1、微服务架构
https://www.zhihu.com/question/65502802
单体应用vs微服务架构
优点
- 提升开发交流,每个服务足够内聚,足够小,代码容易理解;
- 服务独立测试、部署、升级、发布;
- 按需定制的DFX,资源利用率,每个服务可以各自进行x扩展和z扩展,而且,每个服务可以根据自己的需要部署到合适的硬件服务器上;每个服务按
- 需要选择HA的模式,选择接受服务的实例个数;
- 容易扩大开发团队,可以针对每个服务(service)组件开发团队;
- 提高容错性(fault isolation),一个服务的内存泄露并不会让整个系统瘫痪;
- 新技术的应用,系统不会被长期限制在某个技术栈上;
缺点
- 没有银弹,微服务提高了系统的复杂度;
- 开发人员要处理分布式系统的复杂性;
- 服务之间的分布式通信问题;
- 服务的注册与发现问题;
- 服务之间的分布式事务问题;
- 数据隔离再来的报表处理问题;
- 服务之间的分布式一致性问题;
- 服务管理的复杂性,服务的编排;
- 不同服务实例的管理。
作者:华为云开发者社区
链接:https://www.zhihu.com/question/65502802/answer/615568011
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2、测试用例
测试用例(Test Case)是将软件测试的行为活动做一个科学化的组织归纳,目的是能够将软件测试的行为转化成可管理的模式;同时测试用例也是将测试具体量化的方法之一,不同类别的软件,测试用例是不同的。 [1]
测试用例的设计方法主要有黑盒测试法和白盒测试法。 [1]
黑盒测试也称功能测试,黑盒测试着眼于程序外部结构,不考虑内部逻辑结构,主要针对软件界面和软件功能进行测试。 [1]
白盒测试又称结构测试、透明盒测试、逻辑驱动测试或基于代码的测试。白盒法全面了解程序内部逻辑结构、对所有逻辑路径进行测试。
3、云服务器
云服务器的业内名称其实叫做计算单元。
云服务器是云计算服务的重要组成部分,是面向各类互联网用户提供综合业务能力的服务平台。平台整合了传统意义上的互联网应用三大核心要素:计算、存储、网络,面向用户提供公用化的互联网基础设施服务。
云服务器平台的每个集群节点被部署在互联网的骨干数据中心,可独立提供计算、存储、在线备份、托管、带宽等互联网基础设施服务。
4、数据服务接口类型
大数据各个组件对外接口类型
| ** | 安全模式支持的接口类型 | 普通模式支持的接口类型 |
|---|---|---|
| Elasticsearch | JAVA、REST | JAVA、REST |
| Flink | CLI、JAVA、Scala、REST | CLI、JAVA、Scala、REST |
| Flume | JAVA | JAVA |
| GraphBase | CLI、JAVA、REST | CLI、JAVA、REST |
| HBase | CLI、JAVA、Sqlline、JDBC | CLI、JAVA、Sqlline、JDBC |
| HDFS | CLI、JAVA、C、REST | CLI、JAVA、C、REST |
| Hive | CLI、JDBC、ODBC、Python、REST(仅限WebHCat) | CLI、JDBC、Python、REST(仅限WebHCat) |
| Kafka | CLI、JAVA | CLI、JAVA、Scala |
| Loader | CLI、REST | CLI、REST |
| Manager | CLI、SNMP、Syslog、REST | CLI、SNMP、Syslog、REST |
| Mapreduce | JAVA、REST | JAVA、REST |
| Oozie | CLI、JAVA、REST | CLI、JAVA、REST |
