
1、数据分析
数据分析5步闭环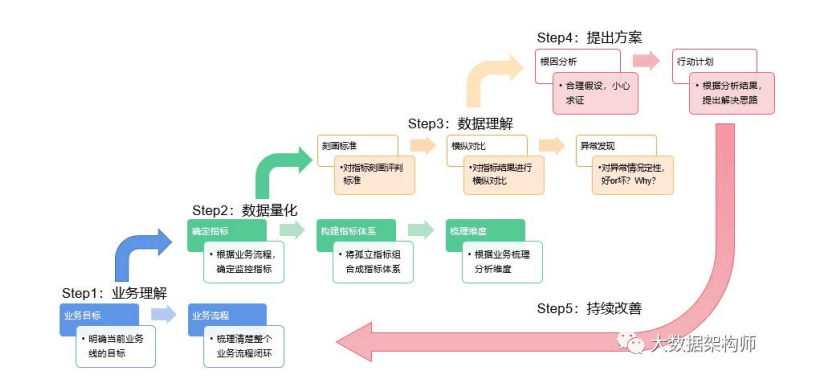
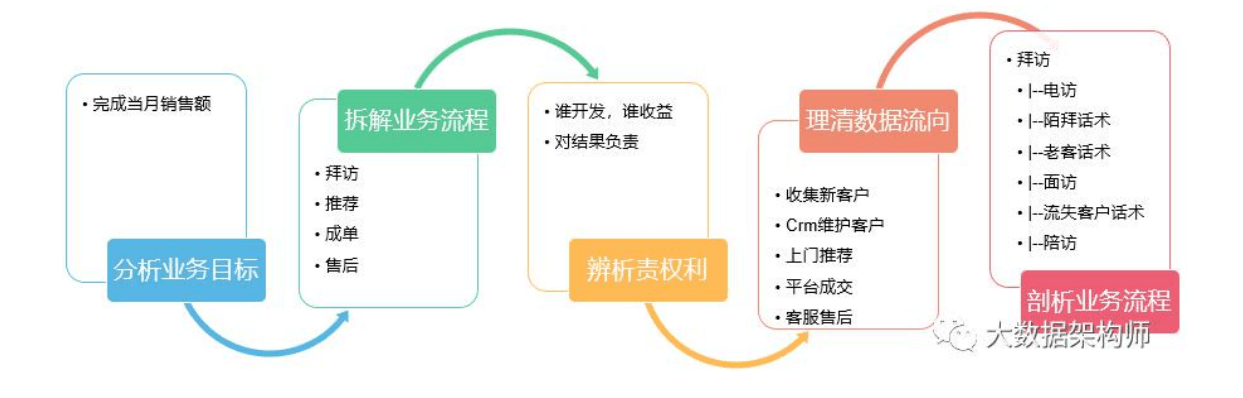
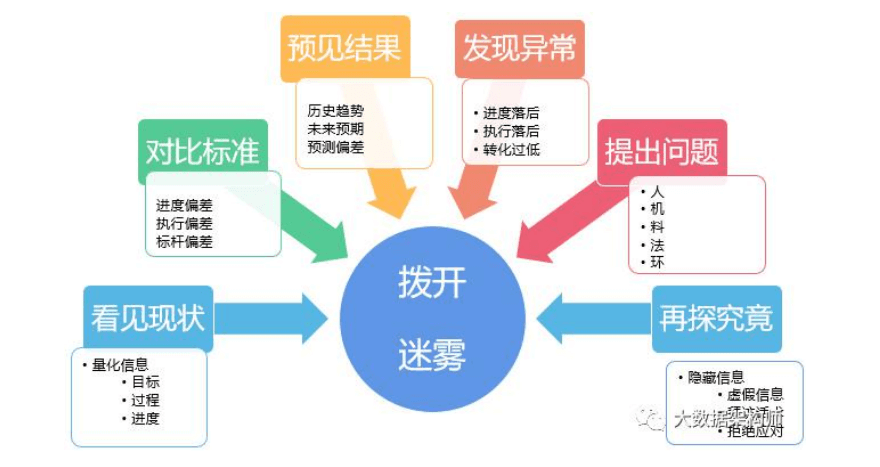
大数据分析平台包括:一堆的服务器、数据采集与处理、分布式 存储、计算引擎、数据仓库,其中还分为离线和实时两条技术线。
大数据分析包括:指标体系、维度、固定报表、多维分析、即席 查询、专题分析等。
大数据挖掘包括:标签体系、算法开发平台、推荐系统、预警预 测等各种模型及应用 。
企业的数据分析体系:
内部感知系统:及时告知各项内部运营参数; 外部感知系统:及时反馈外部竞争、机会状况; 报警系统:及时发现并报告各项异常,并指明故障点; 导航系统:根据设定的目标,提供可到达的若干方案,根据当前 方案和位置,指明下一步行动方向,对目标进行合理预测,实时反馈 当前执行情况。
数据指的不仅仅是服务器上存储的数据,还有市场竞争、老板的 格局、业务负责人的专业知识、业务员的销售技巧,以及客户的想法;
业务指的不仅仅是业务线,还有公司战略、商业模式、盈利模式、 潜在机会、流程优化、精细化运营、精准营销、定价模型,以及客户 的参与。
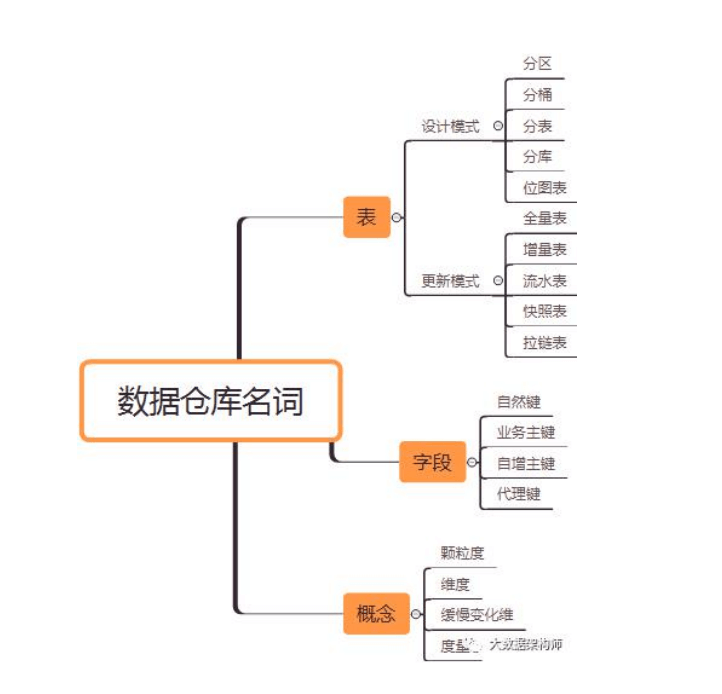
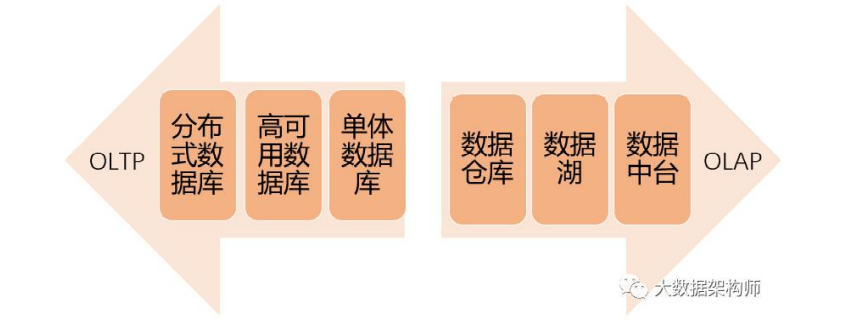
2、数据仓库
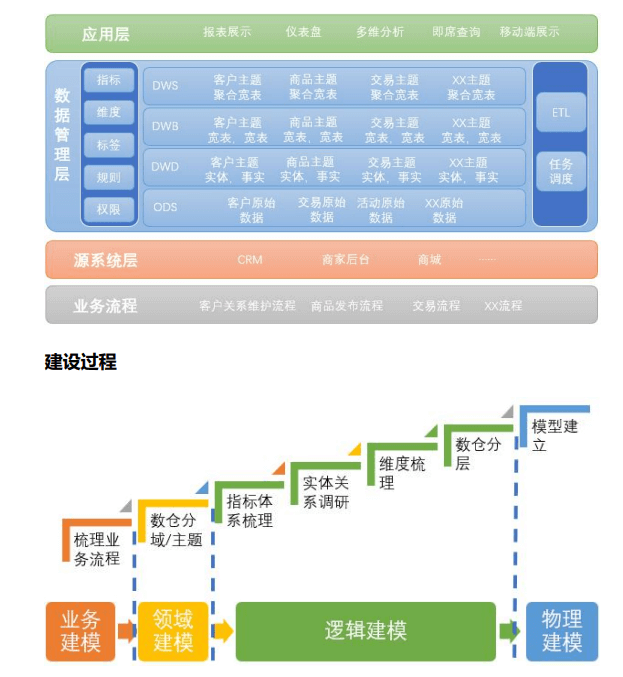

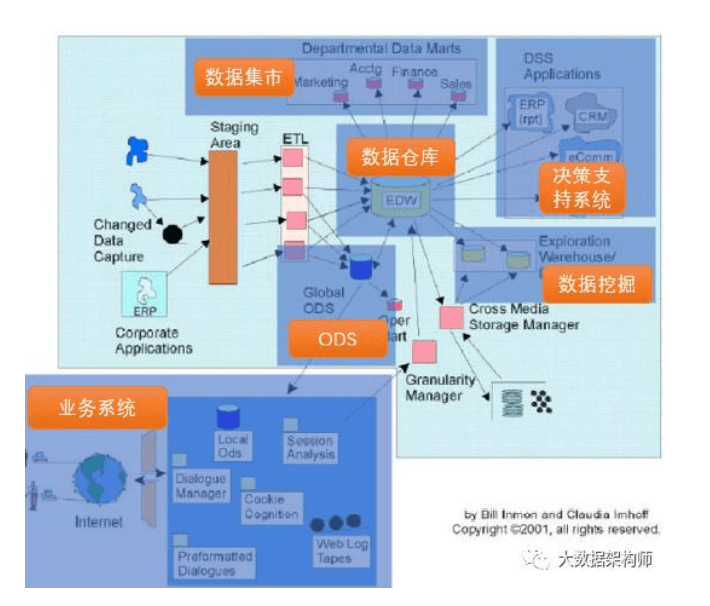
建模:从星型到雪花到星系到 CUBE,最后到宽表。
