原创 阿Bing有话说 Bing说 2019-08-19
2019年07月30日
初探,如有问题大家多沟通多交流
最后达到了kaggle比赛private score的top10%分数,还比较满意,过程与大家分享一下。
比赛官网:https://www.kaggle.com/c/rossmann-store-sales/data
—————————————-
预测 Rossmann 未来的销售额
I.问题的定义
项目概述
销售预测是个商业问题,然后我本人是做商业方向的数据分析,因此跟本行有一定的相关性,比较感兴趣,因此愿意深度去研究。销售预测目的是增加销售量,让企业获利且利润增加,但是目前来说商业环境非常复杂,影响的变量太多,且某种程度来说,销售预测不是一个难题,难题的事如何提高销售预测精准度。
问题陈述
销售预测是一个回归的问题,本次的主要目标是从已有的数据中提取出有效的特征(特征工程),然后选择出合适的模型进行预测。问题的难点就是上文所提如何提高精准度的问题,因此会选择多个模型进行测试,选择出最合适(时间和评估指标rmspe数值)。
大概的步骤是,先进行数据探索,对数据进行了解,对数据进行处理,比如对空值进行处理,数据类型进行转换,以及考虑销售量是个受到季节性,是否促销等等因素影响比较高的数据,因此也对于时间等数据再处理。之后,根据所选的评价指标从可用的模型中选取合适的模型。希望的结果就是在我提交kaggle我的预测集之后分数能够达到0.11左右,top10%。因为kaggle上Rossmann预测评价分数是rmspe,因此本地进行测试的时候也是用相同的标准,达到最低分数再提交。
评价指标
