批处理作业(Batch Job)模式适合管理孤立的原子工作单元。它以 Job 抽象为基础,在分布式环境中可靠地运行短暂运行的 Pod,直到完成。
问题描述
Kubernetes 中管理和运行容器的主要基本单元是 Pod。有不同的方法来创建具有不同特性的 Pod。
- 裸露的 Pod:可以手动创建一个 Pod 来运行容器。然而,当这种 Pod 运行的节点出现故障时,Pod 不会被重新启动。不鼓励以这种方式运行 Pod,除非出于开发或测试目的。这种机制也被称为非托管或裸露的 Pod。
ReplicaSet:该控制器用于创建和管理预期连续运行的 Pod 的生命周期(例如,运行一个 Web 服务器容器)。它维护了一组稳定的复制 Pod 在任何给定的时间运行,并保证了指定数量的相同 Pod 的可用性。DaemonSet:用于在每个节点上运行单个 Pod 的控制器。通常用于管理平台功能,如监控、日志聚合、存储容器等。关于 DaemonSet 的详细讨论,请参见第 9 章 “后台服务”(Daemon Service)。
这些 Pod 的一个共同点是,它们代表着长期运行的进程,并不是要在一段时间后停止。然而,在某些情况下需要可靠地执行一个预定义的有限工作单位,然后关闭容器。对于这个任务,Kubernetes 提供了 Job 资源。
解决方案
Kubernetes Job 与 ReplicaSet 类似,因为它创建了一个或多个 Pod,并确保它们成功运行。然而,不同的是,一旦预期数量的 Pod 成功终止,该作业就被认为是完成的,不再启动额外的 Pod。一个作业定义看起来像例 7-1。
# 例 7-1 一个 Job 的定义---apiVersion: batch/v1kind: Jobmetadata:name: random-generatorspec:# Job 应该运行五个 Pod 来完成,这五个 Pod 必须全部成功completions: 5# 两个 Pod 可以并行运行parallelism: 2template:metadata:name: random-generatorspec:# 指定 restartPolicy 对一个 Job 来说是强制性的restartPolicy: OnFailurecontainers:- image: k8spatterns/random-generator:1.0name: random-generatorcommand: [ "java", "-cp", "/", "RandomRunner", "/numbers.txt", "10000" ]
:::tips
Job 和 ReplicaSet 定义之间的一个关键区别是.spec.tem plate.spec.restartPolicy。ReplicaSet 的默认值是 Always,这对于必须始终保持运行的长期运行进程是有意义的。对于 Job 来说,不允许使用 Always 值,唯一可能的选项是 OnFailure 或 Never。
:::
那么为什么还要创建一个 Job 来运行一个Pod,而不是使用裸 Pod 呢?使用 Job 提供了许多可靠性和可扩展性的好处,使他们成为预先推断的选择:
- Job 不是一个短暂的内存任务,而是一个持久的任务,可以在集群重启后继续运行。
- 当一个任务完成后,它不会被删除,而是被保留下来用于跟踪。作为任务的一部分而创建的 Pod 也不会被删除,而是可供检查(例如,检查容器日志)。对于裸露的 Pod 也是如此,但只适用于
restartPolicy: OnFailure。 - 一个 Job 可能需要执行多次。使用
.spec.completions字段,可以指定一个 Pod 在 Job 本身完成之前应该成功完成多少次。 - 当一个 Job 需要多次完成时(通过
.spec.completions设置),它也可以通过同时启动多个 Pod 来缩放和执行。这可以通过指定.spec.parallelism字段来实现。 - 对于 Job,如果节点出现故障,或者当 Pod 因某种原因被驱逐而仍在运行时,调度器会将 Pod 放置在一个新的健康节点上并重新运行它。裸露的 Pod 将保持在失败的状态,因为现有的 Pod 永远不会被移动到其他节点上。
:::info 以上所有这些都使得 Job 对于那些需要对单位工作的完成进行一些保证的场景具有吸引力。 :::
