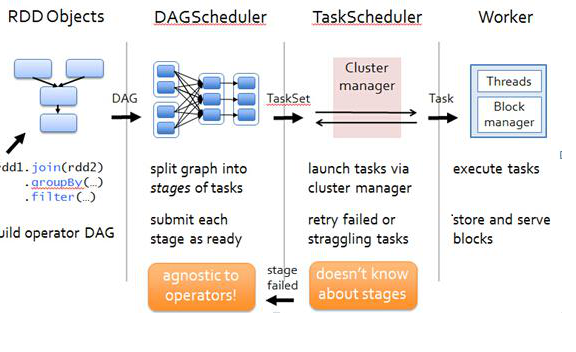
所谓划分算法就是:从最后一个RDD往前推算,遇到窄依赖(NarrowDependency)就将其加入该Stage,当遇到宽依赖(ShuffleDependency)则断开。每个Stage 里task的数量由Stage最后一个RDD中的分区数决定。如果Stage要生成Result,则该Stage里的Task都是ResultTask,否则是ShuffleMapTask
具体解释为:在程序正式运行前,Spark的DAG调度器会将整个流程设定为一个Stage,此Stage包含3个操作,5个RDD,分别为MapPartitionRDD(读取文件数据时)、MapPartitionRDD(flatMap操作)、MapPartitionRDD(map操作)、MapPartitionRDD(reduceByKey的local段的操作)、ShuffleRDD(reduceByKeyshuffle操作)。
(1)回溯整个流程,在shuffleRDD与MapPartitionRDD(reduceByKey的local段的操作)中存在shuffle操作,整个RDD先在此切开,形成两个Stage。<br /> (2)继续向前回溯,MapPartitionRDD(reduceByKey的local段的操作)与MapPartitionRDD (map操作)中间不存在Shuffle(即两个RDD的依赖关系为窄依赖),归为同一个Stage。<br /> (3)继续回溯,发现往前的所有的RDD之间都不存在Shuffle,应归为同一个Stage。<br /> (4)回溯完成,形成DAG,由两个Stage构成:
第一个Stage由MapPartitionRDD(读取文件数据时)、MapPartitionRDD(flatMap操作)、MapPartitionRDD(map操作)、MapPartitionRDD(reduceByKey的local段的操作)构成。第二个Stage由ShuffleRDD(reduceByKey Shuffle操作)构成。
参考

若有收获,就点个赞吧
0 人点赞