选择的评价指标有两个:一个是rmspe(RMSPE)-Root Mean Square Percentage Error ,也是该比赛方判断的指标。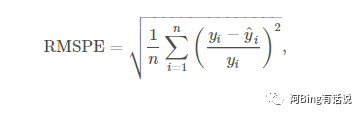
一个是运行时间
集合这两者后选择最合适的模型,然后不断进行调参。从而得到理想结果,解决精准度这个问题。
II. 分析
数据的探索
使用的数据主要是从官网中下载的,一共有三个csv是有用的,一个是训练集包括销售量,一个是测试集,不包括销售量,一个是附属关于商店的信息。特征工程方面主要是处理空值和数据类型的转换。
训练集大概的数据集如下,有9个feature,一共有100w数据,1115个商店从2013~2015年的数据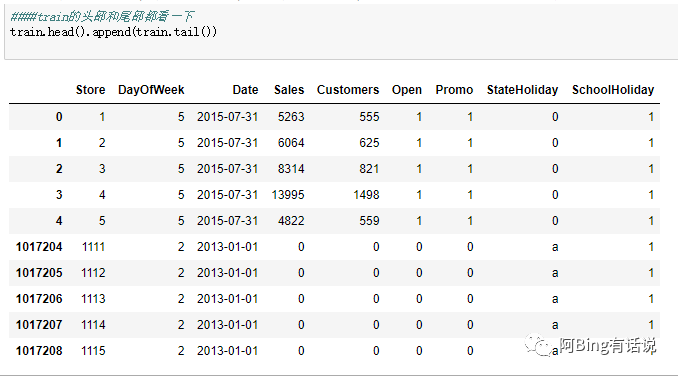
测试集,一共8个feature,4w的数据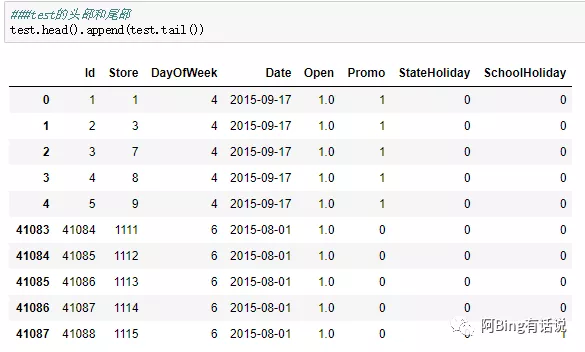
然后观察store数据集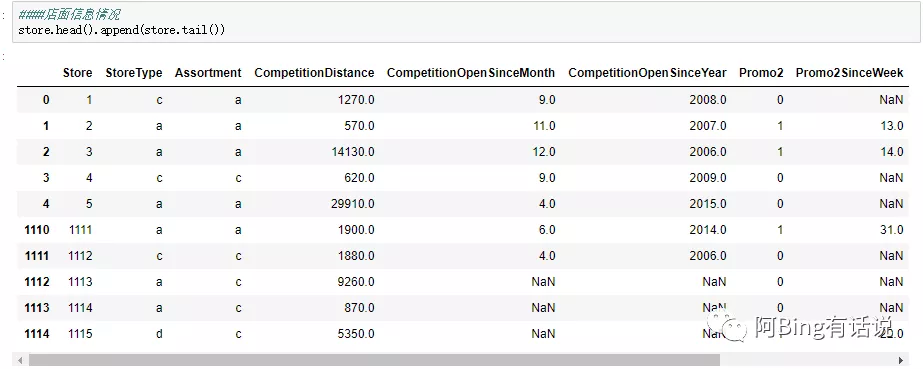
store的数据集比较复杂,存在大量的NaN,以及非数字字符串,尤其需要处理。 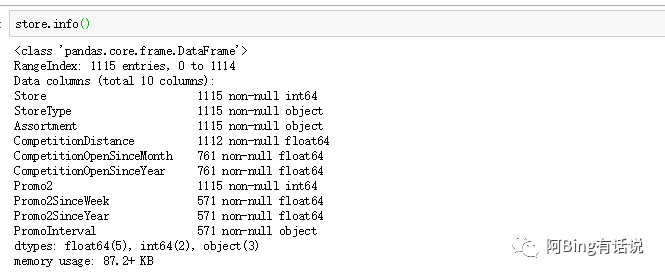
观察数据集的NAN值情况。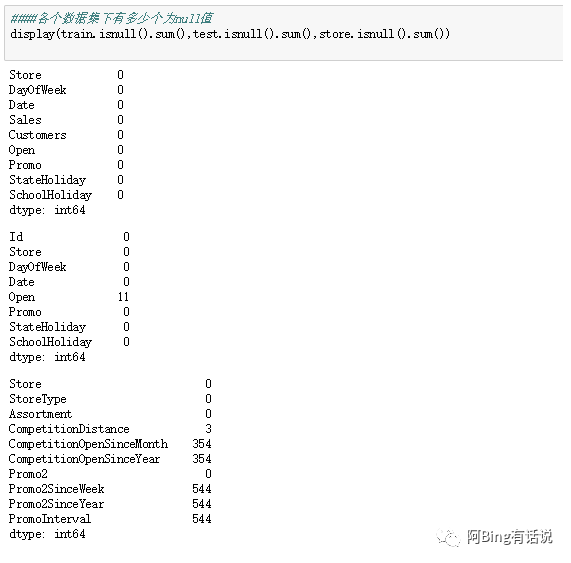
发现数据集主要集中在store的数据集,里面的competition相关以及promo相关feature。以及少部分测试集的open列里面。
观察测试集下面的null是什么用的情况,因此细化观察 。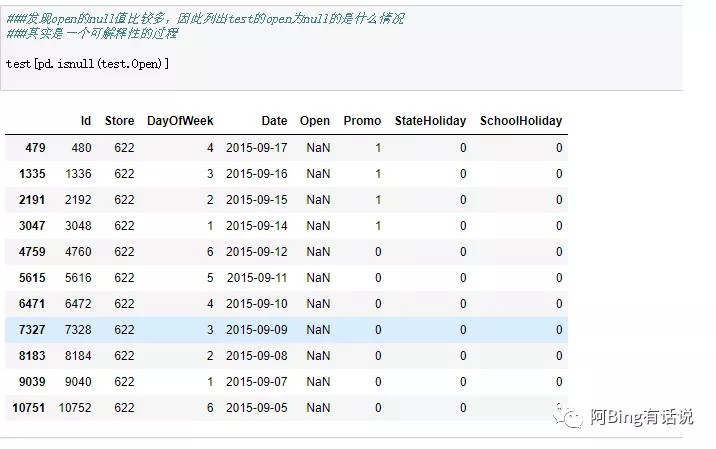
