在共享云环境上成功部署、管理和共存应用程序的基础取决于识别和声明应用程序的资源需求和运行时依赖性。这个可预测的需求(Predictable Demands)模式是关于你应该如何声明应用需求,无论是硬性的运行时依赖还是资源需求。声明你的需求对于 Kubernetes 在集群中为你的应用找到合适的部署位置至关重要。
问题描述
Kubernetes 可以管理用不同编程语言编写的应用程序,只要该应用程序可以在容器中运行。然而,不同的语言有不同的资源需求。通常情况下,与即时运行时或解释型语言相比,编译型语言运行速度更快,通常需要更少的内存。考虑到很多同一类的现代编程语言对资源的要求都差不多,从资源消耗的角度来看,更重要的方面是领域、应用程序的业务逻辑和实际实现细节。
很难预测一个容器可能需要多少资源才能发挥最佳功能,开发者才知道服务实现的资源预期(通过测试发现)。有些服务的 CPU 和内存消耗情况是固定的,有些则是有明显高峰和低谷的。有些服务需要持久化的存储来存储数据;有些遗留服务需要在主机系统上有固定的端口号才能正常工作。定义所有这些应用特性并将其传递给管理平台,是云原生应用的基本前提。
除了资源需求外,应用运行时还对平台管理的能力有依赖性,如数据存储或应用配置。
解决方案
了解容器的运行时需求主要有两个方面的重要意义:首先,在定义了所有的运行时依赖性和资源需求设想后,Kubernetes 可以智能地决定在集群上将容器放置在哪里,以实现最有效的硬件利用。在一个有大量优先级不同的进程共享资源的环境中,要想成功共存,唯一的办法就是提前了解每个进程的需求。然而,智能投放只是硬币的一面。
容器资源档案必不可少的第二个原因是容量规划。根据具体的服务需求和服务总量,我们可以针对不同的环境做一些容量规划,得出性价比最高的主机配置文件,以满足整个集群的需求。服务资源档案和容量规划是相辅相成的,才能长期成功的进行集群管理。
在深入研究资源档案之前,我们先来看看如何声明运行时的依赖关系。
运行时依赖(Runtime Dependencies)
最常见的运行时依赖之一是用于保存应用程序状态的文件存储。容器的文件系统是短暂的,当容器关闭时就会丢失。Kubernetes 提供了存储卷(Volume)作为 Pod 级的存储实用程序,可以在容器重启后存活。
最直接的卷类型是 emptyDir,只要 Pod 存活,它就会存活,当 Pod 被移除时,其内容也会丢失。存储卷需要有其他类型的存储机制支持,才能有一个在 Pod 重启后仍能存活的卷。如果你的应用程序需要向这种长寿命的存储设备读写文件,你必须在容器定义中使用存储卷明确声明这种依赖关系,如例 2-1 所示。
# 例 2-1 对于 PersistenceVolume 的依赖---apiVersion: v1kind: Podmetadata:name: random-generatorspec:containers:- image: k8spatterns/random-generator:1.0name: random-generatorvolumeMounts:- mountPath: "/logs"name: log-volumevolumes:- name: log-volume# 依赖于 PVC 的存在和约束persistentVolumeClaim:claimName: random-generator-log
调度器会评估 Pod 所需要的卷的种类,这将影响 Pod 的放置位置。如果 Pod 需要的卷没有由集群上的任何节点提供,那么 Pod 就不会被调度。卷是运行时依赖性的一个例子,它影响 Pod 可以运行什么样的基础设施,以及 Pod 是否可以被调度。
当你要求 Kubernetes 通过 hostPort 在主机系统的特定端口上公开容器端口时,也会发生类似的依赖关系。hostPort 的使用在节点上创建了另一个运行时依赖性,并限制了 Pod 的调度位置。 hostPort 在集群中的每个节点上保留了端口,并限制每个节点最多调度一个 Pod。由于端口冲突,你可以扩展到 Kubernetes 集群中有多少节点就有多少 Pod。