我们在实现数据仓库的时候,需要用到数据仓库设计(数据库设 计工具)、数据存储技术(数据库工具)、数据处理技术(ETL 工具、 监控报警)、数据管理技术(元数据、数据地图、血缘关系)等等技 术。 而 oracle、mysql、 Hadoop 等都只是数据存储技术中的一种 而已。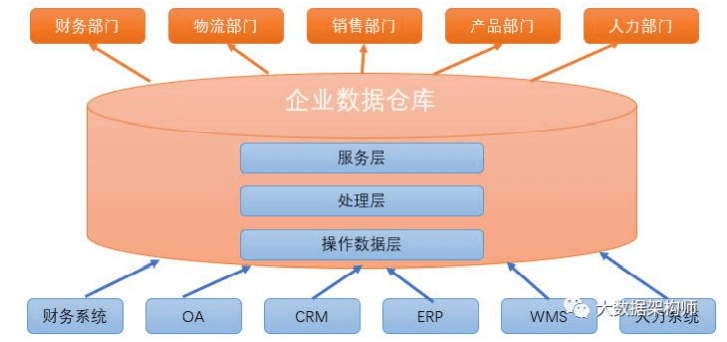
1)离线数仓(T+1,大数据批处理)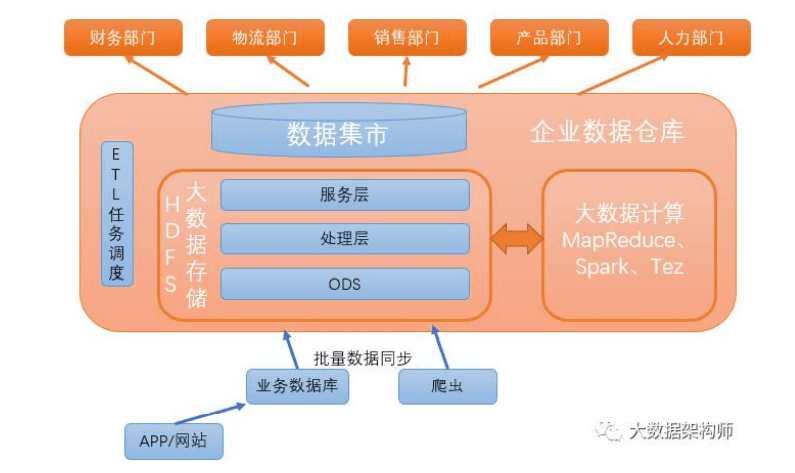
大数据环境中工具清单:
数据采集:flume/logstash+kafka,替代传统数仓的 FTP;
批量数据同步:Sqoop、Kettle,跟传统数仓一样用 Kettle,部 分商用 ETL 工具也开始支持大数据集群;
大数据存储: Hadoop HDFS/Hive、TiDB、GP 等 MPP,替 代传统数仓的 Oracle、MySQL、MS SQL、DB2 等; 大数据计算引擎:Map Reduce、Spark、Tez,替代传统数仓的 数据库执行引擎;
OLAP 引擎:Kylin/druid,(Molap,需预计算)、Presto/Impala, (Rolap,无需预计算),替代 BO、Brio、MSTR 等各种 BI 工具。
2)实时计算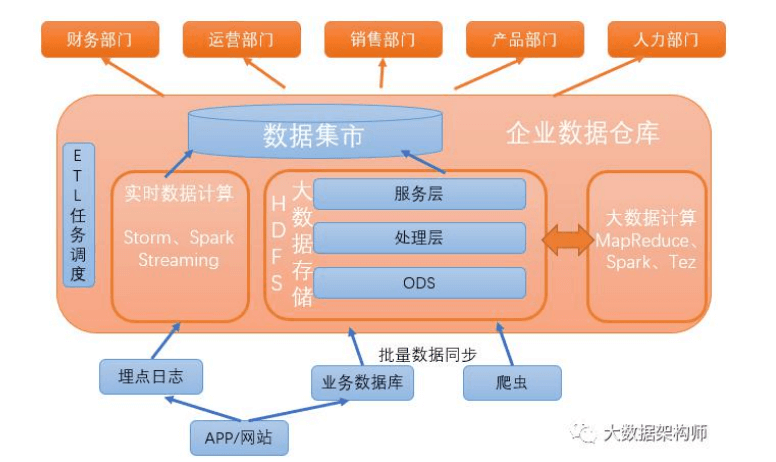
目前纯流式数据处理基本上就只有 Spark Streaming 了。 Storm 会丢数据, Flink 是批流一体的。
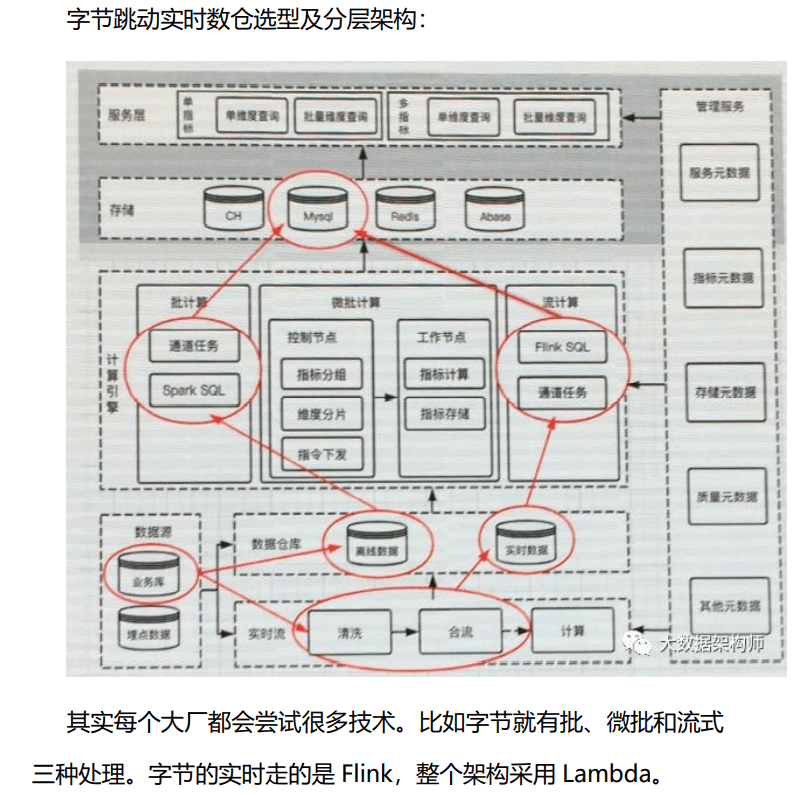
大数据环境下的数据仓库架构:1)Lambda 架构。Lambda 架构核心就三个:批数据处理层、流数据处理层和服务