都有促销肯定也是开业,可能存在数据记载错误,而且从最后结果来看,最合适的是将open里面NAN替换成1的情况,效果最好。
然后观察Store的为空情况。 最后测试发现替换为0的时候效果最好。
其中从业务sense来说,销售量是个受到时间季节性影响比较大的数据,因此想要看时间与销售量的变化情况。结果发现DATE这个feature是个string,需要格式在转换成时间戳来观察。
探索性可视化
最后观察其数据的波动情况。store 1的数据量变化 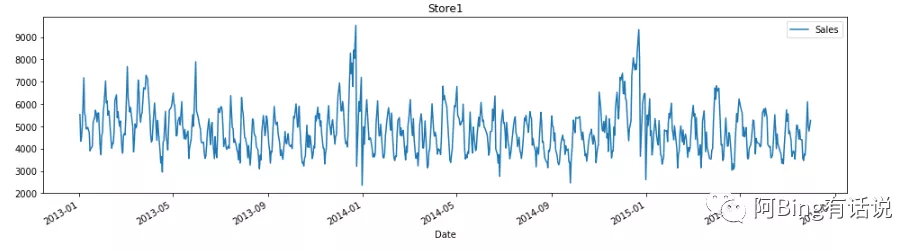
因为数据噪音太多,去掉月维度的噪音来观察。
且讲原始数据与去掉噪音的数据进行对比观察 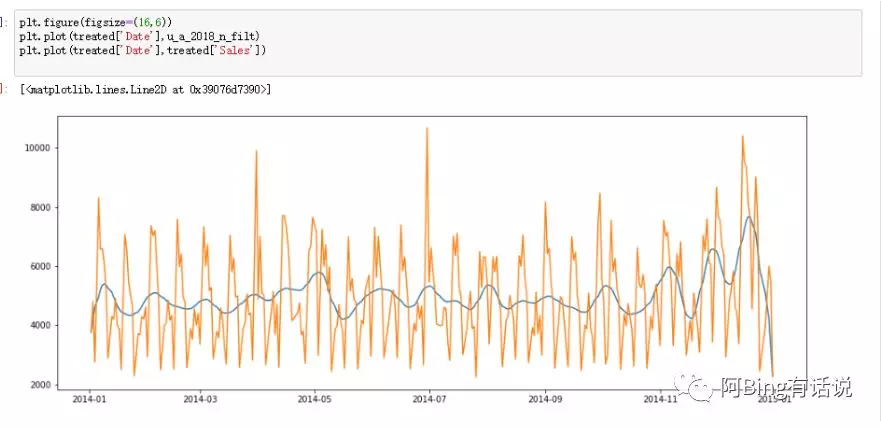
发现确实是一个季节性很明显的数据,旺季的数据集中在12月份左右。因此要对时间Date这个feature进行处理。
对数据进行处理以后发现,确实是时间的数据与销售有一定的相关性,以及还有promo相关的指标。相关性热力图如下文。
然后观察各个指标之间的相关性。 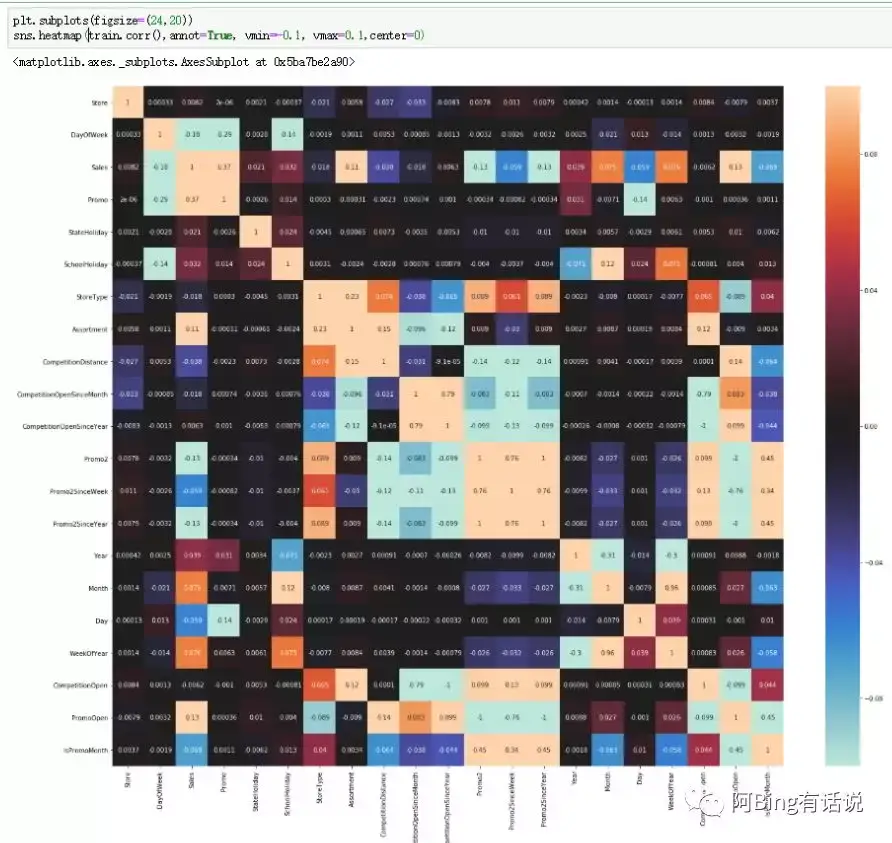
算法和技术
在做该项目的时候选择了7个预测模型,一般预测时候会使用的模型,进行轮番测试,选择分数最高速度较快的模型,评价标准是以本地计算的rmspe为基准,达到了0.11左右即可提交kaggle。
时间序列:
pros:简单,适合趋势预测
cons:精准度不够
因此解决不了本次项目问题,提高精准度。
线性回归:
是常用的回归模型,但是通过观察本次销售量不随时间线性变化
