- 1 索引
- 2 Document 文档
- 分片
- 倒排索引
- ES和RDBMS的类比
- 3 ES分布式集群
- ES分布式架构好处
- ES的分布式架构
- Master-eligible nodes 和Master Node
- Data Node & Coordinating Node
- 集群的健康情况
- Green
- Yellow
- Red
- 文档的基本CRUD与批量操作
- Create
- Get
- Index
- Update
- Bulk API
- mget
- msearch
- 常见错误返回
- Analyzer
- Analysis与Analyzer
- 组成
- 步骤举例
- ES内置的分词器
- 中文分词的难点
- Search API
- URI Search
- Request Body Search
- 指定查询的索引
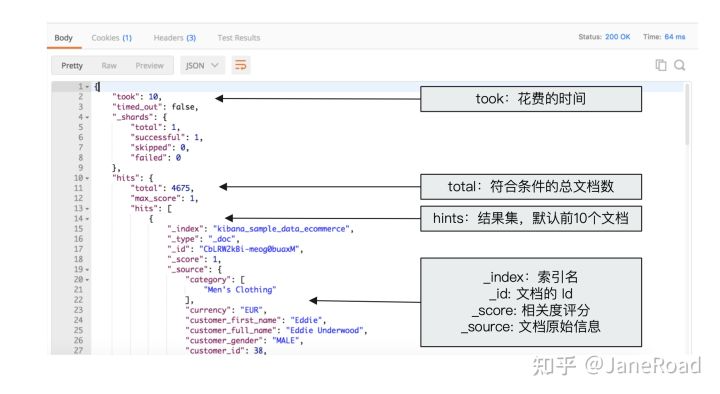
- 搜索Response
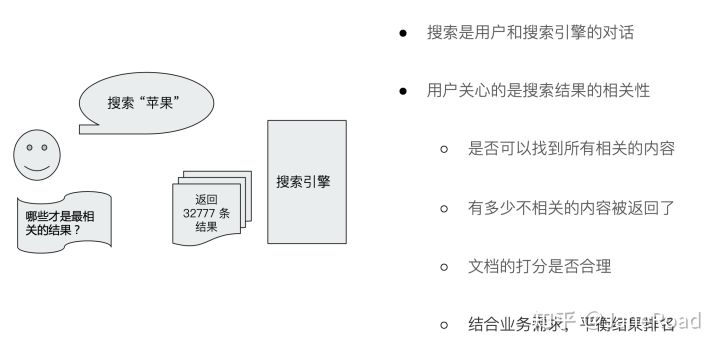
- 搜索的相关性 Relevance
- Web搜索
- 电商搜索
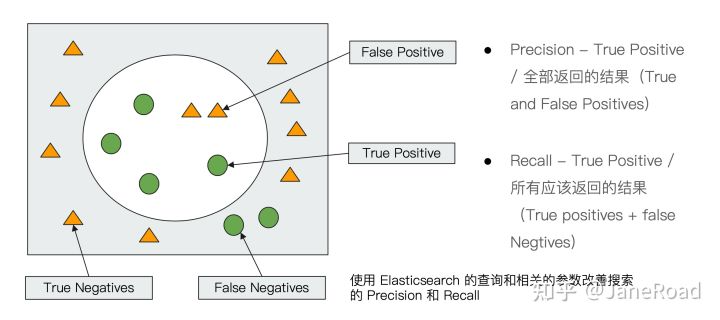
- 衡量相关性
- Precision & Recall
- Dynamic Mapping 和常见字段类型
- Mapping
- 字段的数据类型
- 什么是Dynamic Mapping
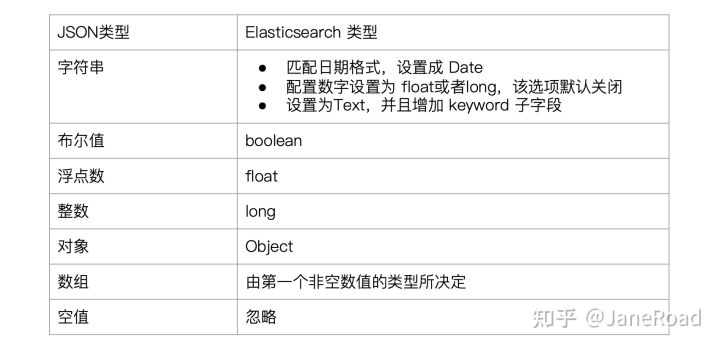
- 类型的自动识别
- 能否更改Mapping的字段类型
- 控制Dynamic Mappings
- 显示Mapping设置与常见参数介绍
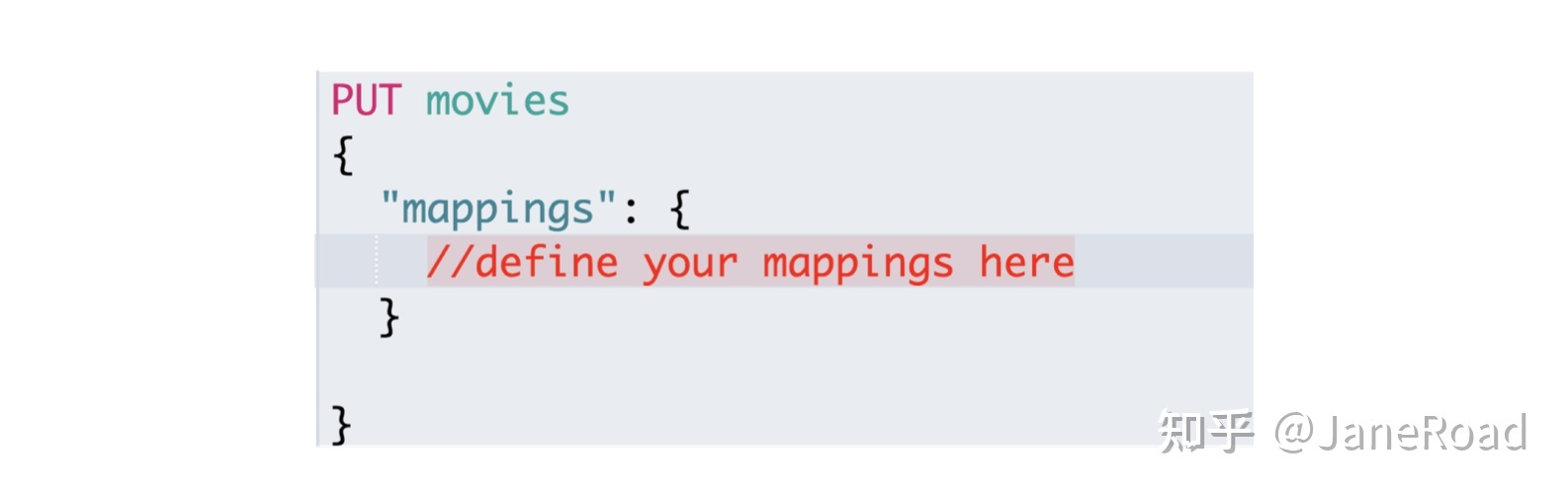
- 如何显示地定义一个Mapping
- 自定义Mapping的建议
- 控制当前字段是否被索引
- Index Options
- Null Value
- Copy_to设置
- 数组类型
- 多字段特性及配置自定义分词器
- 多字段类型
- Exact Values VS Full Text
- 自定义分词
- Index Template 和 Dynamic Template
- 管理很多的索引
- Index Template
- Dynamic Template
- 匹配规则参数
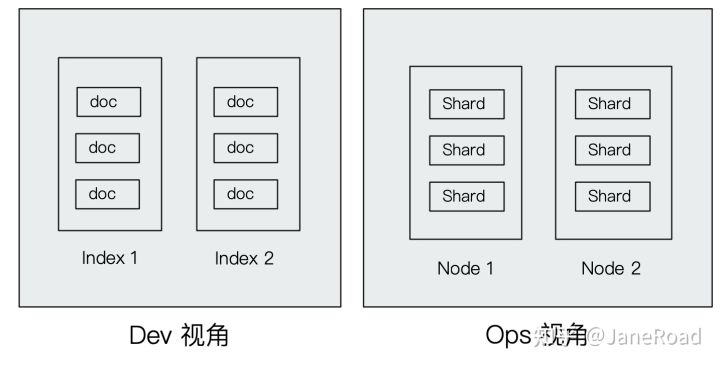
1 索引