层。2)Kappa 架构;3)Kappa 架构+查询+分析展示。

3、数据架构
单体架构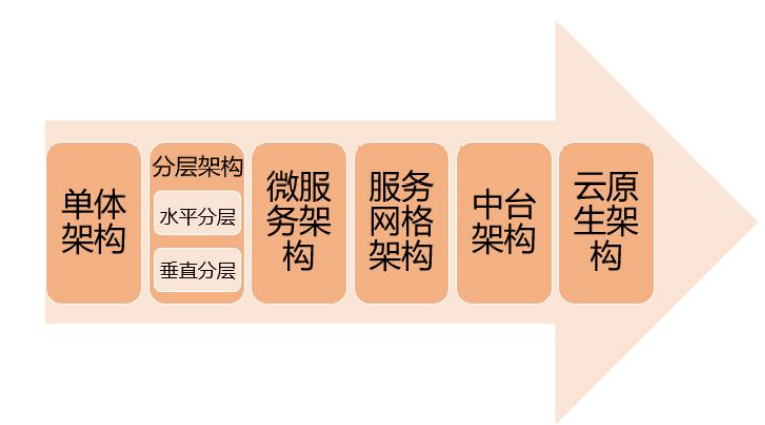
分层架构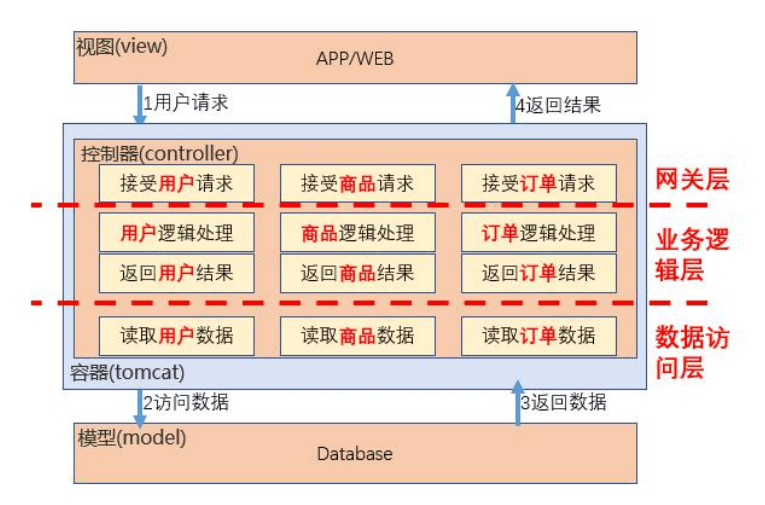
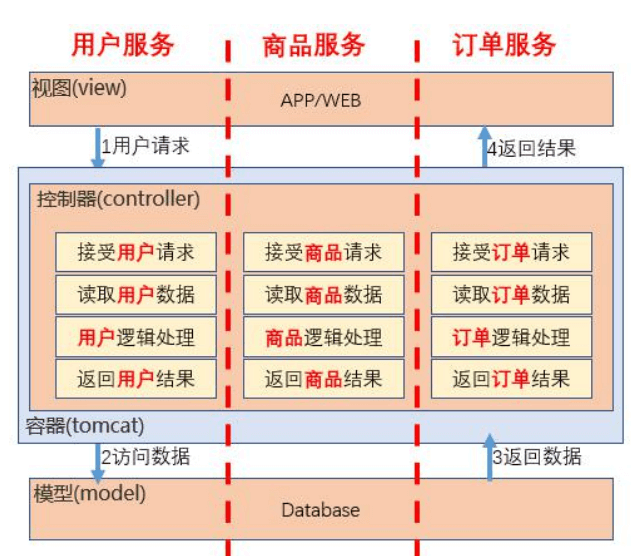
微服务架构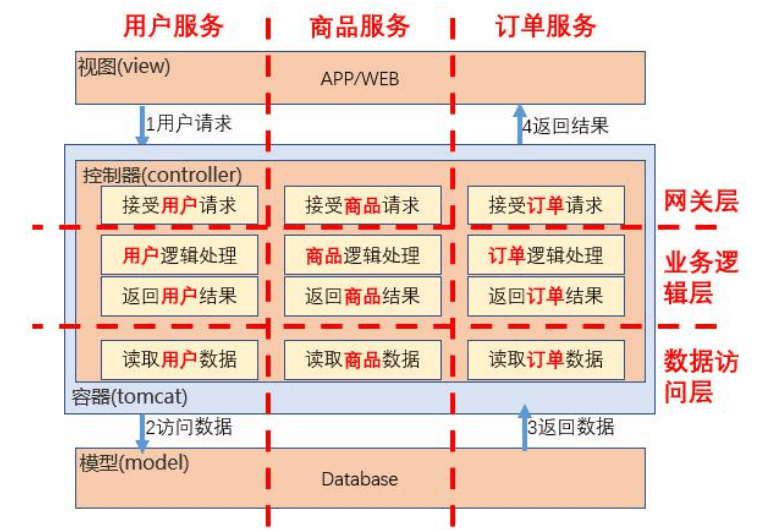
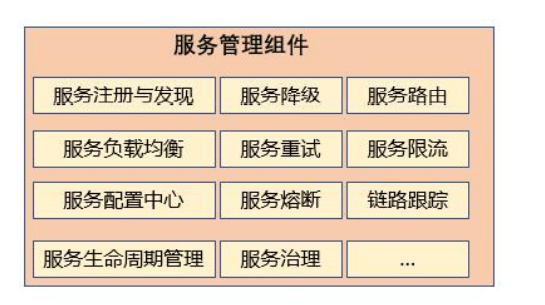
服务网格架构
中台架构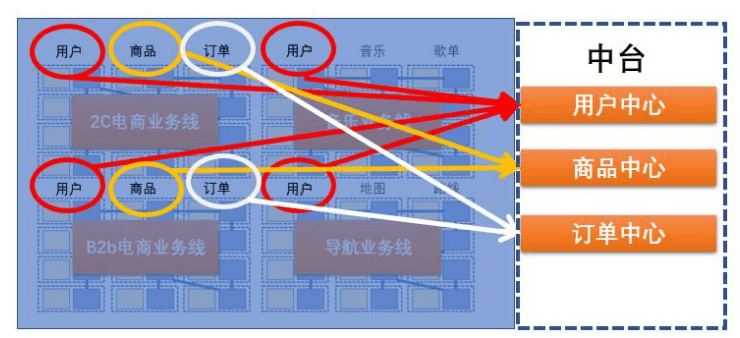

OneID 是最底层的数据打通,把各条业务线、各个业务系统的相 同实体(如客户)进行统一识别。用户端的感觉就是你用一个 id,可以通行阿里系所有 app。企业端的感觉就是无论用户用什么客户端,通过那个系统与企业发生关系,都能识别成为一个用户。
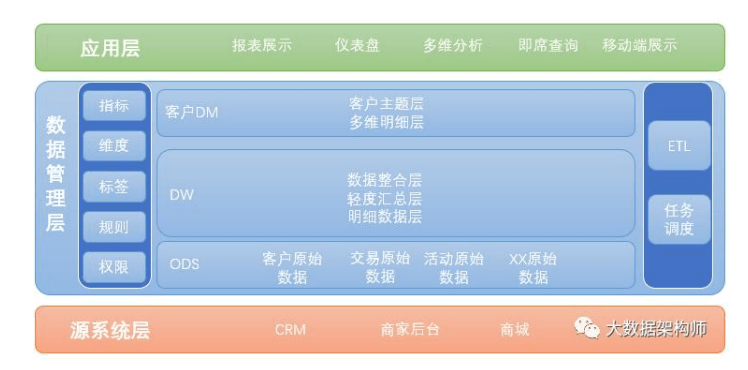
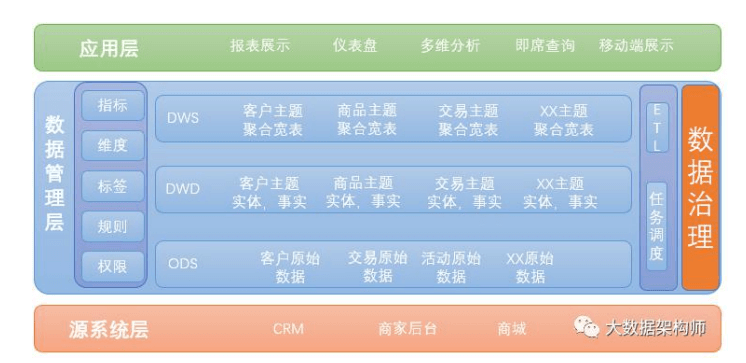
OneModel 是中间层数据的统一建模,这里其实就是数据仓库。只不过不是一个业务线的数据仓库,是整个企业,整个集团的,统一 的数据仓库。
OneService 是业务层的统一服务提供,其实还是那一套,主数据、即席查询、固定报表、多维分析等等。当然会多一些算法层面的试探,也仅仅是试探而已。
DMP(数据管理平台)
广告核心系统DSP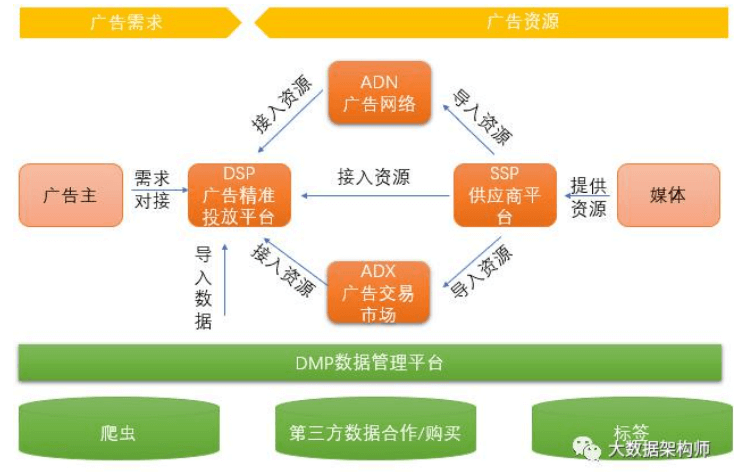

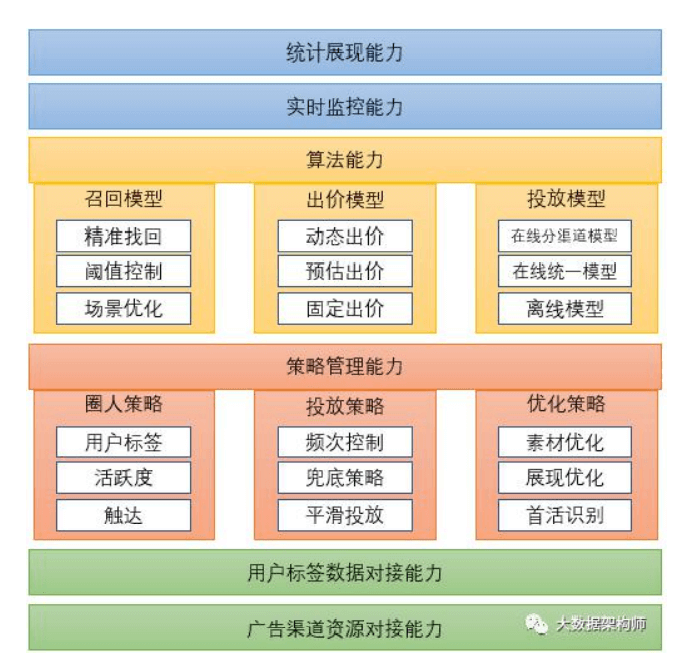