pros:可解释性强,简单好用
Cons:只适用于线性规律的数据
决策树(regressor):
pros:适合拟合非线性规律,简单不需要对特征进行太多处理
cons:容易拟合,且从分数来说,rmspe分数太高
随机森林(RandomForestRegressor):
pros:快且精准度高
cons:当地rmspe难以达到项目预期0.11
xgboost:
pros:分数高,kaggle比赛大法器
cons:可解释性弱,且unstable不稳定,环境容易崩,下载容易出问题。
GradientBoostingRegressor:
pros:它的非线性变化比较多,不需要太复杂的特征工程
cons:计算复杂度高,且本地分数rmspe高
lightgbm:
pros:计算快,内存消耗少,更高的精准度
cons:可使用文献较少,使用者也较少
因为本次使用的是lightgbm因此介绍其模型重要参数:1.boosting_type 选择的是gbdt;
2.objective 选择的regression
3.valid-sets 验证机选用
4.learning_rate 梯度下降的步长
5.num_leaves:一颗树上的叶子数
6.metric:选择的rmse作为度量函数
基准模型
经过运行时间,rms和r^2进行筛选选出了随机森林该模型,以此为基准模型,然后与lightgbm进行效果对比。一般来说预测的模型会选择回归模型,首先想到的是xgboost,是GradientBoostingRegressor,LinearRegression,DecisionTreeRegressor,RandomForestRegressor,lightgbm和H20.
