自动放置(Automated Placement)是 Kubernetes 调度器的核心功能,用于将新的 Pod 分配给满足容器资源请求的节点,并尊重调度策略。该模式描述了 Kubernetes 的调度算法的原理以及从外部影响放置决策的方式。
问题描述
一个合理规模的基于微服务的系统由几十个甚至几百个孤立的进程组成。容器和 Pod 确实为打包和部署提供了很好的抽象,但并不能解决将这些进程放在合适的节点上的问题。由于微服务的数量庞大且不断增长,将它们单独分配和放置到节点上并不是一件容易管理的事情。
容器之间有依赖性,对节点的依赖性,以及资源需求,而所有这些也会随着时间的推移而改变。集群上的可用资源也会随着时间的推移而变化,通过收缩或扩展集群,或者被已经放置的容器消耗掉。我们放置容器的方式也会影响分布式系统的可用性、性能和容量。所有这些都使得将容器调度到节点上成为一个移动的目标,必须在移动中射击。
解决方案
在 Kubernetes 中,将 Pod 分配给节点是由调度器完成的。截至本文撰写时,这是一个可配置性很强、仍在发展、变化很快的领域。在本章中,我们将介绍主要的调度控制机制、影响放置的驱动力、为什么要选择一个或另一个选项,以及由此产生的结果。Kubernetes 调度器是一个有力且省时的工具。它在整个 Kubernetes 平台中起着基础性的作用,但与其他 Kubernetes 组件(API Server、Kubelet)类似,它可以单独运行,也可以完全不用。
在很高的层面上,Kubernetes 调度器执行的主要操作是从 API Server 中检索每个新创建的 Pod 定义,并将其分配给一个节点。它为每一个 Pod 找到一个合适的节点(只要有这样的节点),无论是最初的应用放置、扩展,还是将一个应用从一个不健康的节点转移到一个更健康的节点时。它通过考虑运行时的依赖性、资源需求和高可用性的指导策略,通过水平分布 Pod,也通过将 Pod 集中在附近进行性能和低延迟的交互来实现。然而,为了让调度器正确地完成它的工作,并允许声明式的放置,它需要有可用容量的节点,以及有声明式资源配置文件和指导策略的容器。让我们更详细地看看其中的每一个。
可用节点资源
首先,Kubernetes 集群需要有足够资源容量的节点来运行新的 Pod。每个节点都有可用于运行 Pod 的容量,调度器确保一个 Pod 所请求的资源之和小于可用的可分配节点容量。考虑到一个只专用于 Kubernetes 的节点,它的容量使用例 6-1 中的公式计算。
# 例 6-1 节点容量技术公式Allocatable [capacity for application pods] =Node Capacity [available capacity on a node]- Kube-Reserved [Kubernetes daemons like kubelet, container runtime]- System-Reserved [OS system daemons like sshd, udev]
:::danger 如果你没有为给操作系统和 Kubernetes 本身提供动力的系统守护进程预留资源,那么 Pod 的排程可能会达到节点的全部容量,这可能会导致 Pod 和系统守护进程争夺资源,导致节点上的资源饥饿问题。同时要记住,如果容器运行在一个不由 Kubernetes 管理的节点上,也会反映在 Kubernetes 的节点容量计算中。 :::
:::tips 这种限制的变通方法是运行一个占位 Pod,它不做任何事情,但只有 CPU 和内存的资源请求,对应于未跟踪的容器的资源使用量。创建这样的 Pod 只是为了表示和保留未跟踪容器的资源消耗量,帮助调度器建立更好的节点资源模型。 :::
容器资源需求
高效的 Pod 放置的另一个重要要求是,容器有其运行时的依赖性和资源需求的定义。我们在第 2 章 “可预测的需求” 中详细介绍了这一点。归根结底,容器要声明它们的资源配置文件(有请求和限制)和环境依赖性,如存储或端口。只有这样,Pod 才会被合理地分配到节点上,并能在高峰期不影响彼此的运行。
放置策略