| Pollux | CLI、JDBC | CLI、JDBC |
| Redis | CLI、JAVA | CLI、JAVA |
| Solr | CLI、JAVA、REST | CLI、JAVA、REST |
| Spark | CLI、JAVA、Scala、Python、JDBC、REST | CLI、JAVA、Scala、Python、JDBC、REST |
| Spark2x | CLI、JAVA、Scala、Python、JDBC、REST | CLI、JAVA、Scala、Python、JDBC、REST |
| Storm | CLI、JAVA | CLI、JAVA |
| Yarn | CLI、JAVA、REST | CLI、JAVA、REST |
对于开发接口:功能性的接口,可以两个系统连接。大数据提供接口更多是统计分析,对时效性要求不高的数据。
实时接口:也会存历史的数据。
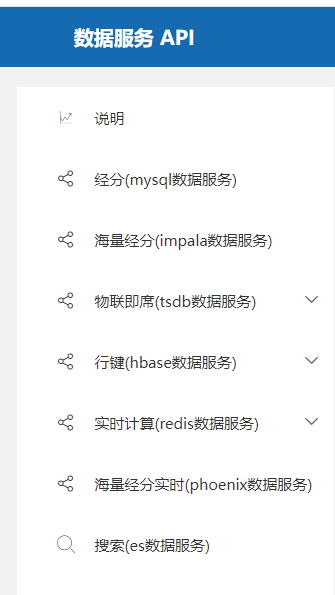
ES接口、Phoenix接口、BI接口特点及差异:
Elasticsearch 是面向文档型数据库,这意味着它存储的是整个对象或者文档,不但会存储它们,还会为他们建立索引,这样你就可以搜索他们了。我们可以在 Elasticsearch 中索引、搜索、排序和过滤这些文档。不需要成行成列的数据。这将会是完全不同的一种面对数据的检索方式,这也是为什么 Elasticsearch 可以执行复杂的全文搜索的原因。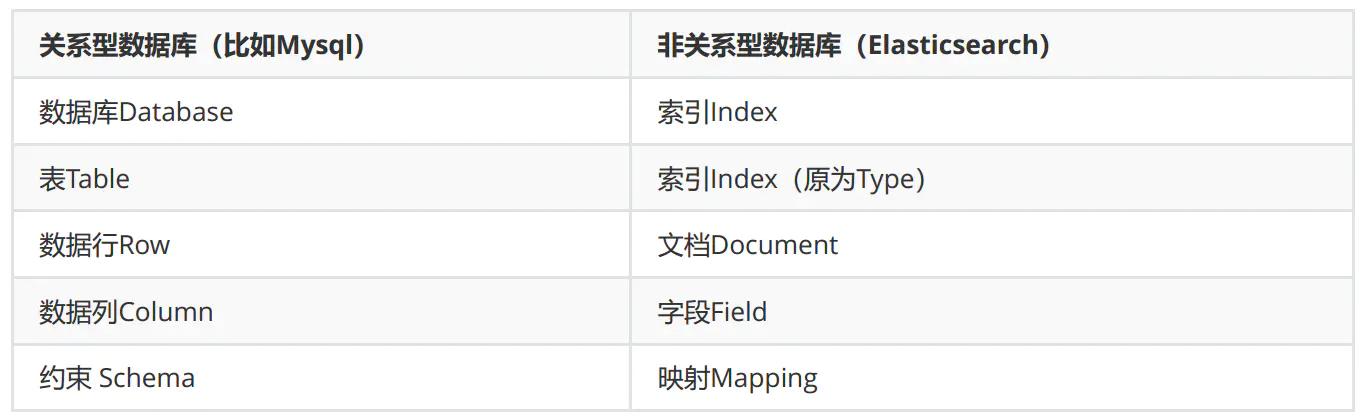
5、GET和POST两种基本请求方法的区别、优缺点
最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数。
- GET在浏览器回退时是无害的,而POST会再次提交请求。
- GET产生的URL地址可以被Bookmark,而POST不可以。
- GET请求会被浏览器主动cache,而POST不会,除非手动设置。
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求在URL中传送的参数是有长度限制的,而POST么有。
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET参数通过URL传递,POST放在Request body中。
1)区别
(1)post更安全(不会作为url的一部分,不会被缓存、保存在服务器日志、以及浏览器浏览记录中)
(2)post发送的数据更大(get有url长度限制)
(3)post能发送更多的数据类型(get只能发送ASCII字符)
(4)post比get慢
(5)post用于修改和写入数据,get一般用于搜索排序和筛选之类的操作
(6)get请求的是静态资源,则会缓存,如果是数据,则不会缓存2)为什么get比post更快
1.post请求包含更多的请求头
因为post需要在请求的body部分包含数据,所以会多了几个数据描述部分的首部字段(如:content-type),这其实是微乎其微的。
2.最重要的一条,post在真正接收数据之前会先将请求头发送给服务器进行确认,然后才真正发送数据3)post请求的过程:
(1)浏览器请求tcp连接(第一次握手)
(2)服务器答应进行tcp连接(第二次握手)
(3)浏览器确认,并发送post请求头(第三次握手,这个报文比较小,所以http会在此时进行第一次数据发送)
(4)服务器返回100 Continue响应
(5)浏览器发送数据
(6)服务器返回200 OK响应4)get请求的过程:
(1)浏览器请求tcp连接(第一次握手)
(2)服务器答应进行tcp连接(第二次握手)
(3)浏览器确认,并发送get请求头和数据(第三次握手,这个报文比较小,所以http会在此时进行第一次数据发送)
(4)服务器返回200 OK响应