对数据进行进一步的处理:首先是对时间方面的数据进行处理。
然后对store里面的字符串进行映射。再对之前热力图可见的促销相关数据进行处理,同时因为PromoInterval里面是多个月份
因此在进行对其月份是都进行促销进行处理。判断该月份是否有促销。生成IsPromoMonth特征 。
同时有些模型要求是数据类型,因此对数据进行转换。
去除掉无用的特征 
将其放入模型之中。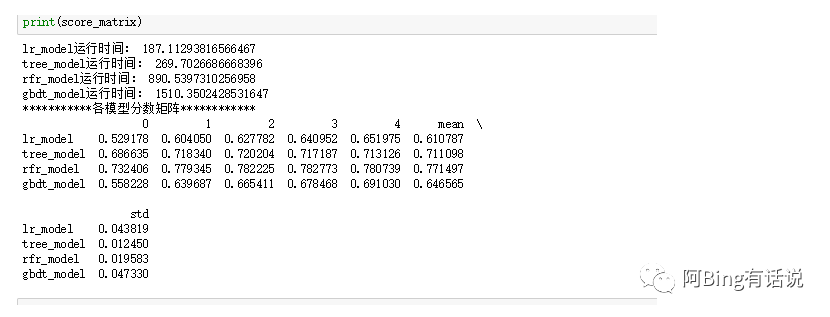
广为大众所知的之一是H20但是下载后jupyter notebook一直都找不到h20的包,最后选择可用的几个尝试GradientBoostingRegressor,LinearRegression,DecisionTreeRegressor,RandomForestRegressor,lightgbm。最后用mse和R^2来评估效果,且计算每个模型训练时间,综合来看最后剩下比较合适的是LinearRegression和lightgbm。
可以看出决策树和随机森林的std较低,然后两者进行对比观察。发现rfr的mse较决策树要低,因此选择rfr。
但是最后调参之后发现rfr的score最低是0.14, 最后选择合适的是lgb,调参许久,本地验证集的rmspe数值0.10之后,训练集是0.13,两个数集表现都较好,因此就提交,kaggle最后score是0.117。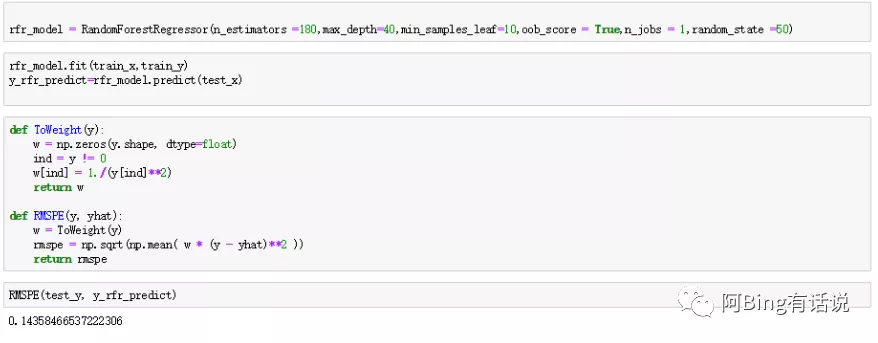
III. 方法
数据预处理
因为时间因素关系较大,所以首先是对时间方面的数据进行处理。
然后对store里面的字符串进行映射。再对之前热力图可见的促销相关数据进行处理,同时因为PromoInterval里面是多个月份!,因此在进行对其月份是都进行促销进行处理。同时有些模型要求是数据类型,因此对数据进行转换。为了让测试集的特征值数量与训练集对上,去除掉无用的特征。