一种不同的依赖类型是配置。几乎每个应用程序都需要一些配置信息,Kubernetes 提供的推荐解决方案是通过 ConfigMap 来存储配置。你的服务需要有一个消耗设置的策略 — 无论是通过环境变量还是文件系统。无论是哪种情况,这都会引入你的容器对名为 ConfigMap 的运行时依赖。如果没有创建所有预期的 ConfigMap,则容器在节点上被调度,但它们不会启动。ConfigMap 和 Secret 在第 19 章 “配置资源” 中有更详细的解释,例 2-2 展示了如何将这些资源用作运行时依赖。
# 例 2-2 对于 ConfigMap 的依赖
---
apiVersion: v1
kind: Pod
metadata:
name: random-generator
spec:
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
env:
- name: PATTERN
valueFrom:
# 依赖于 ConfigMap 的存在
configMapKeyRef:
name: random-generator-config
key: pattern
与 ConfigMap 类似的概念是 Secret,它提供了一种略微安全的方式来将特定环境的配置分发到容器。消费 Secret 的方式和消费 ConfigMap 的方式是一样的,它引入了从容器到命名空间的同种依赖性。
虽然 ConfigMap 和 Secret 对象的创建是我们必须执行的简单管理任务,但集群节点提供了存储和端口号。这些依赖关系中的一些限制了 Pod 被调度的位置(如果有的话),而其他依赖关系可能会阻止 Pod 的启动。当设计你的容器化应用程序时,一定要考虑到它们以后会产生的运行时约束。
资源档案(Resource Profiles)
指定 ConfigMap、Secret 和存储卷等容器依赖关系是很直接的。我们需要更多的思考和实验来弄清容器的资源需求。Kubernetes 上下文中的计算资源被定义为可以被容器请求、分配给容器并从容器中获得的东西。这些资源分为可压缩的(即可以节制,如 CPU,或网络带宽)和不可压缩的(即不能节制,如内存)。
区分可压缩资源和不可压缩资源是非常重要的。如果你的容器消耗了太多的可压缩资源(如 CPU),它们就会被节流,但如果它们使用了太多的不可压缩资源(如内存),它们就会被杀死(因为没有其他方法可以要求应用程序释放分配的内存)。
根据你的应用程序的性质和实现细节,你必须指定所需资源的最小量(称为请求)和它能增长到的最大量(限制)。每个容器定义都可以以请求和限制的形式指定它所需要的 CPU 和内存量。在一个高层次上,请求/限制的概念类似于软/硬限制。例如,同样地,我们通过使用 -Xms 和 -Xmx 命令行选项来定义 Java 应用程序的堆大小。
调度器在将 Pod 放置到节点上时,使用的是请求量(但不是限制)。对于一个给定的 Pod,调度器只考虑仍有足够能力容纳 Pod 及其所有容器的节点,将请求的资源量相加。从这个意义上说,每个容器的请求字段会影响 Pod 的调度与否。例 2-3 显示了如何为 Pod 规定这种限制。
# 例 2-3 资源限制
---
apiVersion: v1
kind: Pod
metadata:
name: random-generator
spec:
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
resources:
# CPU 和内存的初始资源请求
requests:
cpu: 100m
memory: 100Mi
# CPU 和内存的初始资源上限
limits:
cpu: 200m
memory: 200Mi
根据您是指定请求、限制,还是两者都指定,平台提供不同的服务质量(QoS):
BestEffort:Pod 没有为其容器设置任何请求和限制。这样的 Pod 被认为是最低优先级的,当放置 Pod 的节点用完不可压缩资源时,会首先被杀死。Burstable:已定义请求和限制的 Pod,但它们并不相等(而且限制比预期的请求大)。这样的 Pod 有最小的资源保证,但在可用的情况下,也愿意消耗更多的资源,直至其极限。当节点面临不可压缩的资源压力时,如果没有BestEffortPod 剩余,这些 Pod 很可能被杀死。Garanteed:具有同等请求量和限制资源的 Pod。这些是优先级最高的 Pod,保证不会在BestEffort和BurstablePod之前被杀死。