也就是说,目测get的总耗是post的2/3左右,这个口说无凭,网上已经有网友进行过测试。5)get传参最大长度的理解误区
(1)http协议并未规定get和post的长度限制
(2)get的最大长度限制是因为浏览器和web服务器限制了URL的长度
(3)不同的浏览器和web服务器,限制的最大长度不一样
(4)要支持IE,则最大长度为2083byte,若支持Chrome,则最大长度8182byte。
6、消息队列常见的几种使用场景介绍
https://blog.csdn.net/rlnLo2pNEfx9c/article/details/80906308?utm_term=%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97%E5%A4%84%E7%90%86%E6%95%B0%E6%8D%AE&utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~sobaiduweb~default-3-80906308&spm=3001.4430
https://baijiahao.baidu.com/s?id=1708572554459077699&wfr=spider&for=pc
7、Kafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
主要特性:
Kafka [1] 是一种高吞吐量 [2] 的分布式发布订阅消息系统,有如下特性:
通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
高吞吐量 [2] :即使是非常普通的硬件Kafka也可以支持每秒数百万 [2] 的消息。
支持通过Kafka服务器和消费机集群来分区消息。
支持Hadoop并行数据加载。 [3]
Kafka通过官网发布了最新版本3.0.0 [4] [6]
8、flink
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
9、测试
什么是 单元测试(Unit Testing)?
颗粒度最小,一般由开发小组采用白盒方式来测试,主要测试单元是否符合“设计”;是指对软件中的最小可测试单元进行检查和验证。
什么是 集成测试?
介于单元测试和系统测试之间,一般由开发小组采用白盒+黑盒的方法来测试,即验证“设计”又验证“需求”。主要用来测试模板与模板之间的接口,同时还要测试一些主要的业务功能。
什么是 系统测试?
颗粒度最大,一般由独立的测试小组采用黑盒的方式来测试,主要测试系统是否符合“需求规格说明书”。在经过以上各阶段测试确认后,把系统完整的模拟客户环境来进行测试。
什么是 白盒测试?
主要应用于单元测试阶段,主要是对代码级别的测试,针对程序内部的逻辑结构。测试的手段有:语句覆盖、判定覆盖、条件覆盖、路径覆盖和条件组合覆盖。
什么是 黑盒测试?
不考虑程序内部结构和逻辑结构,主要是测试系统的功能是否满足“需求规格说明书”。一般会有一个输入值和一个输出值,和期望值做比较。黑盒测试也被称为功能测试或数据驱动测试,它是通过测试来检测每个功能是否都能正常使用。
10、存储引擎说明
目前存储引擎包括:Hive、Kudu 、Impala、Spark、Hbase、Tsdb,形成码表如下:
| 序号 | 存储引擎标识 | 存储引擎 | 应用场景说明 |
|---|---|---|---|
| 1 | h | Hive | 离线数仓:T+1、频率小于1小时的数据加工场景 |
| 2 | k | Kudu | |
| 3 | i | Impala | |
| 4 | s | Spark | |
| 5 | hb | HBase | 非结构化数据:如轨迹数据等 |
| 6 | ts | Tsdb | 时序数据:物联数据 |

若有收获,就点个赞吧
0 人点赞