执行过程
首选是大家都是用的xgboost,后来在编译的时候遇到了一些困难,然后读取DMatrix的时候找不到包,然后卸载重新安装之后,使用一次之后环境忽然崩了,于是在反复尝试以后,选择最后测试剩下的6个模型。
广为大众所知的之一是H20但是下载后jupyter notebook一直都找不到h20的包,最后选择可用的几个尝试GradientBoostingRegressor,LinearRegression,DecisionTreeRegressor,RandomForestRegressor,lightgbm。最后用mse和R^2来评估效果,且计算每个模型训练时间,综合来看最后剩下比较合适的是rfr和lgb。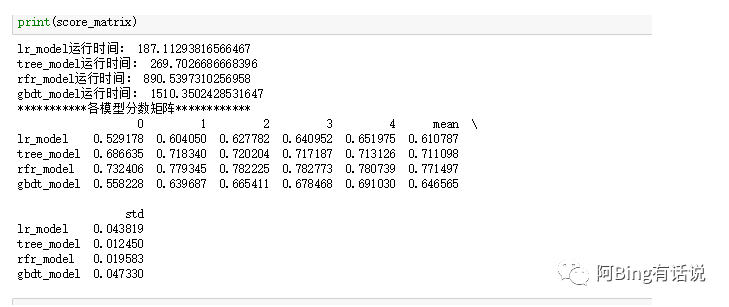
可以看出tree和rfr的std较低,然后两者进行对比观察。发现rfr的mse较决策树要低,因此选择rfr。
但是最后调参之后发现rfe的score最低是0.14, 最后选择合适的是lgb,调参许久,后来又加入了宏观参数,加权重这一块,本地验证得到的是0.1之后就提交,kaggle最后score是0.11。
完善
最后选择训练集的参数如下,且观察各个特征之间的相关性 。 
首先选择使用rfr模型,使用了GridSearchCV方法寻找合适的参数。
但是最后的分数最高为0.14,不符合预期,因此更换了模型lightgbm。
lightgbm这个模型也使用了GridSearchCV但是效果不佳,一般都调节rmspe到了0.3,选择的参数是,部分借鉴了知乎江老师的文献,然后在此基础上调低了学习率learning_rate到了0.01.