最后一块拼图是拥有正确的过滤或优先级策略来满足你的特定应用需求。调度器配置了一套默认的谓词和优先级策略,这对大多数应用来说已经足够好了,它可以在调度器启动时用不同的策略来覆盖,如例 6-2 所示,在调度程序启动时,可以用不同的策略来覆盖它。
:::info 调度器策略和自定义调度器只能由管理员定义,作为集群配置的一部分。作为普通用户,你只需要参考预定义的调度程序。 :::
// 例 6-2 一个调度器策略的示例
{
"kind" : "Policy",
"apiVersion" : "v1",
// Predicate 是过滤掉不合格节点的规则
// 例如,PodFitsHostsPorts 安排 Pod 只在那些还有这个端口的节点上请求某些固定的主机端口
"predicates" : [
{"name" : "PodFitsHostPorts"},
{"name" : "PodFitsResources"},
{"name" : "NoDiskConflict"},
{"name" : "NoVolumeZoneConflict"},
{"name" : "MatchNodeSelector"},
{"name" : "HostName"}
],
// 优先级是根据偏好对可用节点进行排序的规则
// 例如,LeastRequestedPriority 给予请求资源较少的节点较高的优先级
"priorities" : [
{"name" : "LeastRequestedPriority", "weight" : 2},
{"name" : "BalancedResourceAllocation", "weight" : 1},
{"name" : "ServiceSpreadingPriority", "weight" : 2},
{"name" : "EqualPriority", "weight" : 1}
]
}
:::success
考虑到除了配置默认调度器的策略外,还可以运行多个调度器,并允许 Pod 指定放置哪个调度器。你可以启动另一个配置不同的调度器实例,给它一个唯一的名字。然后在定义 Pod 时,只要在 Pod 规范中添加字段 .spec.schedulerName,写上你自定义调度器的名称,Pod 就会只被自定义调度器接收。
:::
调度过程
Pod 根据放置策略被分配到具有一定容量的节点上。为了完整起见,图 6-1 在高层次上直观地展示了这些元素是如何结合在一起的,以及 Pod 在被调度时经历的主要步骤。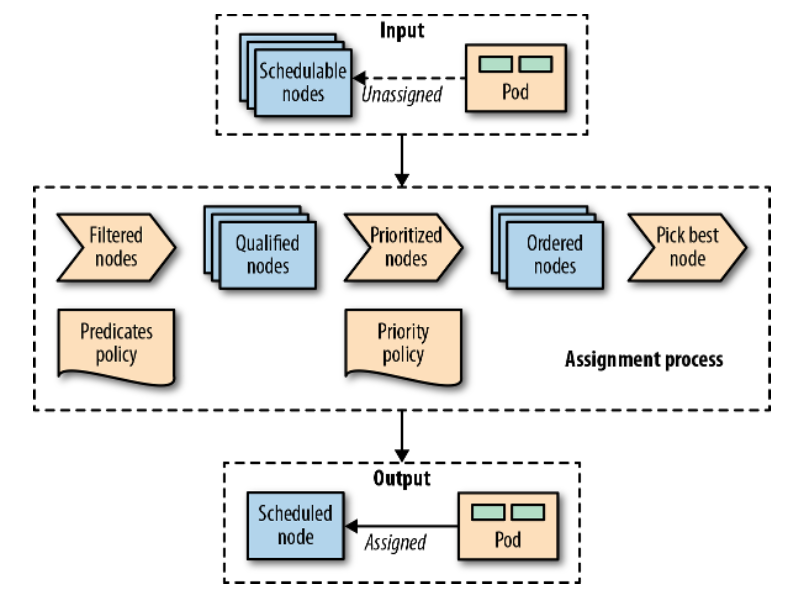
图 6-1 Pod 在被调度时经历的主要步骤
:::info 一旦创建了一个尚未分配给节点的 Pod,它就会被调度器挑选出来,连同所有可用的节点以及过滤和优先级策略集。在第一阶段,调度器应用过滤策略,并根据 Pod 的标准删除所有不符合条件的节点。在第二阶段,剩余的节点得到按权重排序。在最后阶段,Pod 得到一个节点分配,这是调度过程的主要结果。 :::
在大多数情况下,最好是让调度程序来完成 Pod 到节点的分配,而不是微观管理放置逻辑。然而,在某些情况下,你可能想强制将 Pod 分配给一个特定的节点或一组节点。这种分配可以使用节点选择器来完成。.spec.nodeSelector 是 Pod 字段,指定了一个键值对的映射,这些键值对必须作为标签存在于节点上,该节点才有资格运行 Pod。例如,假设你想强制 Pod 运行在有 SSD 存储或 GPU 加速硬件的特定节点上。例 6-3 中的 Pod 定义有 nodeSelector 匹配 disktype: ssd,只有标签为 disktype=ssd 的节点才有资格运行 Pod。
# 例 6-3 基于可用磁盘类型的节点选择器
---
apiVersion: v1
kind: Pod
metadata:
name: random-generator
spec:
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
nodeSelector:
# 节点标签集,一个节点必须与之匹配才能被认为是这个 Pod 的节点
disktype: ssd
:::tips
除了给节点指定自定义标签外,你还可以使用一些每个节点上都有的默认标签。每个节点都有一个唯一的 kubernetes.io/hostname 标签,可以通过它的主机名将 Pod 放在节点上。其他表示操作系统、架构和实例类型的默认标签也可以用于放置。
:::
节点亲和性(Node Affinity)
Kubernetes 支持许多更灵活的方式来配置调度过程。节点亲和性就是这样的一个特性,它是之前描述的节点选择器方法的泛化,允许将规则指定为硬性或柔性。硬性的规则必须满足,Pod 才会被调度到某个节点,而柔性规则只是通过增加匹配节点的权重来暗示优先,而不是强制性的。此外,节点亲和性功能极大地扩展了你可以表达的约束类型,通过使用 In、NotIn、Exists、DoesNotExist、Gt 或 Lt 等运算符使语言更具表现力。 例 6-4 演示了如何声明节点亲和性。
# 例 6-4 配置了节点亲和性的 Pod 示例
---
apiVersion: v1
kind: Pod
metadata:
name: random-generator
spec:
affinity:
nodeAffinity:
# 硬性要求节点必须有三个以上的核心(用节点标签表示)才能在调度过程中被考虑
# 在执行过程中,如果节点上的条件发生变化,该规则不会被重新评估
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
# 基于标签进行匹配
- matchExpressions:
- key: numberCores
operator: Gt
values: [ "3" ]
# 柔性需求,是一个带有权重的选择器列表
# 对于每一个节点,计算出所有匹配选择器的权重之和,只要符合硬需求,就选择价值最高的节点
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
# 匹配一个字段(指定为 JSONPath)
# 请注意,只有 In 和 NotIn 可以作为操作符,并且在值列表中只允许给出一个值
matchFields:
- key: metadata.name
operator: NotIn
values: [ "master" ]
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
Pod 亲和性和反亲和性(Pod Affinity and Antiaffinity)
节点亲和性是一种更强大的调度方式,当 nodeSelector 不够用时,应该首选。这种机制允许根据标签或字段匹配来约束一个 Pod 可以运行的节点。它不允许表达 Pod 之间的依赖关系,来决定一个 Pod 相对于其他 Pod 应该放在哪里。为了表达 Pod 应该如何分布以实现高可用性,或者被打包并共同放置在一起以改善延迟,可以使用 Pod 亲和性和反亲和性。
:::tips
节点亲和性在节点粒度上起作用,但 Pod 亲和性并不局限于节点,可以在多个拓扑层次上表达规则。使用 topologyKey 字段和匹配的标签,可以执行更细粒度的规则,这些规则结合了节点、机架、云提供商区域和区域等域的规则,如例 6-5 所示。
:::
# 例 6-5 配置了 Pod 亲和性的 Pod 示例
---
apiVersion: v1
kind: Pod
metadata:
name: random-generator
spec:
affinity:
podAffinity:
# 关于目标节点上运行的其他 Pod 的硬性要求
requiredDuringSchedulingIgnoredDuringExecution:
# 标签选择器,以找到要与之共处的 Pod
- labelSelector:
matchLabels:
confidential: high
# 标签为 confidential=high 的 Pod 运行的节点上应该带有一个标签 security-zone
# 这里定义的 Pod 被安排到具有相同标签和值的节点上
topologyKey: security-zone