索引是文档的容器,是一类文档的结合
- index体现了逻辑空间的概念,每个索引都有自己的mapping定义,由于定义包含的文档的字段名和字段类型
- shard体现了物理空间的概念,索引中的数据分散在Shard上
索引的「Mapping」和「Settings」
ES是面向文档的,文档是所有可搜索数据的最小单位
- 日志中的文件项
- 一部电影中的具体信息
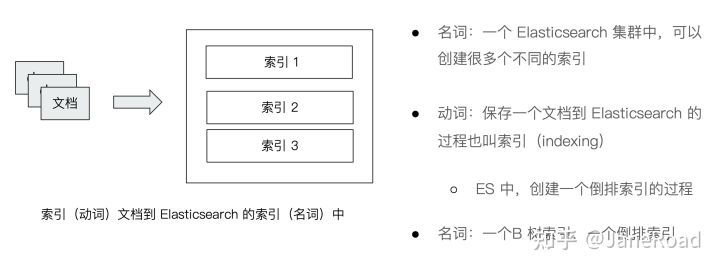
文档会被序列化成JSON格式保存在ES中
每个文档都有一个Unique ID
可以自己指定也可以由ES生成
2.1 JSON文档
- 一篇文档包含了一系列的字段。类似数据库的一条记录
格式灵活不需要预先定义格式
_index :文档所属的索引名
- _type :文档所属的类型名
- _id :文档唯一id
- _score :相关性得分
- _source :文档的原始JSON数据
- _all :整合所有字段内容到该字段,已被废除
- _version :文档的版本信息