选择lgb的时候调节了lgb_train,num_boost_round,最高调到了20000,最后发现在15000左右rmse就稳定不在变动了,因此最后限定在15000左右。选择拆分样本,发现拆分样本test_size=0.3的时候最合适,后来经过reviewer老师的建议要要根据时间的排序来划分样本量,不然容易导致过拟合,private的分数远远低于public的分数。
然后根据最后的特征重要性表来观察,发现与竞品的距离是很有用的特征,但是经过我归一化处理之后,发现对分数并没有什么帮助,因此把它排除在外。后来尝试使用网格gridsearchcv选择合适的参数,发现这个是我电脑完全负担不起的,cpu太弱速度太慢,果断选择抛弃,也没有选择模型融合,因为调参也需要不少的时间,因此增加了一个宏观因素给予权重,通过观察发现,我的预测值要比我的现实值要稍微高一点点,因此后期对这个宏观给予权重,最后达到了比较理想的分数,且public和private没有太大的差别,因此选择该次模型结构预测的结果提交。
整个过程中提交的kagglescore的分数变化如下: 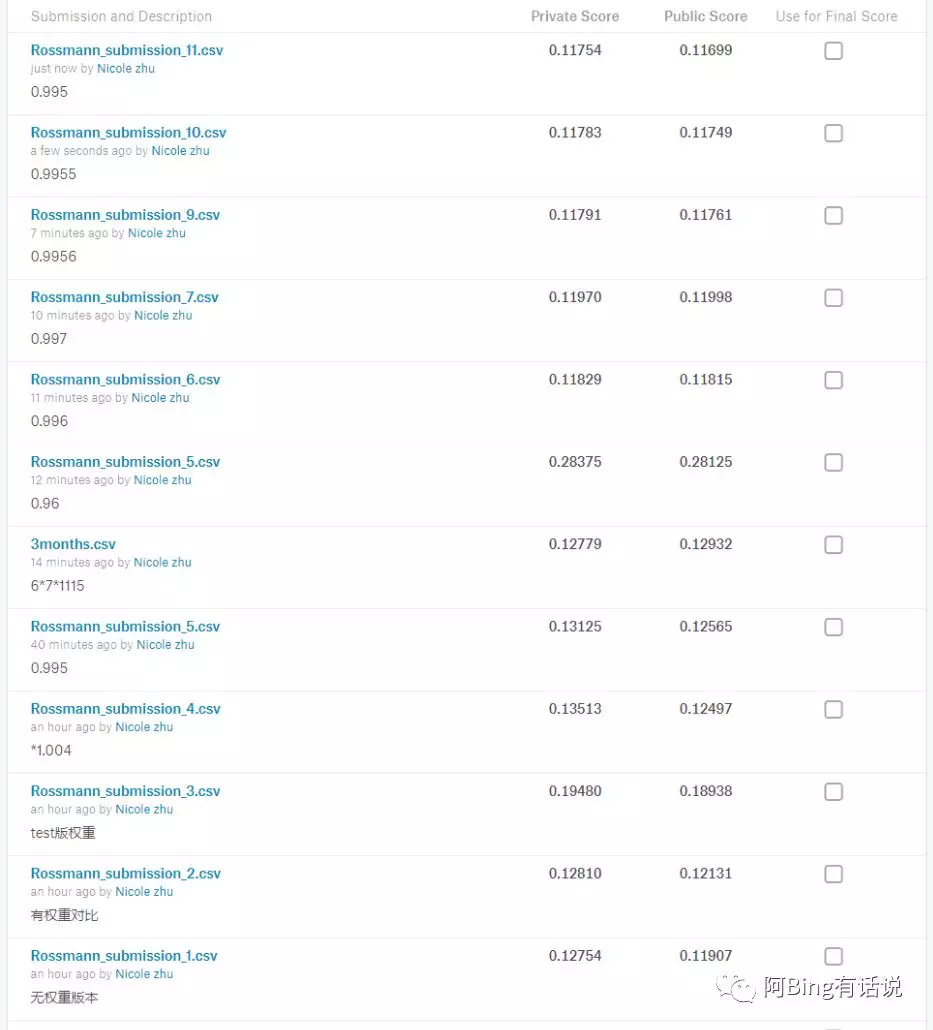
IV. 结果
模型的评价与验证
最后的结果跟预期一致,比较满意。选择出了合适的模型和合适的参数,最后的结果总体分数score为0.11的话,表明整体预测结果是稳健可靠的,如果不稳健可靠的话,比如前面预测好后面预测不好,总体分数还是会提高上去。
合理性分析
该模型最后的效果比我的基准模型表现更好, 且本地的分数虽然并不是很高,但是提交上去之后private 和public都是比较接近且0.11的情况,表明模型并没有过拟合,比较稳健。
项目结论
到了销售量预测精准度这个要求。 最后达到了预测值leaderboard private 的top 10%,小于0.11773
结果可视化
从数据探索到结果的评估上,都是有可视化。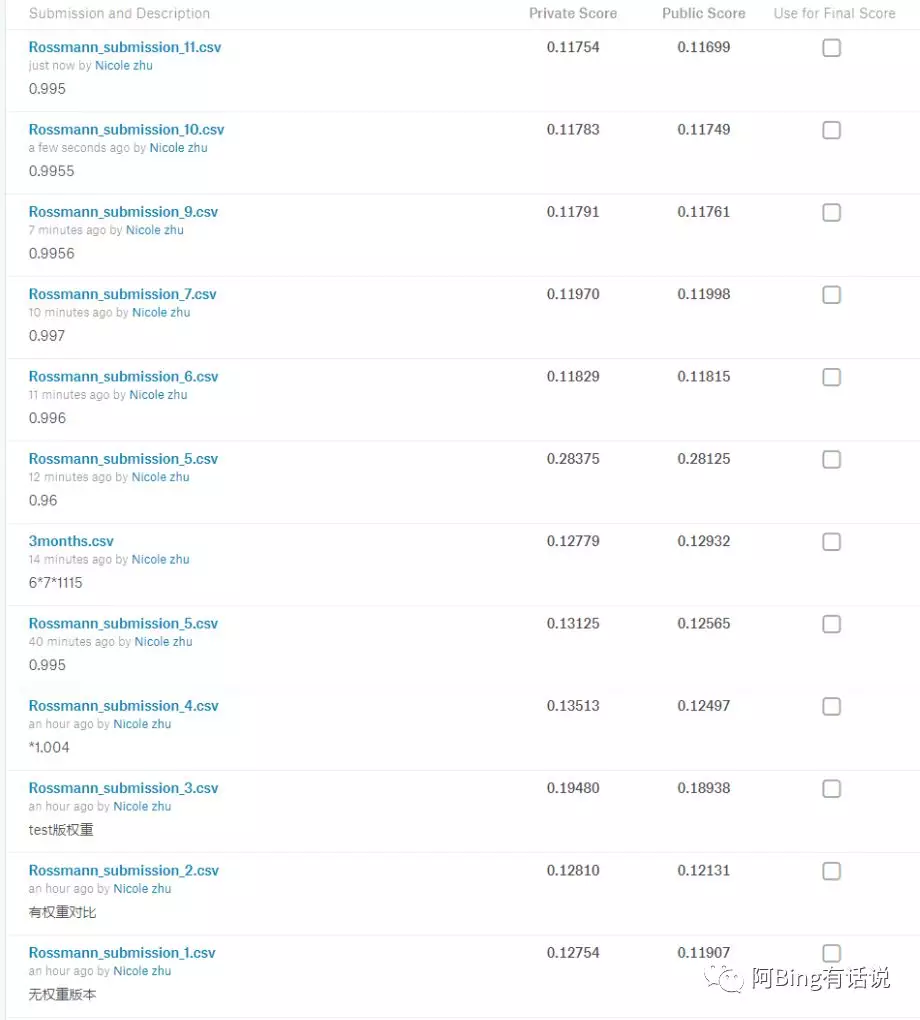