# 通过反亲和性规则来确定不会放置 Pod 的节点
podAntiAffinity:
# 规则描述了 Pod 不应该(但可以)被放置在某些特定的节点上
# 在这些节点上,有一个标签为 confidential=none 的 Pod 正在运行
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchLabels:
confidential: none
topologyKey: kubernetes.io/hostname
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
与节点亲和性类似,Pod 亲和性和反亲和性也有硬性要求和柔性要求,分别称为 requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution。同样,和节点亲和性一样,字段名中也有 IgnoredDuringExecution 的后缀,这是为了将来的可扩展性而存在的。目前,如果节点变化和亲和性规则上的标签不再有效,Pod 就会继续运行,但在未来的运行时变化也可能被考虑在内(如果节点标签发生变化,并允许未调度的 Pod 与其节点亲和性选择器相匹配,这些 Pod 就会被调度到这个节点上)。
污点和容忍(Taints and Tolerations)
一个更高级的功能是基于污点和容忍来控制 Pod 可以被安排和允许运行的地方。节点亲和性是 Pod 的一个属性,允许他们选择节点,而污点和容忍则相反。它们允许节点控制哪些 Pod 应该或不应该被安排在它们上面。污点是节点的一个特性,当它存在时,它阻止 Pod 调度到节点上,除非 Pod 对污点有容忍度。从这个意义上说,污点和容忍可以被认为是一种选择,允许在节点上进行调度,默认情况下这些节点是不可用的,而亲和规则是一种选择,通过明确地选择在哪些节点上运行,从而排除所有非选择的节点。
通过 kubectl 给节点添加污点:kubectl taint nodes master node-role.kubernetes.io/master="true":NoSchedule,效果如例 6-6 所示。如例 6-7 所示,将匹配的 toleration 添加到 Pod 中。注意,例 6-6 中 taints 部分的 key 和 effect 的值和例 6-7 中 tolerations: 部分的值是一样的。
# 例 6-6 带污点的节点
---
apiVersion: v1
kind: Node
metadata:
name: master
spec:
# 在节点的上标记污点,将此节点标记为不可调度,除非当一个 Pod 容忍这个污点
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
# 例 6-7 Pod 容忍节点污点
---
apiVersion: v1
kind: Pod
metadata:
name: random-generator
spec:
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
tolerations:
# 容忍(即考虑用于调度)节点,该节点有一个污点,其关键节点为 node-role.kubernetes.io/master
# 在生产集群上,这个污点被设置在主节点上,以防止在主节点上调度 Pod,这样的 toleration 允许这个 Pod 还是可以部署在 master 上
- key: node-role.kubernetes.io/master
operator: Exists
# 仅当污点指定了 NoSchedule 效果时才会被容忍
# 此字段可以为空,在这种情况下,容忍度适用于每个效果
effect: NoSchedule
:::tips
有防止在节点上调度的硬污点(effect=NoSchedule),有尽量避免在节点上调度的软污点(effect=PreferNoSchedule),还有可以从节点上驱逐已经运行的 Pod 的污点(effect=NoExecute)。