分片
主分片
用来解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内的所有节点之上
副本
用来解决数据高可用的问题。副本分片是主分片的拷贝
- 副本分片数可以动态调整
-
分片的设定
分片数设定过小
后续无法增加节点实现水平扩展
-
分片数设定过大
7.0开始默认主分片设置为1,解决了over-sharding的问题
影响搜索结果的相关性打分,影响统计结果的准确性
-
倒排索引
介绍
正排和倒排的区别
正排
倒排
图书和搜索引擎的类比
图书
- 正排索引-目录页
- 倒排索引-英文首字母索引页


搜索引擎
文档ID
词频TF
该单词在文档中出现的次数,用于相关性评分位置
单词在文档中分词的位置。用于语句搜索偏移
记录单词的开始结束位置,实现高亮显示
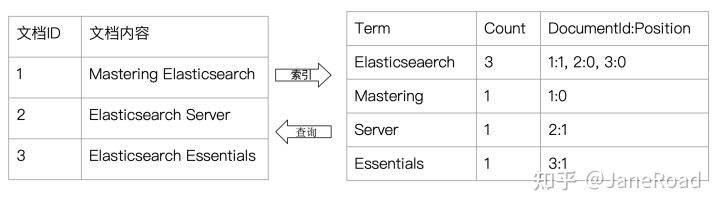
图片举例
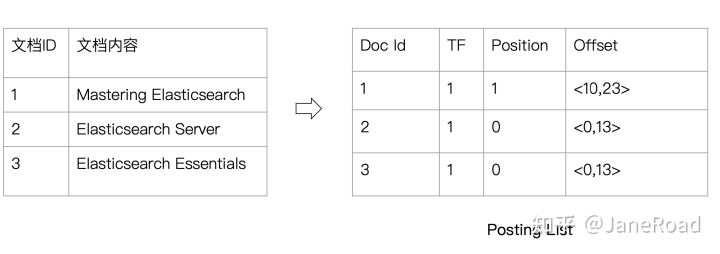
ES的倒排索引
- ES的JSON文档中每个字段都有自己的倒排索引
可以指定对某些字段不做索引
存储的水平扩容
-
ES的分布式架构
不同集群通过不同名字区分,默认名字elasticsearch
- 通过配置文件修改
-
Master-eligible nodes 和Master Node
每个节点启动后默认是Master eligible节点
- 可以设置node.maser:false 来禁止