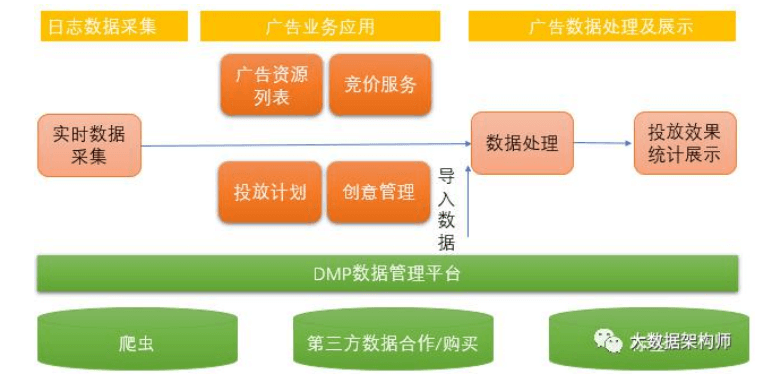
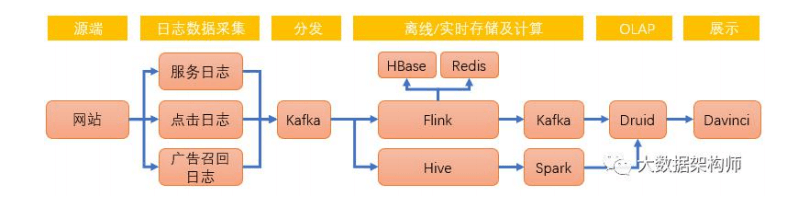
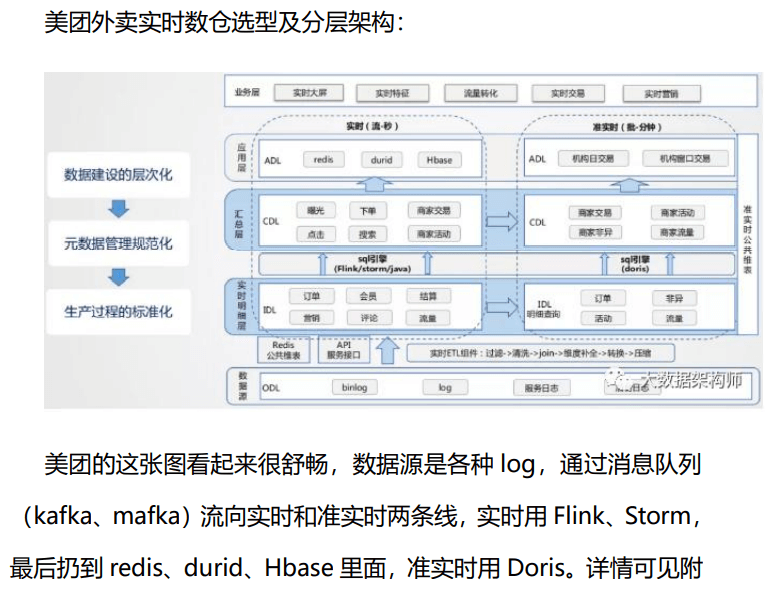
实时数仓: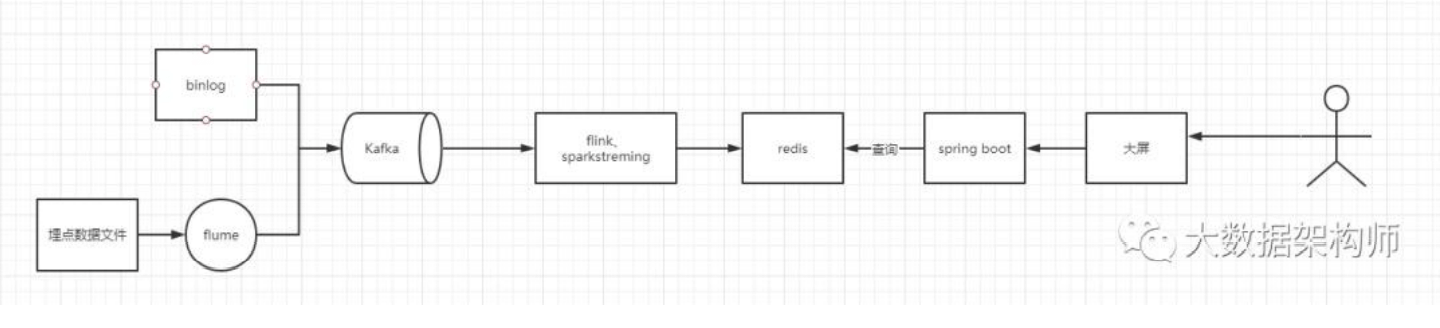
实时数仓1.0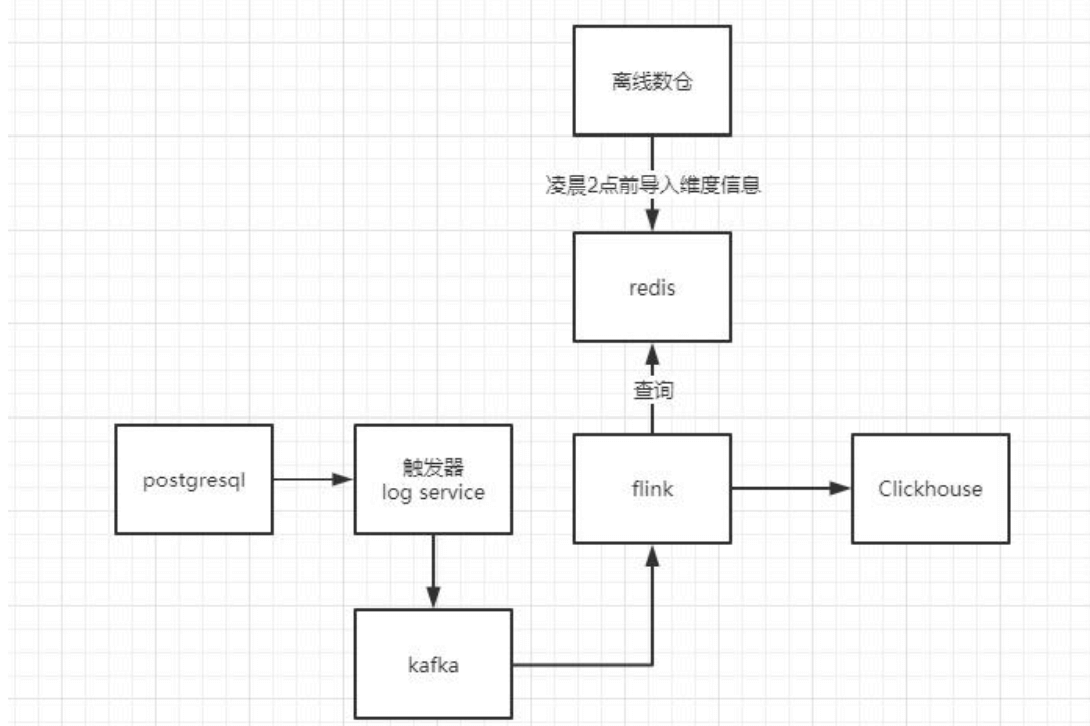
实时数仓2.0(增加join、增加实时数据监控)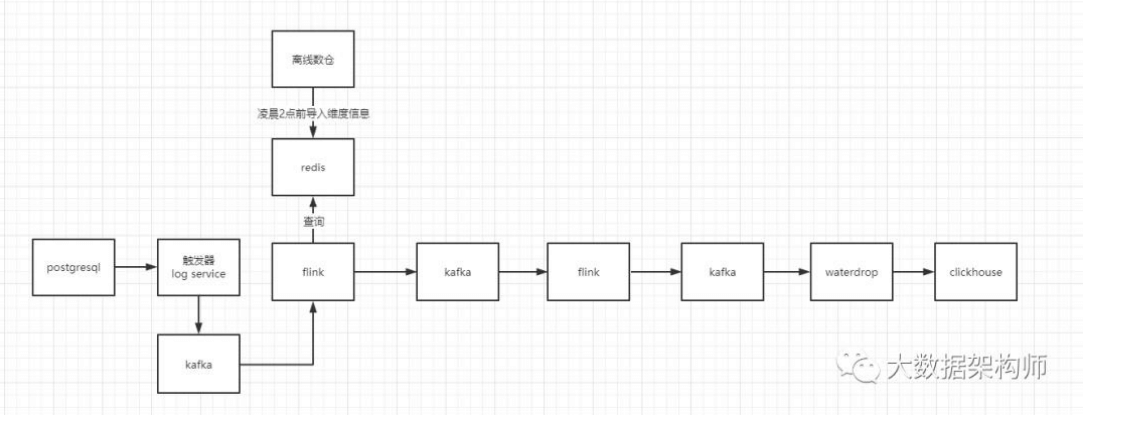
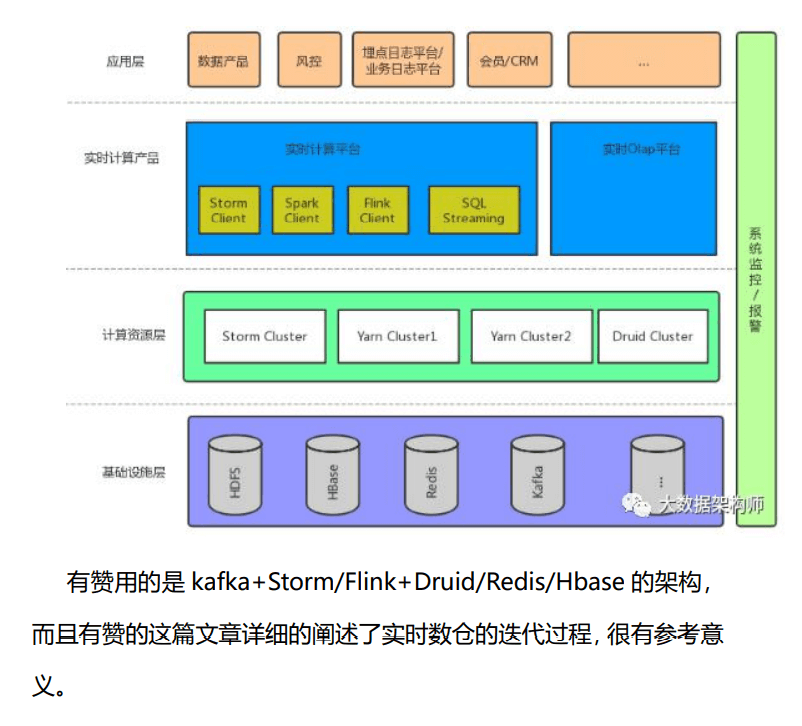
总结:在以上的架构中,我的核心思想就是,用 flink 拉宽、计算之后,交给 olap 引擎做多维分析,对数据和业务进行解耦。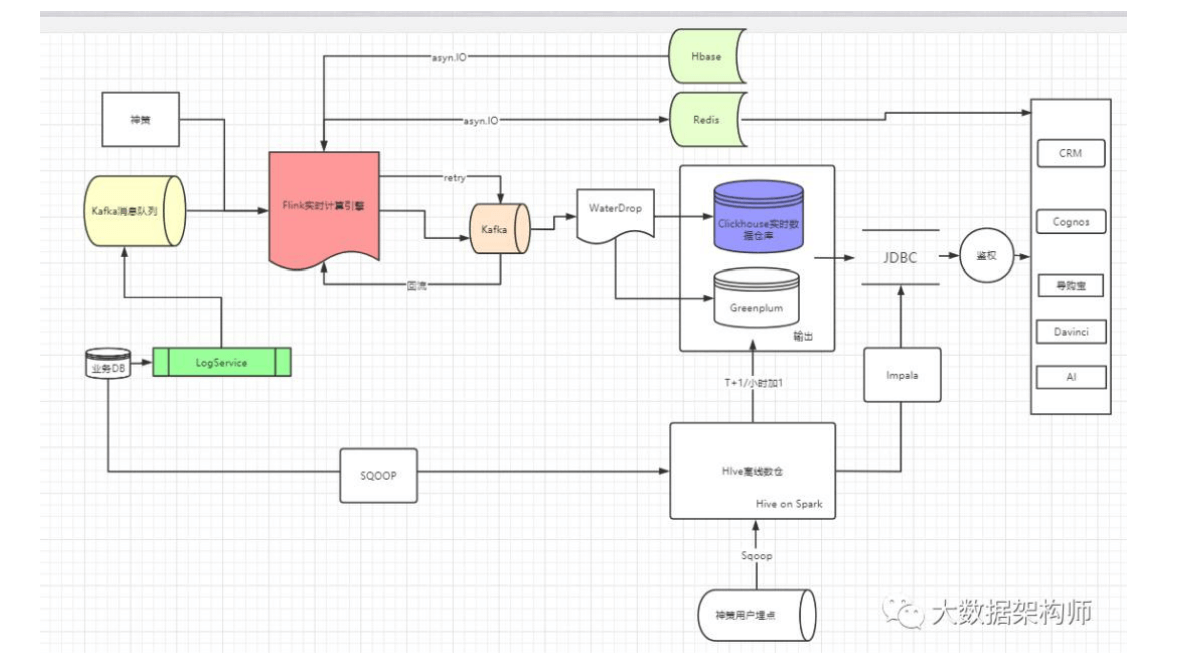
实时数据处理流程: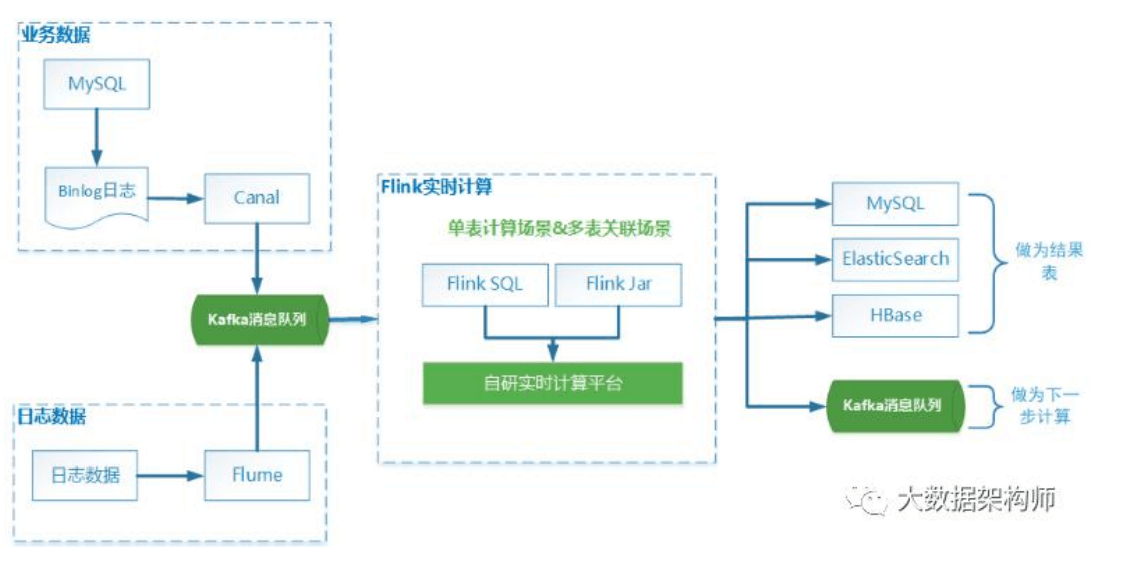
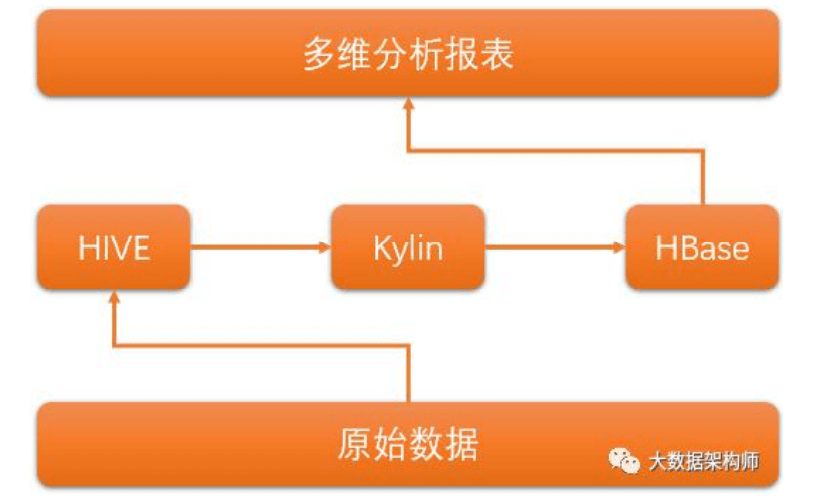
数据处理现在还是分为 OLTP 和 OLAP:
OLTP(在线事务处理)优化的方向是高并发、高可用,是精确, 是各种增删改查。所以面临和解决的问题都是怎么解决高并发下的增 删改查,怎么解决脏读、脏写,保证数据一致性等问题。
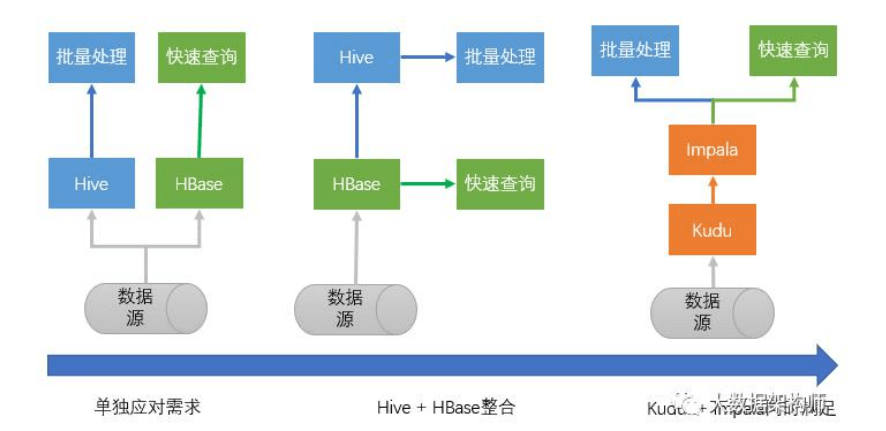
