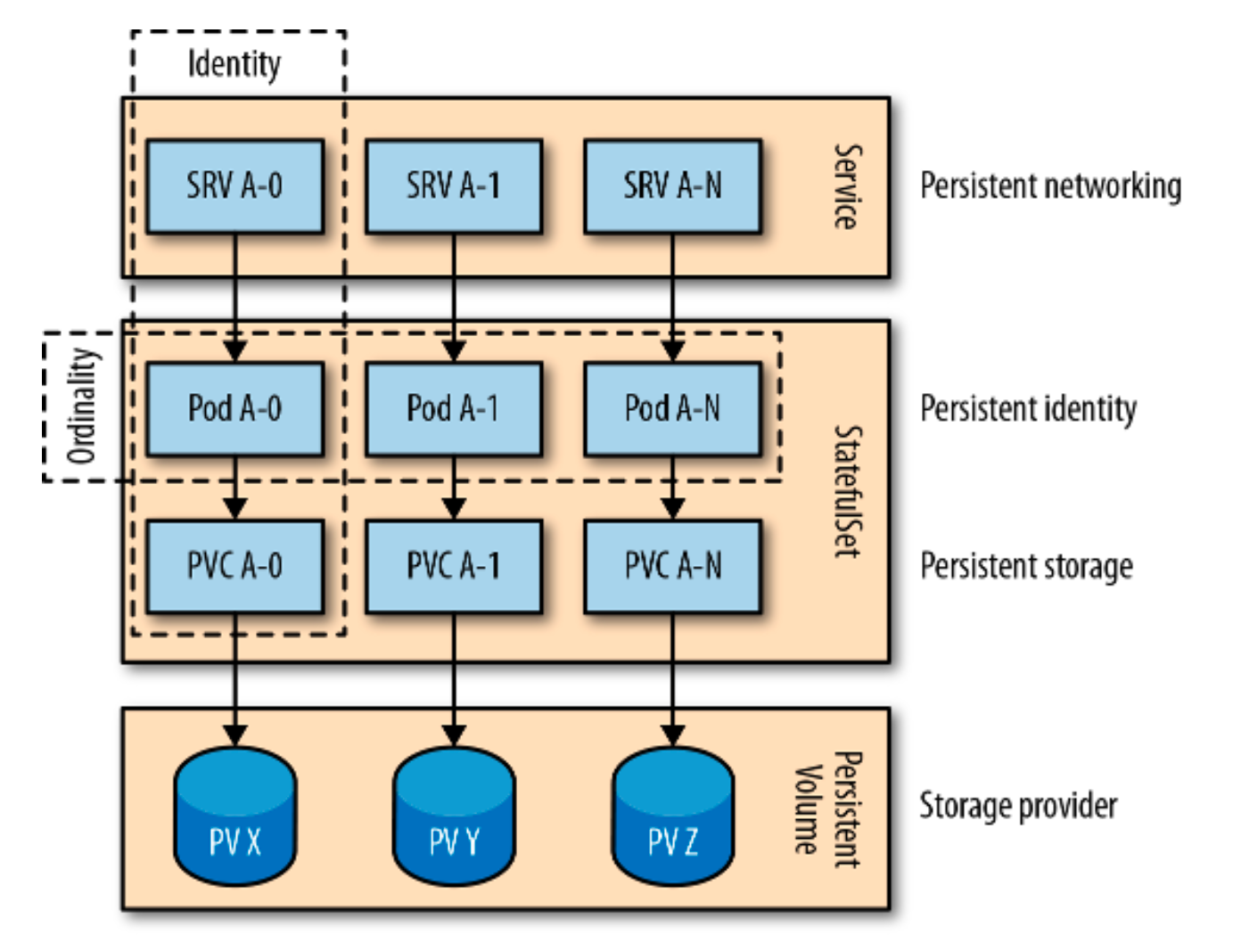
图 11-1 在 Kubernetes 上的一个分布式有状态服务
身份
身份是所有其他 StatefulSet 保证的元构件。基于 StatefulSet 的名称,我们可以得到可预测的 Pod 名称和身份。然后我们使用该身份来命名 PVC,通过无头服务接触特定的 Pod,等等。你可以在创建每一个 Pod 之前预测它的身份,并在需要时在应用本身中使用这些知识。
有序性
根据定义,一个分布式有状态的应用程序由多个实例组成,这些实例是唯一的、不可交换的。除了它们的唯一性之外,实例之间还可以根据它们的实例化顺序/位置相互关联,这就是固定性要求的地方。
:::info
从 StatefulSet 的角度来看,有序性唯一发挥作用的地方是在伸缩过程中。Pod 的名称有一个序数后缀(从 0 开始),Pod 的创建顺序也定义了 Pod 的缩放顺序(从 n - 1 到 0 的反向顺序)。
:::
如果我们创建了一个具有多个副本的 ReplicaSet,Pod 会被安排在一起启动,而不需要等待第一个成功启动(运行和准备好的阶段,如第 4 章,“健康探针” 中所述)。Pod 启动和准备的顺序是不保证的。当我们缩小 ReplicaSet 的规模时也是一样的(可以是通过改变复制数或删除它)。属于 ReplicaSet 的所有 Pod 会同时开始关闭,它们之间没有任何排序和依赖性。这种行为可能会更快地完成,但不是有状态的应用程序所需要的,特别是当实例之间涉及数据分区和分布时。
:::tips
为了在扩展和关闭过程中实现适当的数据同步,StatefulSet 默认执行顺序启动和关闭。这意味着 Pod 从第一个 Pod 开始(索引为 0),只有当该 Pod 成功启动后,才会安排下一个 Pod(索引为 1),并继续这个顺序。在缩减期间,顺序相反 — 首先关闭指数最高的 Pod,只有当它成功关闭后,才会停止下一个指数较低的 Pod。这个顺序一直持续到索引为 0 的 Pod 被终止。
:::
其它功能
StatefulSet 还有其他方面是可以定制的,以适应有状态应用的需求。每一个有状态的应用都是独一无二的,需要仔细考虑,同时尝试将其放入 StatefulSet 模型中。让我们再看看一些 Kubernetes 的技巧,在驯服有状态的应用时,这些技巧可能会变得有用。
- 分区更新(Partitioned Updates):上面我们介绍了在扩展 StatefulSet 时的顺序排序保证。至于更新已经运行的有状态应用程序(例如,通过改变
.spec.template元素),StatefulSet 允许分阶段推出(如金丝雀版本),它保证一定数量的实例保持完整,同时对其余实例应用更新。
通过使用默认的滚动更新策略,您可以通过规范.spec.updateStrategy.rollingUpdate.partition数值来对实例进行分区。该参数(默认值为 0)表示 StatefulSet 应被分区更新的序数。如果指定了该参数,所有序数大于或等于分区的 Pod 都会被更新,而序数小于该序数的 Pod 不会被更新。即使删除了 Pod,也是如此;Kubernetes 会以之前的版本重新创建它们。这个特性可以实现对集群有状态应用的部分更新(例如,确保保留法定人数),然后通过将分区设回 0 来将更改推出到集群的其他部分。 - 并行部署(Parallel Deployments):当我们将