所以你为容器定义的资源特性或省略的资源特性会直接影响到它的 QoS,并定义了 Pod 在资源饥饿时的相对重要性。在定义你的 Pod 资源需求时,要考虑到这个后果。
Pod 优先权(Pod Priority)
我们解释了容器资源声明如何定义 Pod 的 QoS,并影响 Kubelet 在资源耗尽时杀死 Pod 中容器的顺序。另一个相关的功能是 Pod 优先权和抢占(Preemption),在写这篇文章的时候还在测试阶段。Pod 优先权允许显示一个 Pod 相对于其他 Pod 的重要性,这将影响 Pod 被安排的顺序。让我们在例 2-4 中看到这个功能。
# 例 2-4 Pod 优先权
---
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 1000
globalDefault: false
description: This is a very high priority Pod class
---
apiVersion: v1
kind: Pod
metadata:
name: random-generator
labels:
env: random-generator
spec:
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
# 该 Pod 使用的优先级,定义在上面 PriorityClass 资源中
priorityClassName: high-priority
我们创建了一个 PriorityClass,这是一个非命名空间的对象,用于定义一个基于整数的优先级。我们的 PriorityClass 被命名为
high-priority,优先级为1000。现在我们可以通过它的名字将这个优先级分配给 Pod,如priorityClassName: high-priority。PriorityClass 是一种表示 Pod 相对重要性的机制,数值越高表示 Pod 越重要。
当启用 Pod 优先级功能时,它会影响调度器将 Pod 放在节点上的顺序。首先,优先级接纳控制器使用 priorityClassName 字段来填充新 Pod 的优先级值。当有多个 Pod 等待放置时,调度器按最高优先级对待放 Pod 队列进行排序。任何待定的 Pod 都会被选在调度队列中优先级较低的其他待定 Pod 之前,如果没有阻止它调度的限制,Pod 就会被调度。
关键的部分来了。如果没有足够能力放置 Pod 的节点,调度器可以从节点上抢占(移除)优先级较低的 Pod,以释放资源,放置优先级较高的 Pod。因此,如果满足其他所有调度要求,优先级较高的 Pod 可能比优先级较低的 Pod 更早被调度。这种算法有效地使集群管理员能够控制哪些 Pod 是更关键的工作负载,并通过允许调度器驱逐优先级较低的 Pod,以便在工作节点上为优先级较高的 Pod 腾出空间,从而将它们放在第一位。如果一个 Pod 不能被调度,调度器会继续放置其他低优先级的 Pod。
Pod QoS(前面已经讨论过)和 Pod 优先级是两个正交的特性,它们之间没有联系,只有一点重叠。QoS 主要被 Kubelet 用来在可用计算资源较少时维护节点的稳定性。Kubelet 在驱逐前首先考虑 QoS,然后再考虑 Pod 的 PriorityClass。另一方面,调度器驱逐逻辑在选择抢占目标时完全忽略了 Pod 的 QoS。调度器试图选择一组优先级尽可能低的 Pod,满足优先级较高的 Pod 等待投放的需求。
:::danger 当 Pod 具有指定的优先级时,它可能会对其他被驱逐的 Pod 产生不希望的影响。例如,虽然 Pod 的优雅终止策略是被尊重的,但在第 10 章中讨论的 PodDisruptionBudget,Singleton 服务是不被保证的,这可能会破坏一个依赖 Pod 法定人数(Quorum)的低优先级集群应用。 :::