OLAP(在线分析处理)的优化方向则是高速数据处理能力、高 速读取能力。一般又分为两个优化方向,一个是预先计算好各个维度 的数据,存成 CUBE,分析的时候直接查询结果就行,这是 MOLAP (Multidimensional OLAP,多维在线分析处理),典型代表的是 Kylin。一个是结构化存好,然后用尽各种方法优化,分析的时候拼 命计算,这是 ROLAP(Relational OLAP,关系型在线分析处理), 典型代表就是 ClickHouse。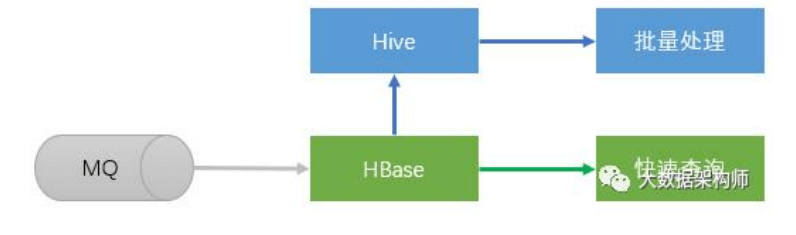
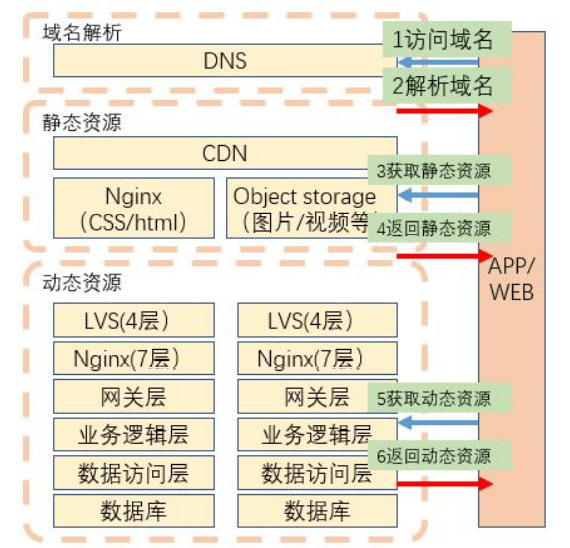
总体架构
逻辑架构
应用结构
技术架构
数据架构
部署架构(网络架构)
功能架构
运行架构
4、基础技术
1)SQL 优化,总共可以分为三层:数据库系统、数据库设计、程序 设计。我按照先易后难的顺序,又分为表设计优化、查询优化、索引 优化、架构优化、业务优化 5 方面。
2) 窗口函数又叫 OLAP(OnlineAnalytical Processing)函数,其 实就是用来画表格的函数。特别擅长处理各种分组排序、同比环比、 累计占比、TOP 等复杂分析操作 。
聚合函数、窗口函数、分析函数、排序函数。
窗口函数基本语法: 操作函数(窗口、聚合、排序等)+窗口函数基本内容【 over + partition 分区+排序+窗口内区域】
窗口函数基本内容: over (partition by 字段 order by 字段 asc rows between and )
窗口操作函数: 1.LEAD(字段,位移数,默认值) :向下位移 N 行取值 2.LAG(字段,位移数,默认值) :向上位移 N 行取值 3.FIRSTVALUE:当前分组第一个值 4.LAST_VALUE:当前分组最后一个值。