- Master-eligible节点可以参加选主流程,成为Master节点
- 当第一个节点启动时候,它会将自己选举为Master节点
每个节点上都保存了集群的状态,只有Master节点才能修改集群状态信息
- 集群状态,维护了一个集群中必要的信息
- 所有节点信息
- 所有索引和相关的Mapping和Setting信息
- 分片的路由信息
- 任意节点都能修改信息会导致数据的不一致性
Data Node & Coordinating Node
Data Node
可以保存数据的节点,叫做 DataNode。
负责保存分片的数据。
数据扩展中它是很重要的角色Coordinating Node
负责接收Client的请求,将请求分发到合适的节点,最终把结果汇集到一起。集群的健康情况
Green
主分片和副本都能正常分配Yellow
主分片全部正常分配
有副本分片未能正常分配Red
有主分片未能正常分配文档的基本CRUD与批量操作

Create

Get

Index

Update

Bulk API
每行需要指定index信息,也可以在URI中指定mget
批量读取,可以减少网络连接产生的开销msearch
批量查询常见错误返回

Analyzer
Analysis与Analyzer
Analysis的意思是文本分析。把「全文本」转换为「一系列单词」的过程,也叫「分词」。
Analysis是通过Analyzer实现的,Analyzer叫分词器。
可以使用ES内置的分词器,也可以按照需求自制分词器。
除了在写入数据的时候转换词条,匹配Query语句时候也需要用相同的分析器对查询语句进行分析。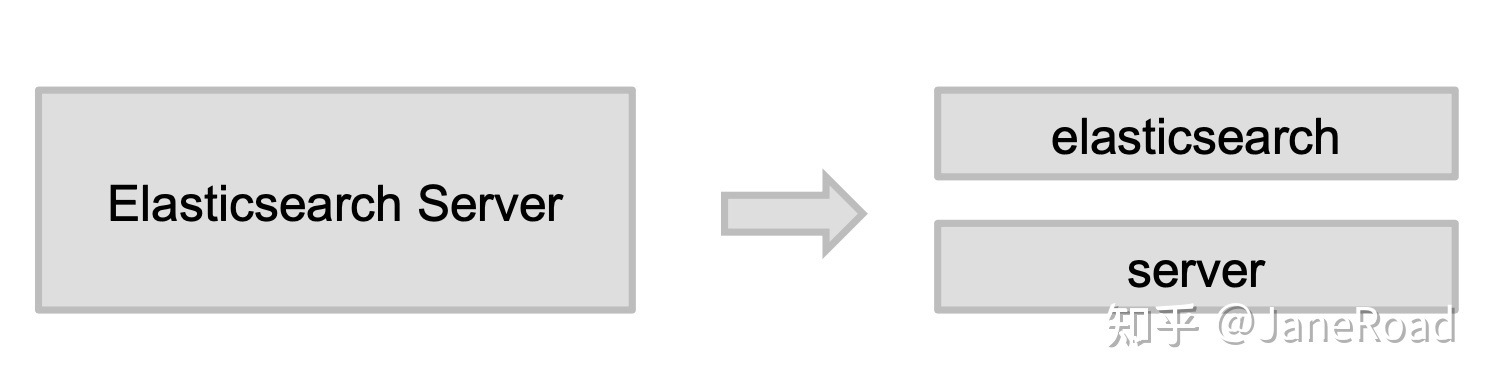
组成
分词器是专门处理分词的软件,Analyzer有三部分组成Character Filters
针对原始文本进行处理,例如去除HTMLTokenizer
按照规则切分单词Token Filter
将切分的单词进行加工,小写,删除stopwords,增加同义词步骤举例
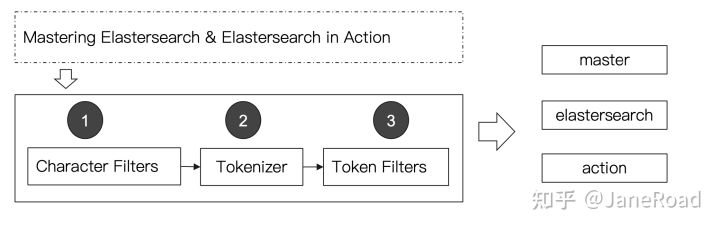
ES内置的分词器