另一个问题是恶意或不知情的用户创建了具有高优先级的 Pod,并驱逐了所有其他 Pod。为了防止这种情况发生,ResourceQuota 已经扩展到支持 PriorityClass,较大的优先级数字被保留给关键的系统 Pod,通常不应该被抢占或驱逐。
总之,Pod 优先级应该谨慎使用,因为用户指定的数字优先级,指导调度器和 Kubelet 放置或杀死哪些 Pod,会受到用户的博弈。任何改变都可能影响许多 Pod,并可能阻止平台提供可预测的服务级别协议。
资源计划(Project Resources)
Kubernetes 是一个自助服务平台,开发者可以在指定的隔离环境上运行自己认为合适的应用。然而,在一个共享的多租户平台中工作,也需要存在特定的边界和控制单元,以防止一些用户消耗平台的所有资源。其中一个这样的工具是 ResourceQuota,它提供了用于限制命名空间中的聚合资源消耗的约束。通过 ResourceQuota,集群管理员可以限制计算资源(CPU、内存)和存储资源消耗的总和。它还可以限制在命名空间中创建的对象(如 ConfigMap、Secret、Pod 或 Service)的总数。
这方面的另一个有用的工具是 LimitRange,它允许为每种类型的资源设置资源使用限制。除了指定不同资源类型的最小和最大允许量以及这些资源的默认值外,它还允许您控制请求和限制之间的比率,也就是所谓的超额承诺水平(Overcommit Level)。表 2-1 给出了如何选择请求和限制的可能值的例子。
表 2-1 请求和限制的
LimitRange 对于控制容器资源配置文件很有用,这样就不会出现需要超过集群节点所能提供的资源的容器。它还可以防止集群用户创建消耗大量资源的容器,使节点无法为其他容器分配。考虑到请求(而不是限制)是调度器用来投放的主要容器特性,LimitRequestRatio 允许你控制容器的请求和限制之间的差距有多大。在请求和限制之间有很大的综合差距,会增加节点上过度投入的机会,并且当许多容器同时需要比最初请求更多的资源时,可能会降低应用性能。
容量规划(Capacity Planning)
考虑到容器在不同的环境中可能会有不同的资源配置,以及不同数量的实例,很明显,多用途环境的容量规划并不简单。例如,为了获得最佳的硬件利用率,在一个非生产集群上,你可能主要拥有 BestEffort 和 Burstable 容器。在这样的动态环境中,很多容器同时启动和关闭,即使有容器在资源饥渴时被平台杀死,也不会致命。在生产集群上,我们希望事情更加稳定和可预测,容器可能主要是 Guaranteed 类型,还有一些Burstable。如果一个容器被杀死了,那很可能是一个信号,说明集群的容量应该增加。表 2-2 列出了一些对 CPU 和内存有需求的服务。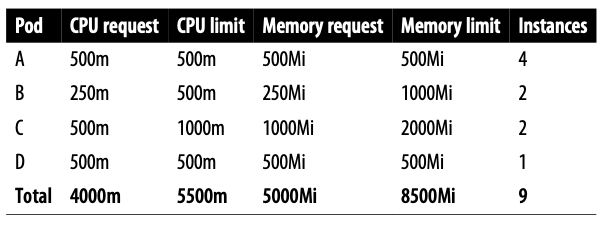
表 2-2 容量规划样例
当然,在现实生活中,你使用 Kubernetes 这样的平台,更可能的原因是需要管理的服务更多,有些服务即将退役,有些服务还在设计开发阶段。即使是一个不断移动的目标,根据前面描述的类似方法,我们可以计算出每个环境中所有服务所需的资源总量。
请记住,在不同的环境中,容器的数量也是不同的,你甚至可能需要为自动缩放、构建作业、基础设施容器等留出一些空间。根据这些信息和基础设施提供商,你可以选择性价比最高的计算实例,提供所需资源。
一些讨论
容器不仅对进程隔离和作为封装形式有用。在确定了资源概况后,它们也是成功进行能力规划的基石。执行一些早期测试以发现每个容器的资源需求,并将该信息作为未来容量规划和预测的基础。
然而,更重要的是,资源配置文件是应用程序与 Kubernetes 通信的方式,以协助调度和管理决策。如果你的应用没有提供任何请求或限制,Kubernetes 能做的就是把你的容器当作不透明的盒子,当集群满了的时候就会被丢弃。所以,每一个应用程序都或多或少地必须考虑和提供这些资源声明。
现在你已经知道了如何确定我们应用的大小,在第 3 章 “声明式部署” 中,你将学习多种策略来让我们的应用在 Kubernetes 上安装和更新。
参考资料

若有收获,就点个赞吧
0 人点赞