select 业务员,月份,商品金额, sum(商品金额) over (partition by 业务员 order by 月份 asc rows between unbounded preceding and current row) as 当年 累计业绩, max(商品金额) over (partition by 业务员 order by 月份 asc rows between unbounded preceding and current row) as 当年 最大单月业绩 from 原始业绩表 _
partition 就是对每个业务员的数据单独分组,然后进行内部计 算; order by 就是你计算的时候是按什么顺序进行计算的; rows between … and 就是在计算的时候,窗口的区域是从哪里 到哪里 unbounded preceding 就是当前分组第一行, current row 就是当前
聚合函数(多行变一行): sum、max、min、avg、count
排序函数(分析函数): 1.ROW_NUMBER:从 1 开始,按照顺序编号 2.RANK:生成排名,相同得分排名相同,并留空位。 3.DENSE_RANK:生成排名,相同得分排名相同,并不留空位。 4.CUME_DIST:小于等于当前值的行数/分组内总行数 5.PERCENT_RANK:分组内当前排名占总排名的百分比 6.NTILE:分桶,将分组内的数据均匀分N 。
5、设计思想
6、大数据技术
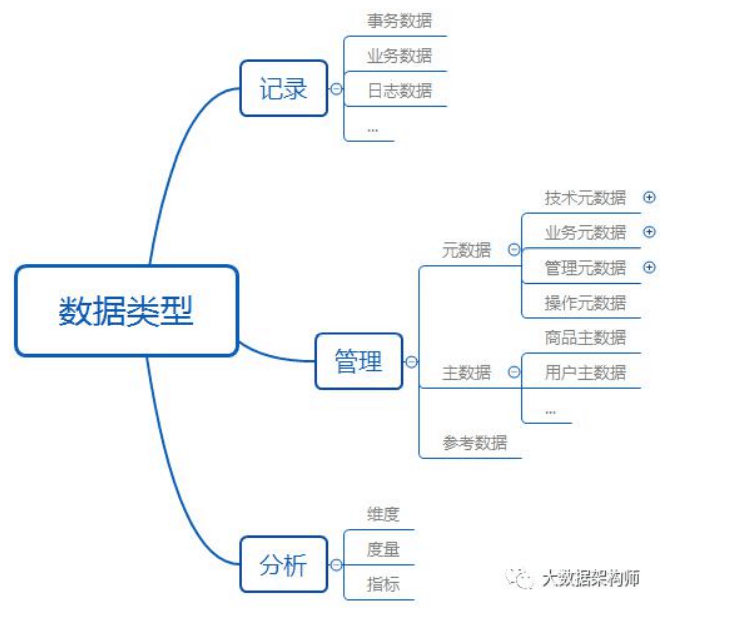
7、数据治理

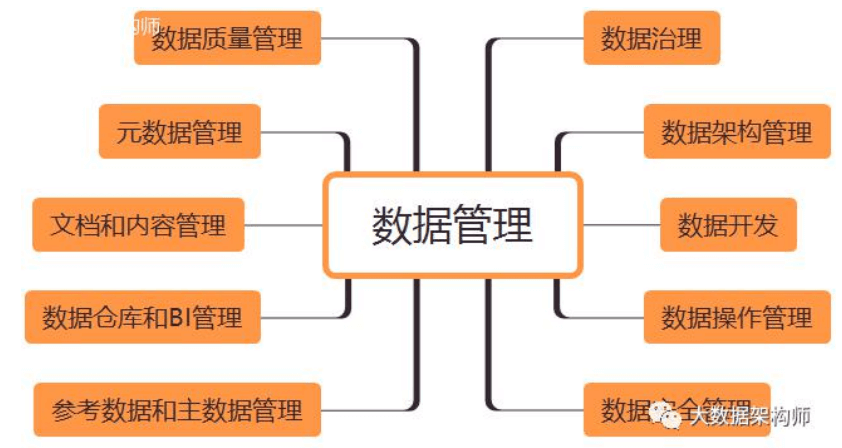
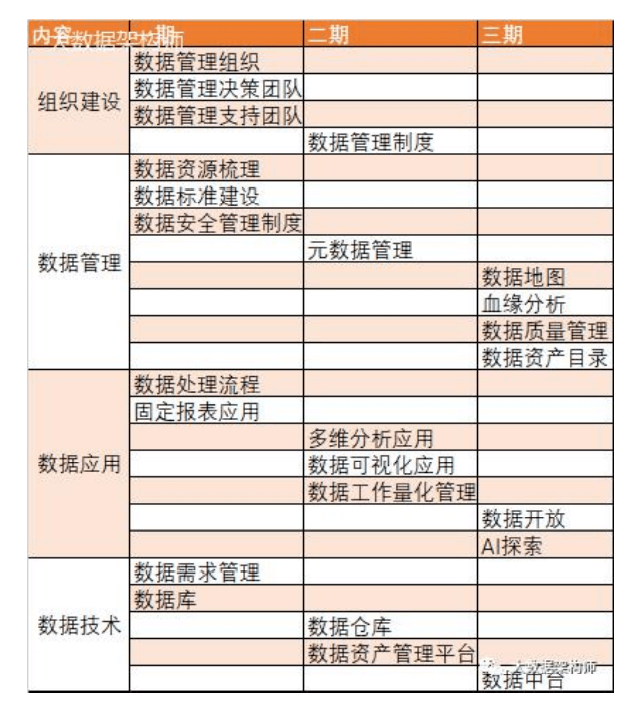