Standard Analyzer
- 集群状态,维护了一个集群中必要的信息
默认分词器
- 按词切分
- 小写处理
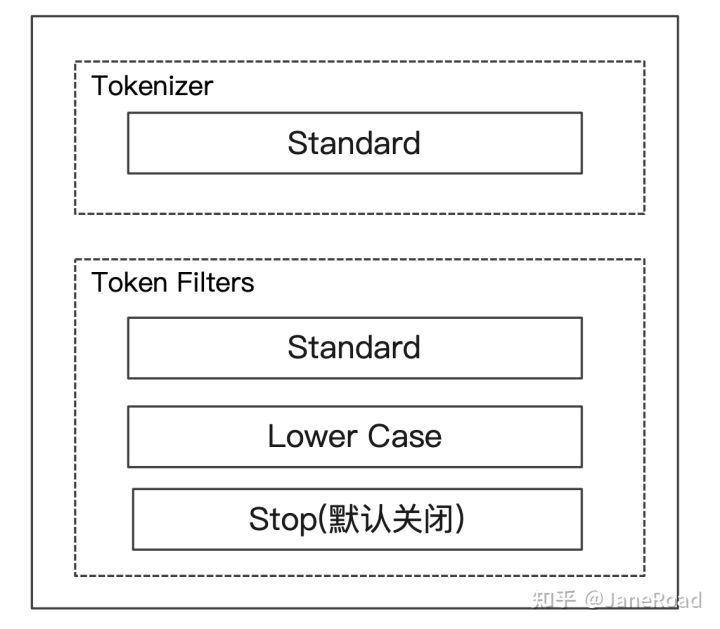
Simple Analyzer
- 按照非字母切分,非字母的都去除
- 小写处理
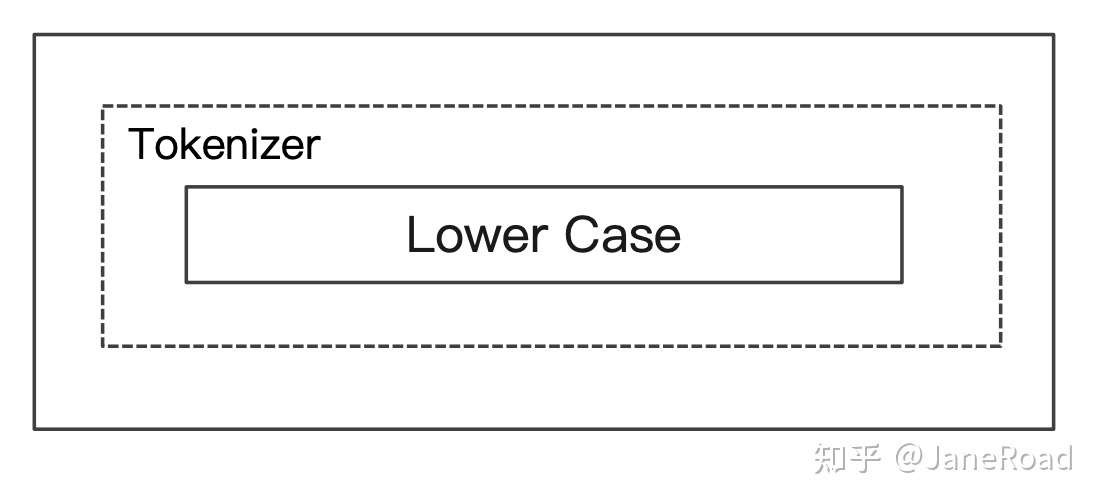
While Space
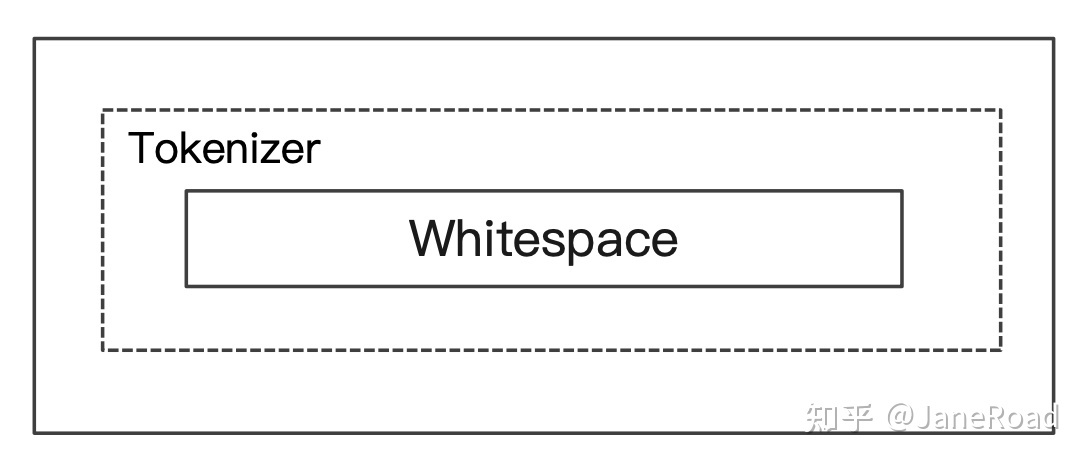