:::
:::success 污点和容忍允许复杂的用例,比如为一组专属的 Pod 设置专用节点,或者通过污染这些节点来强制从有问题的节点驱逐 Pod。 :::
你可以根据应用的高可用性和性能需求来影响放置,但尽量不要对调度器限制太多,让自己退到一个不能再调度 Pod 而滞留的资源却太多的窘境。例如,如果你的容器的资源需求粒度太粗,或者节点太小,最终可能会出现节点中的资源滞留,无法利用的情况。
在图 6-2 中,我们可以看到节点 A 有 4GB 的内存无法利用,因为没有 CPU 留给其他容器放置。创建资源需求较小的容器可能有助于改善这种情况。另一个解决方案是使用 Kubernetes Descheduler,它有助于分解节点,提高节点的利用率。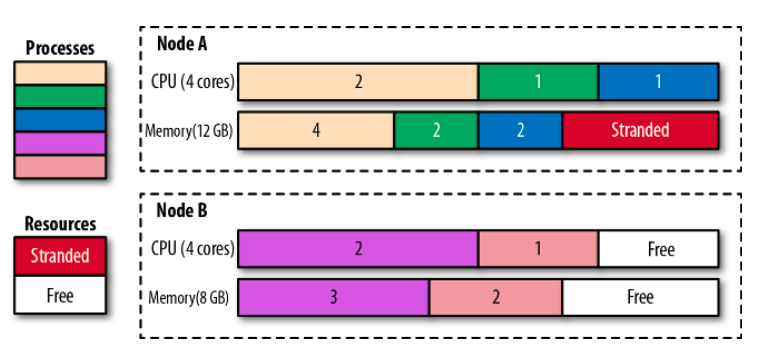
图 6-2 调度进入节点的进程和滞留的资源
一旦 Pod 被分配到一个节点上,调度器的工作就完成了,它不会改变 Pod 的位置,除非在没有节点分配的情况下删除和重新创建 Pod。正如你所看到的,随着时间的推移,这可能会导致资源碎片化和集群资源利用率低下。另一个潜在的问题是,当一个新的 Pod 被调度时,调度器的决策是基于其集群视图的。如果一个集群是动态的,节点的资源情况发生了变化,或者增加了新的节点,调度器就不会纠正之前的 Pod 放置。除了改变节点容量,还可以改变节点上的标签,影响放置,但过去的放置也不会被纠正。
这些都是 Descheduler 可以解决的场景。Kubernetes Descheduler 是一个可选的功能,通常在集群管理员决定是时候通过重新安排 Pod 来整顿和碎片化集群的时候,就会以 Job 的形式运行。Descheduler 带有一些预定义的策略,可以启用、调整或禁用。这些策略以文件的形式传递给 Descheduler Pod,目前,它们有以下几种:
RemoveDuplicated:该策略可确保单个节点上只运行与 ReplicaSet 或 Deployment 相关联的单个 Pod。如果有比一个更多的 Pod,这些多余的 Pod 将被驱逐。该策略在节点变得不健康的情况下非常有用,管理控制器在其他健康节点上启动了新的 Pod。当不健康的节点恢复并加入集群时,运行的 Pod 数量超过了预期,Descheduler 可以帮助将数量恢复到预期的复制数。当调度策略和集群拓扑结构在初始放置后发生变化时,去除节点上的重复也可以帮助 Pod 在更多节点上均匀分布。LowNodeUtilization:该策略可以找到未被充分利用的节点,并从其他利用率过高的节点上驱逐 Pod,希望这些 Pod 能放在未被充分利用的节点上,从而更好地分散和利用资源。利用不足的节点被识别为 CPU、内存或 Pod 数量低于配置阈值值的节点。同样,过度利用的节点是指那些值大于配置的目标阈值的节点。介于这些值之间的任何节点都会被适当地利用,不受该策略的影响。RemovePodsViolatingInterPodAntiAffinity:这个策略可以驱逐违反 Pod 间反亲和性规则的 Pod,当反亲和性规则是在 Pod 被放置在节点上后添加的时候,就会发生这种情况。RemovePodsViolatingNodeAffinity:这个策略是用来驱逐违反节点亲和规则的 Pod 的。
无论使用什么策略,Descheduler 都能避免驱逐以下内容:
- 标有
scheduler.alpha.kubernetes.io/critical-pod注释的关键 Pod。 - 不由 ReplicaSet、Deployment 或 Job 管理的 Pod。
- 由 DaemonSet 管理的 Pod。
- 具有本地存储的 Pod 。
- 具有
PodDisruptionBudget的 Pod,驱逐会违反其规则。 - Deschedule Pod 本身(通过将自身标记为关键 Pod 实现)。