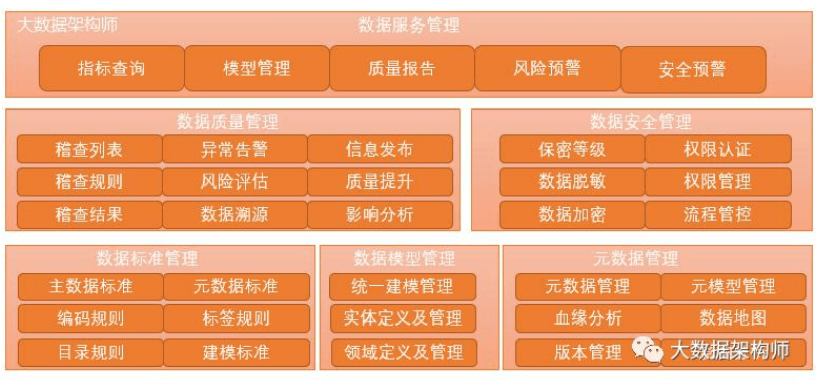
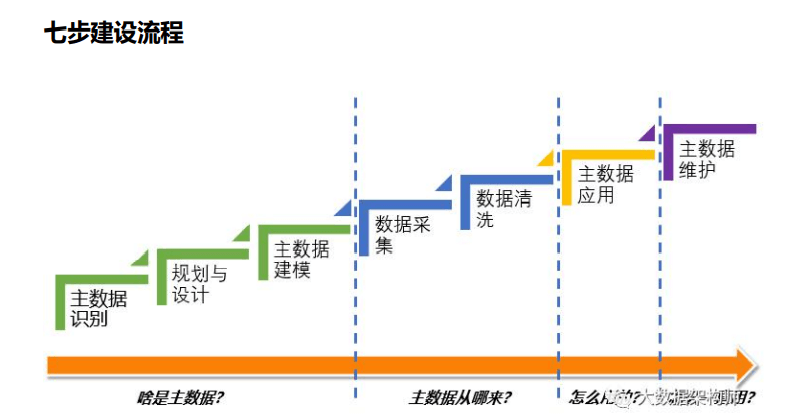
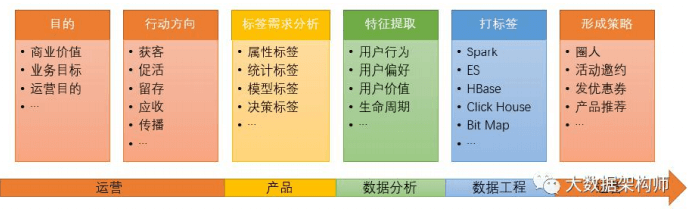
指标六要素:
指标名称,全局唯一的名称; 计量单位, 计算方法,即统计逻辑、口径; 时间限制,即统计时间点、统计频次等时间属性; 空间限制,即统计区域范围; 指标数值,就是具体的数值了 。
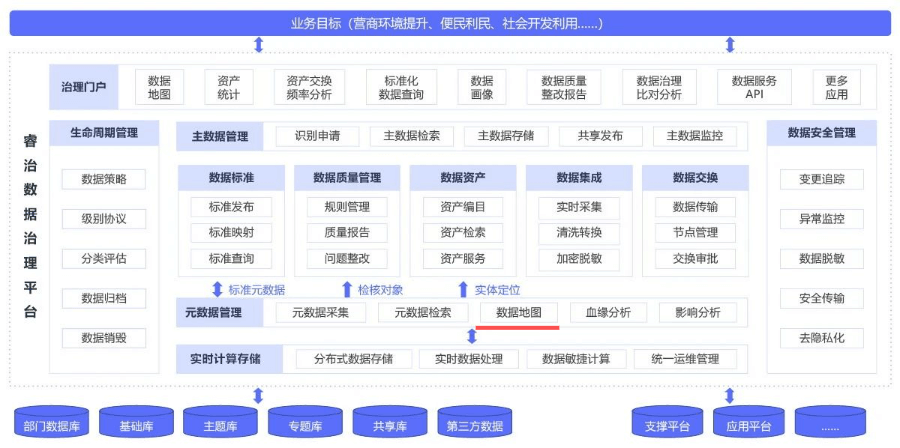
Atlas 数据图谱: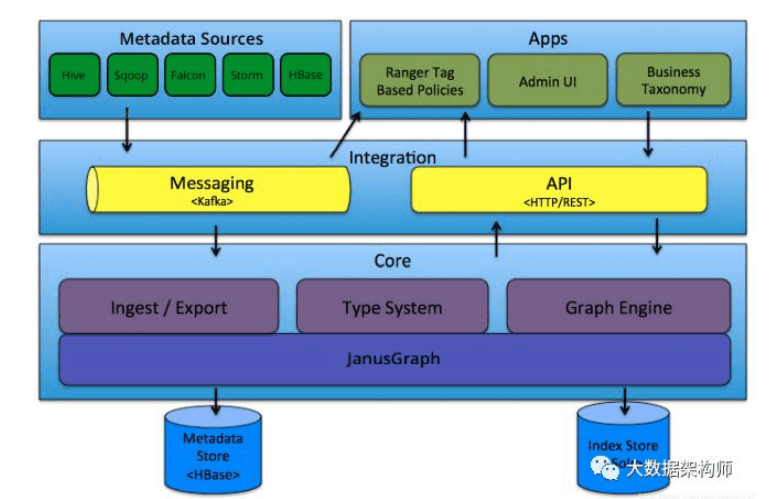
8、数据产品
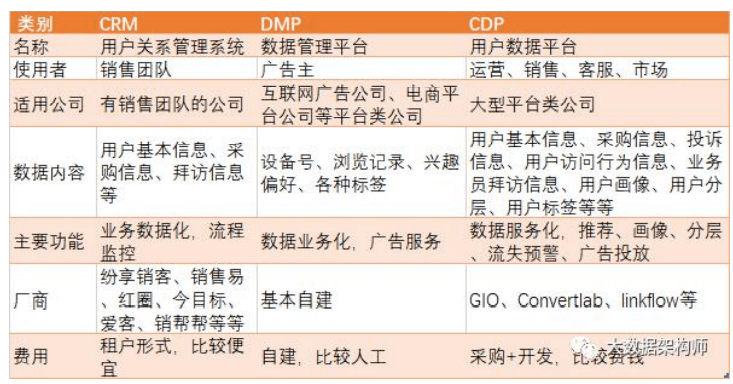
CRM 应该听的比较多,就是客户关系管理系统(Customer Relationship Management)。
DMP 就 比 较 少 的 人 听 说 了 , 是 数 据 管 理 系 统 ( Data Management Platform),对应的前台应用叫 DSP,广告精准投 放平台(Demand-Side Platform )。
CDP 最近倒 是挺火的 ,是客户 数据平台 (customer data platform) 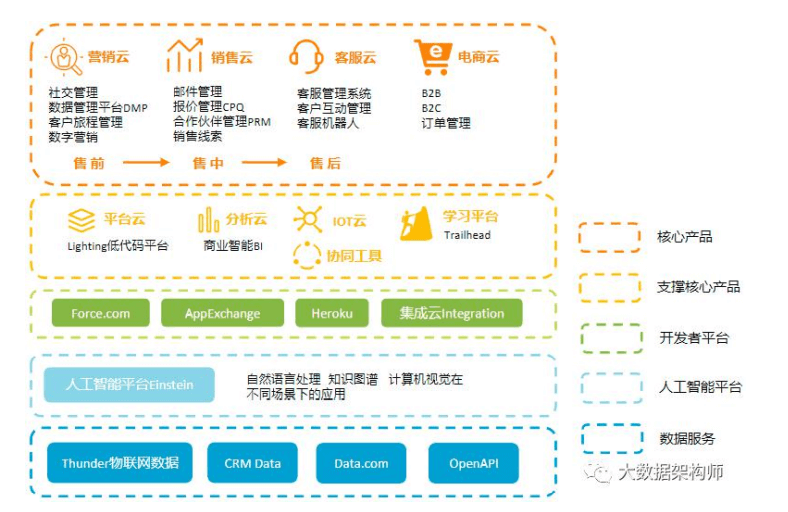
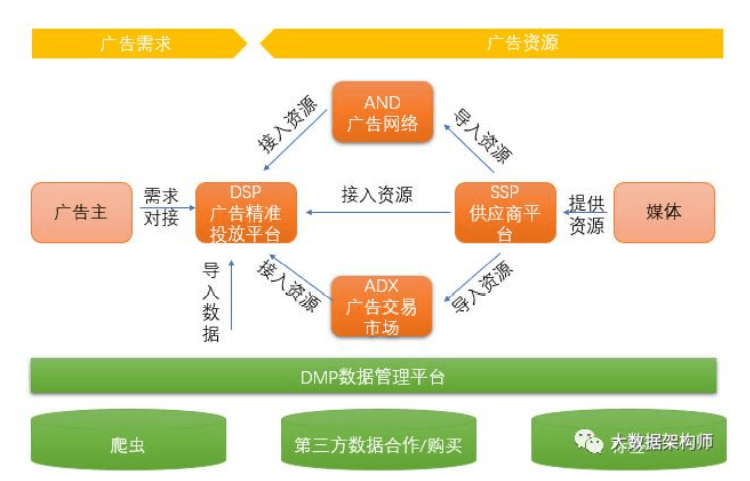
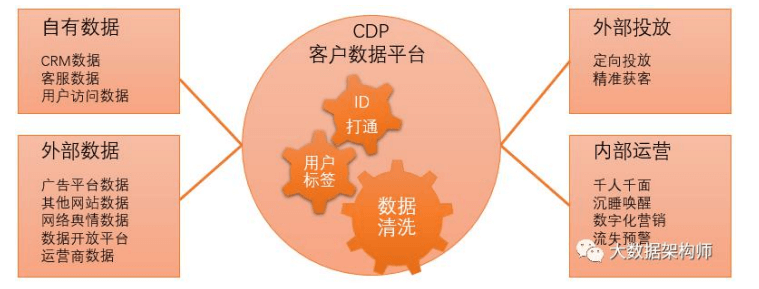
实时数仓架构设计: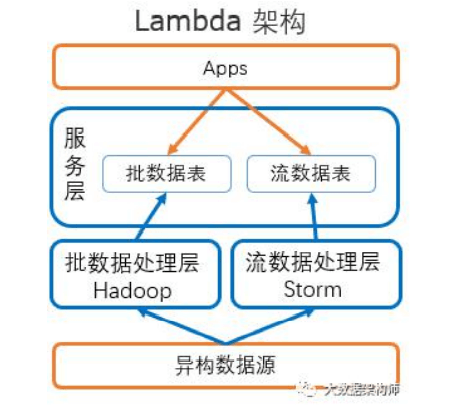