在 Job 的行为中起主要作用的两个字段是:
.spec.completions:指定完成一个 Job 应该运行多少个 Pod。.spec.parallelism:指定多少个 Pod 复本可以并行运行。设置较高的数字并不能保证较高的并行性,实际的 Pod 数量可能仍然少于(在某些角落的情况下,更多)所需的数量(例如,由于节流、资源配额、剩余的完成量不够以及其他原因)。将该字段设置为0,可以有效地暂停作业。
图 7-1 显示了例 7-1 中定义的完成数为 5、并行度为 2 的批量任务的处理方式。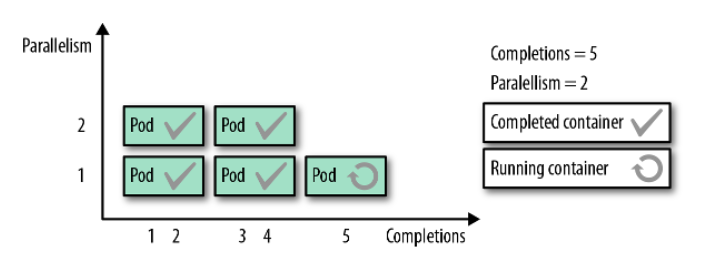
图 7-1 具有固定完成次数的并行批处理任务
根据这两个参数,有以下几种类型的 Job:
- 单舱作业(Single Pod Job):当您省略
.spec.completions和.spec.parallelism或将其设置为默认值之一时,将选择此类型。这样的作业只启动一个Pod,一旦单个 Pod 成功终止(退出代码为0),该作业就会完成。 - 固定完成次数的作业(Fixed Completion Count Jobs):当你指定
.spec.completions的数字大于 1 时,这许多 Pod 必须成功。您可以选择设置.spec.parallelism,或者将其保留为默认值 1。这样作业在.spec.completions数量的 Pod 成功完成后,就被认为是完成了。例 7-1 展示了这种模式的运行情况,当我们事先知道工作项的数量,并且单个工作项的处理成本证明了使用专用 Pod 的合理性时,这种模式是最佳选择。 - 工作队列作业(Work Queue Jobs):当您排除
.spec.completions并将.spec.parallelism设置为大于 1 的整数时,您就拥有了一个并行作业的工作队列。当至少有一个 Pod 成功终止,并且所有其他 Pod 也终止时,一个工作队列 Job 就被认为已经完成。这种设置需要 Pod 之间相互协调,确定每个 Pod 正在进行的工作,这样才能以协调的方式完成。例如,当队列中存储了固定但未知数量的工作项目时,并行的 Pod 可以逐一拾取这些工作项目进行处理。第一个检测到队列为空并成功退出的 Pod 表示作业完成。Job 控制器也会等待所有其他 Pod 终止。由于一个 Pod 处理多个工作项目,这种作业类型是细化工作项目的最佳选择 — 而为每个工作项目的一个 Pod 的开销是不合理的。
:::tips 如果您有无限的工作项目流要处理,其他控制器(如 ReplicaSet)是管理处理这些工作项目的 Pod 的更好选择。 :::
一些讨论
Job 是一个非常基本但也是基本的基本要素,其他基本要素如 CronJob 都是基于这个而形成的。Job 有助于将孤立的工作单元变成一个可靠的、可扩展的执行单元。然而,一个 Job 并不能决定你应该如何将单独的可处理的工作项目映射到 Job 或 Pod 中。这是您必须在考虑每个选项的优点和缺点后决定的事情。
- 每个工作项目一个 Job:这个选项有创建 Kubernetes Job 的开销,同时也湿的平台需要管理大量消耗资源的 Job。当每个工作项都是一个复杂的任务,必须独立记录、跟踪或缩放时,这个选项很有用。
- 所有工作项目的一个 Job:这个选项适用于大量的工作项目,这些工作项目不需要由平台永久地跟踪和管理。在这种情况下,必须通过批处理框架从应用程序内部管理工作项。
:::tips Job 只提供了最基本的工作项调度的基本功能。任何复杂的实现都必须将 Job 与批处理应用程序框架(例如,在 Java 生态系统中,我们将 Spring Batch 和 JBeret 作为标准实现)结合起来,才能达到预期的结果。 :::
不是所有的服务都必须一直运行。有些服务必须按需运行,有些在特定时间运行,有些则是周期性运行。使用 Job 可以只在需要的时候运行 Pod,并且只在任务执行期间运行。Job 被安排在具有所需容量的节点上,满足 Pod 放置策略和其他容器依赖性考虑。使用 Job 来执行短时任务,而不是使用长期运行的抽象(如 ReplicaSet),可以为平台上的其他工作负载节省资源。所有这些都使得 Job 成为一个独特的核心资源,也使得 Kubernetes 成为一个支持多样化工作负载的平台。
参考资料

若有收获,就点个赞吧
0 人点赞