当然,所有的驱逐都会尊重 Pod 的 QoS 水平,首先选择 Best-Efforts Pod,然后是 Burstable Pod,最后是 Guaranteed Pod 作为驱逐的候选者。关于这些 QoS 级别的详细解释,请参见第 2 章 “可预测的需求”。
一些讨论
放置是一个你希望尽可能少干预的领域。如果你遵循第 2 章 “可预测的需求” 中的指导原则,并声明容器的所有资源需求,调度器就会完成它的工作,并将 Pod 放置在尽可能合适的节点上。然而,当这还不够时,有多种方法可以引导调度器朝向所需的部署拓扑。综上所述,从简单到复杂,以下方法控制了 Pod 调度(请记住,截至本文撰写时,这个列表会随着 Kubernetes 的每一个其他版本而变化)。
nodeName:将 Pod 硬连接到节点的最简单形式。这个字段最好由调度器填充,它由策略驱动,而不是手动分配节点。将 Pod 分配到节点上,大大限制了 Pod 的调度范围。这让我们回到了前 Kubernetes 时代,当时我们明确地规定了运行应用的节点。nodeSelector:指定键值对的映射。为了使 Pod 有资格在节点上运行,Pod 必须有指定的键值对作为节点上的标签。在 Pod 和节点上贴上一些有意义的标签后(无论如何你都应该这么做),节点选择器是控制调度器选择的最简单可接受的机制之一。- 默认的调度变更:默认的调度器负责将新的 Pod 放置到集群内的节点上,而且它做得很合理。然而,如果有必要,可以改变这个调度器的过滤和优先策略列表、顺序和权重。
- Pod 的亲和性和反亲和性:这些规则允许一个 Pod 表达对其他 Pod 的依赖性。例如,对于应用程序的延迟要求、高可用性、安全约束等。
- 节点亲和力:这个规则允许 Pod 向节点表达依赖性。例如,考虑到节点的硬件、位置等。
- 污点和容忍:污点和容忍允许节点控制哪些 Pod 应该或不应该被安排在它们身上。例如,为一组 Pod 奉献一个节点,甚至在运行时驱逐 Pod。污点和容忍的另一个优点是,如果你通过添加新的标签的新节点来扩展 Kubernetes 集群,你不需要在所有的 Pod 上添加新的标签,而只需要在应该放在新节点上的 Pod 上添加。
- 自定义调度器:如果前面的方法都不够好,或者你有复杂的调度需求,你也可以编写你的自定义调度器。自定义的调度器可以代替标准的 Kubernetes 调度器运行,也可以和标准的 Kubernetes 调度器一起运行。一个混合的方法是有一个“调度扩展器”进程,标准的 Kubernetes 调度器在做调度决定时调用它作为最后的通道。这样你就不必实现一个完整的调度器,而只需要提供 HTTP API 来过滤和优先处理节点。拥有你的自定义调度器的好处是,你可以考虑 Kubernetes 集群之外的因素,比如硬件成本、网络延迟和更好的利用率,同时将 Pod 分配给节点。你也可以在默认调度器旁边使用多个自定义调度器,并配置每个 Pod 使用哪个调度器。每个调度器可以有一套不同的策略,专门用于 Pod 的子集。
正如你所看到的,有很多方法可以控制 Pod 的放置,选择合适的方法或者将多种方法结合在一起是很有挑战性的。本章的启示是:确定容器资源配置文件的大小和声明,给 Pod 和节点打上相应的标签,最后,只对 Kubernetes 调度器做最小的干预。
参考资料
- Automated Placement Example
- Assigning Pods to Nodes
- Node Placement and Scheduling Explained
- Pod Disruption Budget
- Guaranteed Scheduling for Critical Add-On Pods
- Configuring Multiple Schedulers
- Descheduler for Kubernetes
- Keep Your Kubernetes Cluster Balanced: The Secret to High Availability
- Everything You Ever Wanted to Know About Resource Scheduling, but Were Afraid to Ask

若有收获,就点个赞吧
0 人点赞