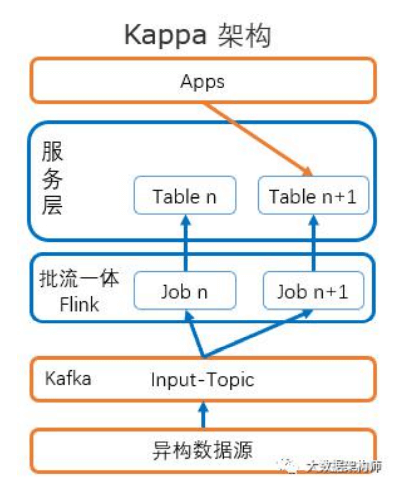
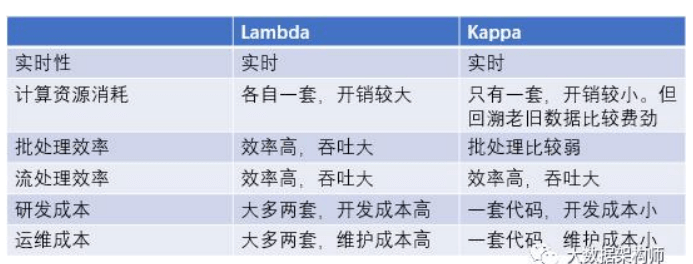
不管是 Lambda 还是 kappa 架构,实时计算都需要有数据源、 数据通道、实时计算引擎和存储引擎这几个部分 。
实时计算过程: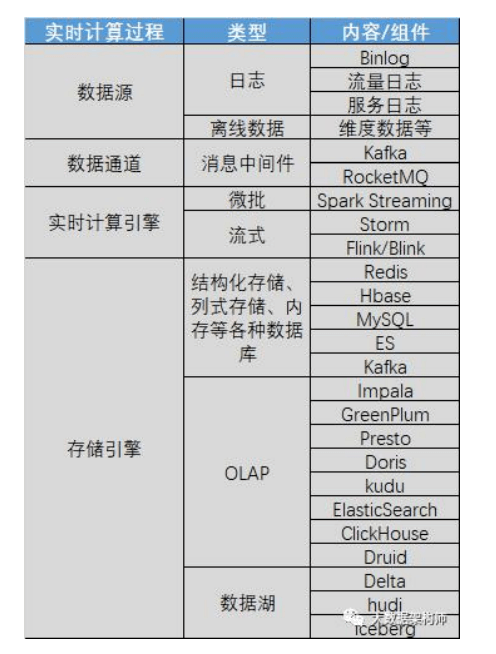
这里重点说一下存储。如果算完之后直接接大屏等应用,建议用 redis;如果要快速查询,建议接 Hbase、ES 等,如果还有后续操作, 建议扔 kafka 里,如果要结构化落地,建议 MySQL 里。 如果要接 OLAP,做多维分析,可以在 OLAP 里选,准实时多维 用 Impala、GP、Presto、Doris、kudu 等都行,大宽表就用 ES、 CK、Druid 。
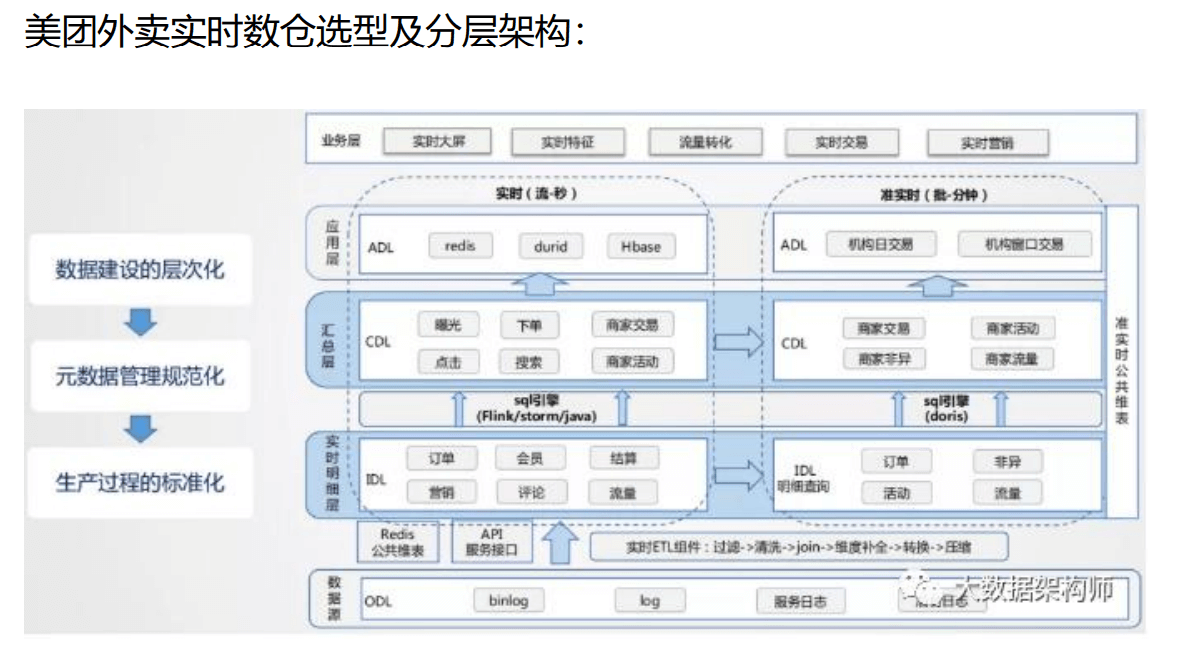
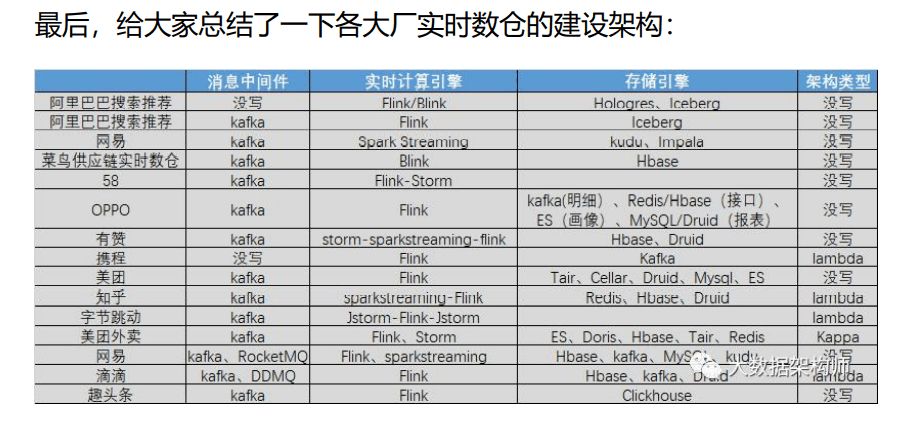
12、商业模式
贝壳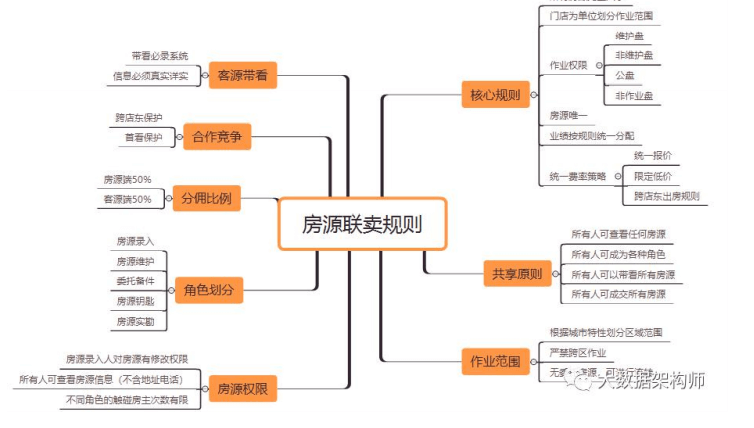
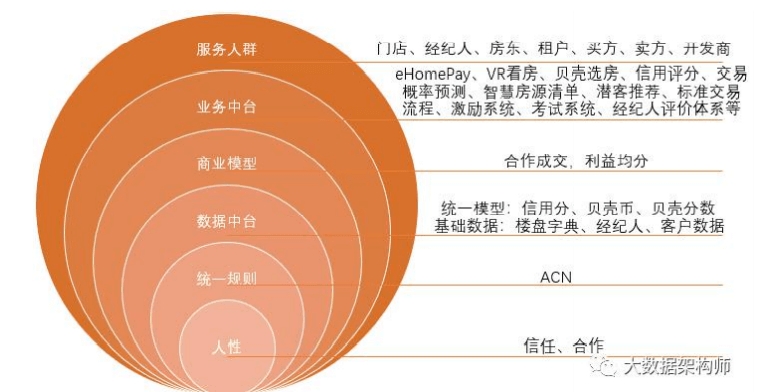
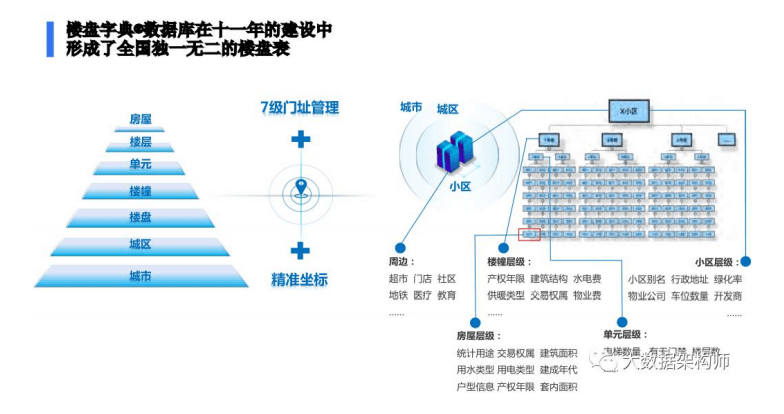
贝壳的赋能体系很完善,
规则层面上有: ACN 规则用来跨组织协作; 贝壳分用来评价经纪人能力和表现; 贝壳币用来经营贝壳生态,增强经纪人粘性;
系统层面上有: VR 看房 IM 即时沟通系统 楼盘字典 eHomePay 经纪人评价系统等等一大堆 ;
组织层面上有: 战区、省、市的组织层级 CAD、CA 的客户成就体系。

若有收获,就点个赞吧
0 人点赞