Stop Analyzer
相比于Simple Analyzer多了Stop Filter 会把 the ,a,is 等修饰语去除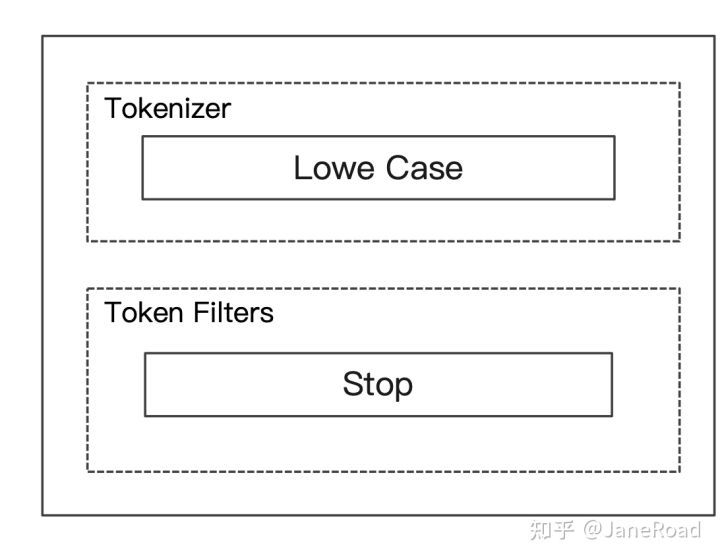
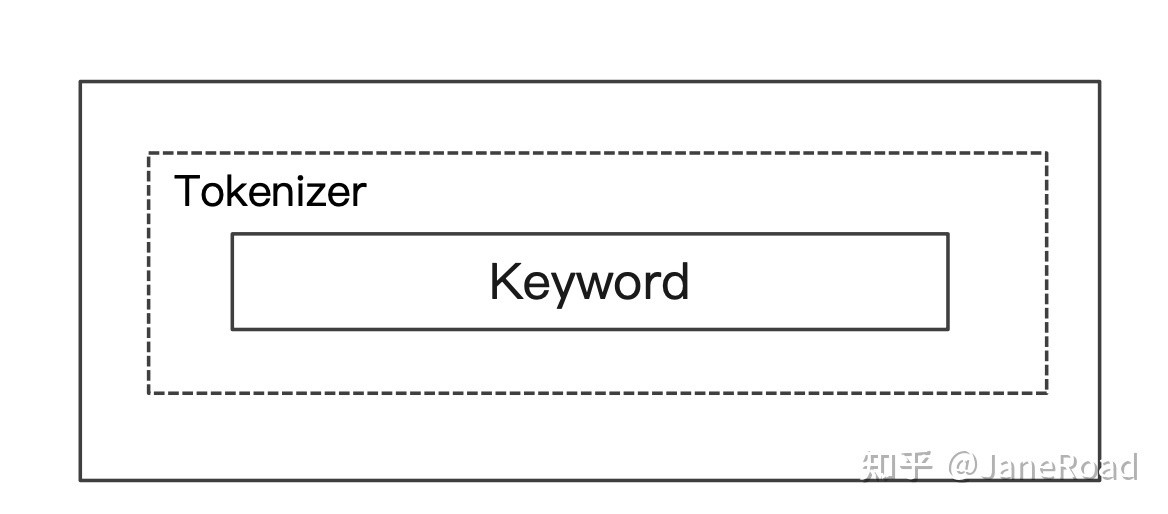
Keyword Analyzer
Pattern Analyzer
- 通过正则分词
- 默认是 \W+ 非字符的符号进行分隔