最后发现store商店本身和竞争对手相关的特征具有很强的重要性。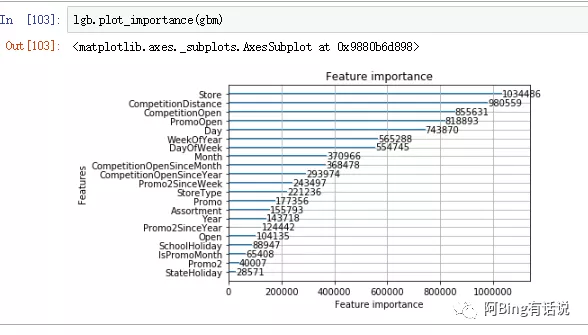
对项目的思考&改进
如果还有时间的话,我希望用xgboost和h20试试,从而了解更多的模型。本项目来说其实特征工程和模型选择并不是很难,对于我来说比较难的是还是包的下载和相关编译,比如xgboost就在编译的时候遇到了一些困难,然后读取DMatrix的时候找不到包,然后卸载重新安装之后,使用一次之后环境忽然崩了,于是在反复尝试,零零碎碎花了一周的时间。根据特征重要性表可以看出store商店本身的特征很重要,因此以后如果要继续提高预测的精准度可以增加商店本身或者本地信息。
此次增加了对竞品距离的特征处理,发现并没有什么用,发现特征工程真是一个玄学。本次并没有时间尝试模型融合,因为机子太渣且没有什么时间,以后有时间和好的设备的话,可以考虑采取。
Reference:
选择使用H20相关:https://www.kaggle.com/mlandry/random-forest-example
期间思路来源部分来自:了解随机森林 :https://zhuanlan.zhihu.com/p/51546044
了解lightgbm:https://zhuanlan.zhihu.com/p/67731440?utm_source=wechat_session&utm_medium=social&utm_oi=611637534023880704
了解xgboost:https://blog.csdn.net/aicanghai_smile/article/details/80987666
对销售预测有个全面的了解:https://www.infoq.cn/article/a-study-on-sales-forecasting-based-on-machine-learning

若有收获,就点个赞吧
0 人点赞
