Cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
Shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
replicas
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
Recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
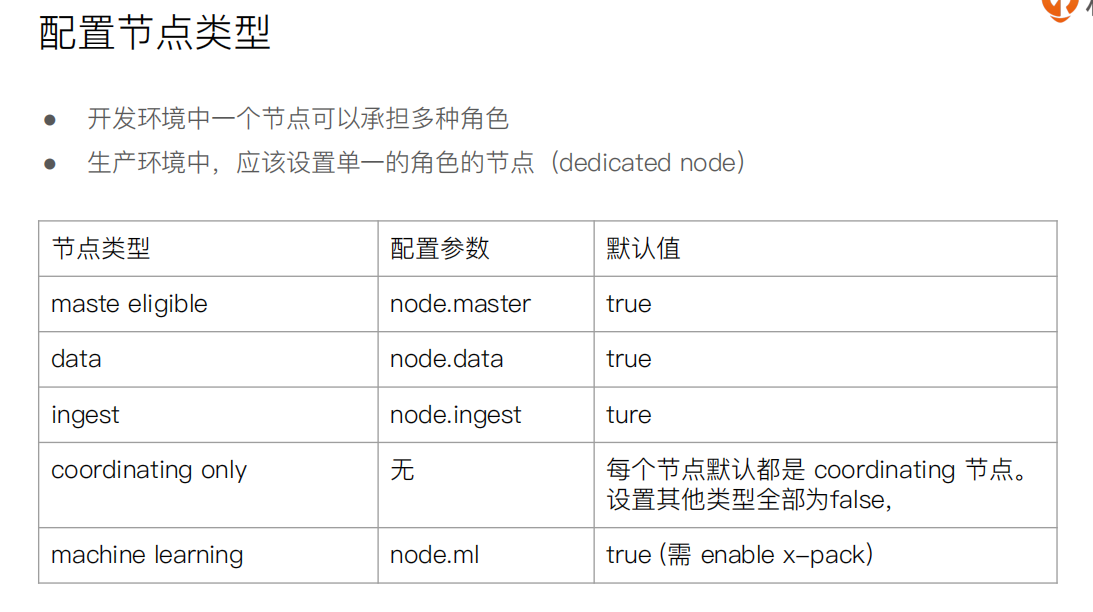
1 节点类型
1 客户端(协调)节点
每个节点都此功能,当主节点和数据节点配置都设置为false的时候,该节点只能处理路由请求,处理搜索,分发索引操作等,从本质上来说该客户节点表现为智能负载平衡器。独立的客户端节点在一个比较大的集群中是非常有用的,他协调主节点和数据节点,客户端节点加入集群可以得到集群的状态,根据集群的状态可以直接路由请求。
2 数据节点
数据节点主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。数据节点对cpu,内存,io要求较高, 在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
3 主节点
主资格节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康是非常重要的,默认情况下任何一个集群中的节点都有可能被选为主节点,索引数据和搜索查询等操作会占用大量的cpu,内存,io资源,为了确保一个集群的稳定,分离主节点和数据节点是一个比较好的选择。
4 Ingest节点
ingest 节点可以看作是数据前置处理转换的节点,支持 pipeline管道 设置,可以使用 ingest 对数据进行过滤、转换等操作,类似于 logstash 中 filter 的作用,功能相当强大。
我把Ingest节点的功能抽象为:大数据处理环节的“ETL” ——抽取、转换、加载。
前Elastic中国架构师吴斌的文章中对Ingest节点的评价很高,他指出
“2018这一年来拜访了很多用户,其中有相当一部分在数据摄取时遇到包括性能在内的各种各样的问题,那么大多数在我们做了ingest节点的调整后得到了很好的解决。Ingest节点不是万能的,但是使用起来简单,而且抛开后面数据节点来看性能提升趋于线性。所以我一直本着能用ingest节点解决的问题,绝不麻烦其他组件的大体原则”。
3、Ingest 节点能解决什么问题?
4.建议
在一个生产集群中我们可以对这些节点的职责进行划分,建议集群中设置3台以上的节点作为master节点,这些节点只负责成为主节点,维护整个集群的状态。再根据数据量设置一批data节点,这些节点只负责存储数据,后期提供建立索引和查询索引的服务,这样的话如果用户请求比较频繁,这些节点的压力也会比较大,所以在集群中建议再设置一批client节点(node.master: false node.data: false),这些节点只负责处理用户请求,实现请求转发,负载均衡等功能。

若有收获,就点个赞吧
0 人点赞