Language Analyzer
中文分词的难点
- 中文句子切分成一个一个词而不是一个一个字
- 英文中有天然的空格作为间隔
- 一句中文,在不同的上下文中可能有不同的意思
Search API
URI Search
在URL中使用查询参数

通过URI Query实现搜索

Query String Syntax(语法)




Request Body Search
ES提供的基于JSON格式的 Query Domain Specific Language(DSL)
分页

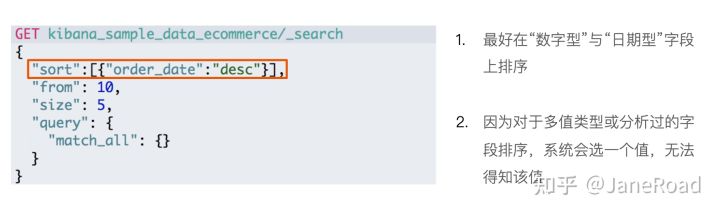
排序
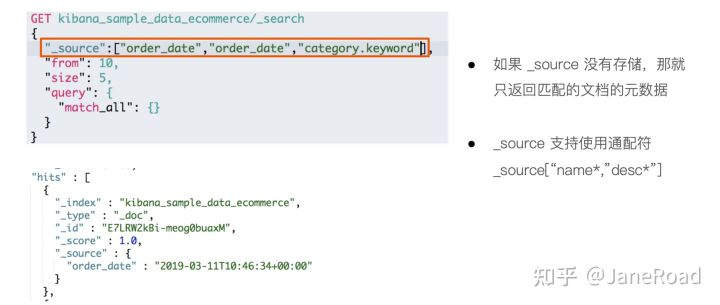
_source filtering
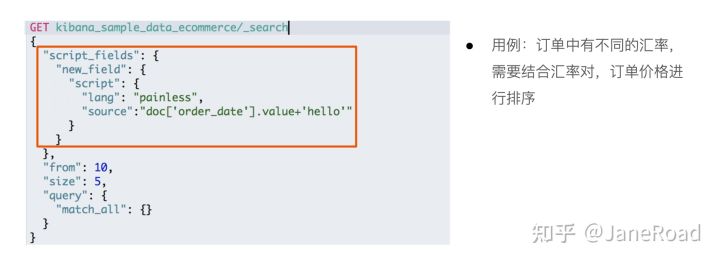
脚本字段
使用查询表达式