.spec.podManagementPolicy设置为Parallel时,StatefulSet 会并行地启动或终止所有 Pod,而不会等待 Pod 运行就绪或完全终止后再转到下一个。如果您的有状态应用程序不需要顺序处理,这个选项可以加快操作程序的速度。 - 最多一次保证(At-Most-One Guarantee):唯一性是有状态应用实例的基本属性之一,Kubernetes 通过确保 StatefulSet 的两个 Pod 没有相同的身份或绑定到相同的 PV 来保证这一点。相比之下,ReplicaSet 为其实例提供了 At-Least-X-Guarantee。例如,具有两个副本的 ReplicaSet 试图保持至少两个实例在任何时候都能正常运行。即使偶尔有机会让这个数字更高,控制器的优先级也不会让 Pods 的数量低于指定数量。当一个 Pod 被一个新的 Pod 替换,而旧的 Pod 还没有完全终止时,有可能运行超过指定数量的复制。或者,如果一个 Kubernetes 节点在
NotReady状态下无法到达,但仍有运行中的 Pod,则可以更高。在这种情况下,ReplicaSet 的控制器会在健康的节点上启动新的 Pod,这可能会导致运行中的 Pod 数量超过预期。这在 At-Least-X 的语义中是可以接受的。
另一方面,StatefulSet 控制器会进行所有可能的检查,以确保没有重复的 Pod — 这就是 At-Most-One 保证。它不会再次启动一个 Pod,除非确认旧的实例被完全关闭。当一个节点发生故障时,它将在另一个节点上调度新的 Pod,除非 Kubernetes 能够确认 Pod(也许是整个节点)被关闭。StatefulSet 的 At-Most-One 语义决定了这些规则。
仍然有可能打破这些保证,最终在 StatefulSet 中出现重复的Pod,但这需要积极的人为干预。例如,在物理节点仍在运行的情况下,从 API Server 中删除一个不可到达的节点资源对象,就会打破这种保证。只有当确认节点死机或断电,并且没有 Pod 程序在其上运行时,才应执行这样的操作。或者,例如,用kubectl delete pods _<pod>_ --grace-period=0 --force强行删除一个Pod,它不会等待 Kubelet 确认 Pod 已经终止。这个操作立即从 API Server 中清除 Pod,并导致 StatefulSet 控制器启动一个可能导致重复的替换 Pod。
我们在第 10 章 “单例服务” 中更深入地讨论实现单例的其他方法。
一些讨论
在本章中,我们看到了在云原生平台上管理分布式有状态应用的一些标准要求和挑战。我们发现,处理单实例有状态的应用程序相对容易,但处理无属性状态是一个多维度的挑战。虽然我们通常将“状态”的概念与“存储”联系在一起,但在这里,我们看到了状态的多个方面,以及它对不同的有状态应用的不同保障要求。在这个领域,StatefulSet 是实现分布式有状态应用的一个很好的基本元素,它解决了持久化存储、网络(通过 Service)、身份、有序性和其他一些方面的需求。它提供了一套很好的构件,用于以自动化的方式管理有状态应用,使它们成为云原生世界中的一流公民。
StatefulSet 是一个良好的开端和进步,但有状态应用的世界是独特而复杂的。除了为云原生世界设计的有状态应用可以装入 StatefulSet 之外,还存在大量的传统有状态应用,这些应用并不是为云原生平台设计的,有更多的需求。幸运的是,Kubernetes 也有一个答案。Kubernetes 社区已经意识到,与其通过 Kubernetes 资源来模拟不同的工作负载,并通过通用控制器来实现它们的行为,不如允许用户实现自己的自定义控制器,甚至更进一步,允许通过自定义资源定义和通过 Operator 来模拟应用资源的行为。
在第 22 章和第 23 章中,您将了解相关的 Controller 和 Operator 模式,它们更适合管理云原生环境中复杂的有状态应用。
参考资料

若有收获,就点个赞吧
0 人点赞