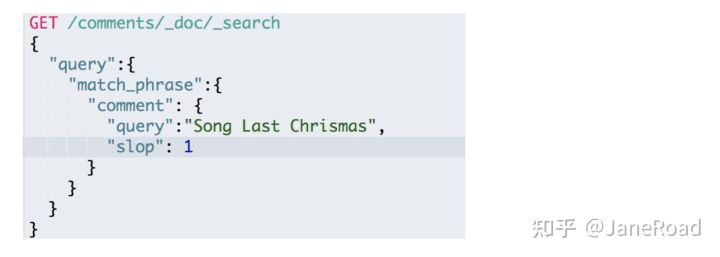
短语搜索
指定查询的索引
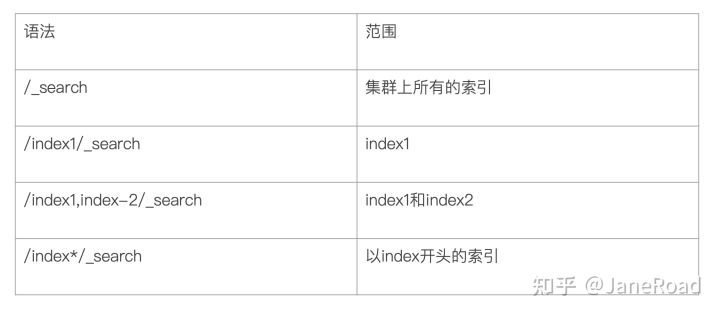
搜索Response
搜索的相关性 Relevance
Web搜索
电商搜索
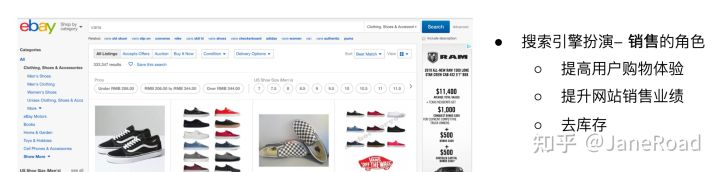
衡量相关性

Precision & Recall
Dynamic Mapping 和常见字段类型
Mapping

字段的数据类型

什么是Dynamic Mapping

类型的自动识别
能否更改Mapping的字段类型

控制Dynamic Mappings

显示Mapping设置与常见参数介绍
如何显示地定义一个Mapping
自定义Mapping的建议

控制当前字段是否被索引
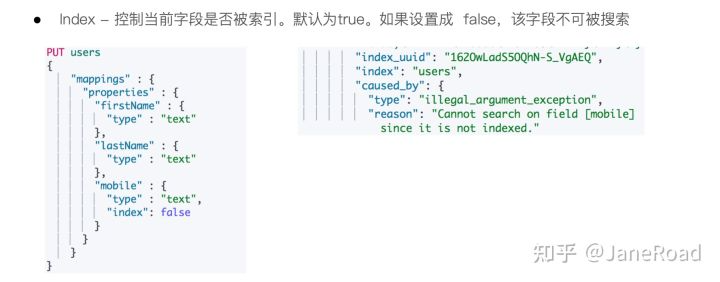
Index Options

Null Value

Copy_to设置

数组类型

多字段特性及配置自定义分词器
多字段类型

Exact Values VS Full Text

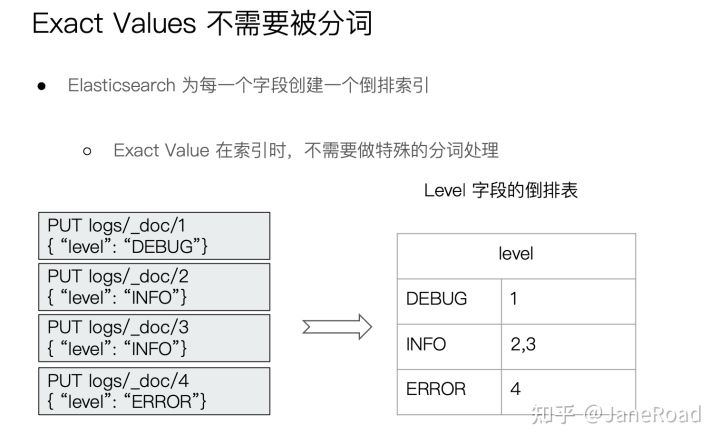
自定义分词


Index Template 和 Dynamic Template
管理很多的索引

Index Template


工作方式

Dynamic Template


匹配规则参数


若有收获,就点个赞吧
0 人点赞
