一句话介绍 :Elasticsearch是「实时」的「分布式搜索分析引擎」,内部使用 Lucene 做索引与搜索。
主要功能
分布式搜索引擎
大数据近实时分析引擎
产品特性
- 高性能
- 易用
- 易扩展
1 与的关系 Lucene
Lucene
- 是基于Java语言开发的类库
- 具有高性能、易扩展的特点
- 具有局限性
- 只能基于Java语言开发
- 类库的接口学习曲线陡峭
- 原生并不支持水平扩展
与Lucene关系
ES是基于Lucene开发的,主要扩展点在于
- 支持分布式
- 可水平扩展
- 降低了全文检索的学习曲线
-
2 生态圈
2.1 与数据库集成
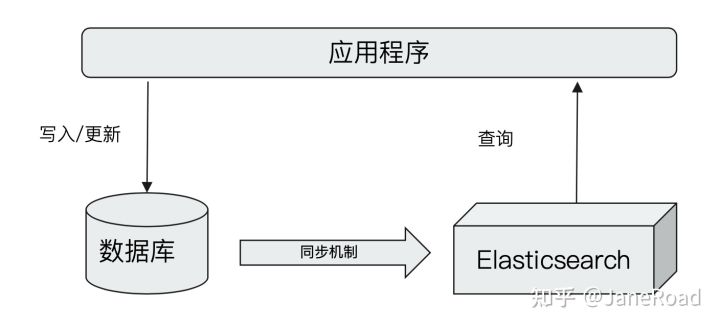
单独使用ES存储
与数据库并存,集成
Kibana是操作ElasticSearch的图形化工具
- 基于Node.js,可以通过web进行操作
- 使用Kibana进行API操作时,有友好提示
- Kibana工具可以生成各种图表
4 与mysql
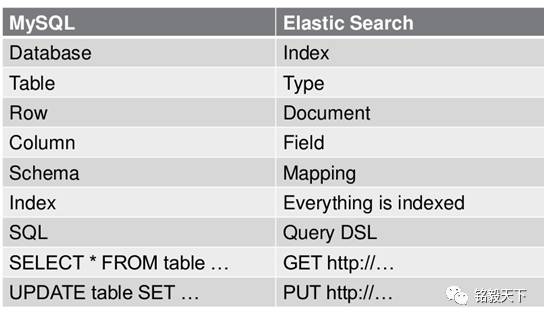
(1)关系型数据库中的数据库(DataBase),等价于ES中的索引(Index)
(2)一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type), 但是type适合放置java继承关系的类。

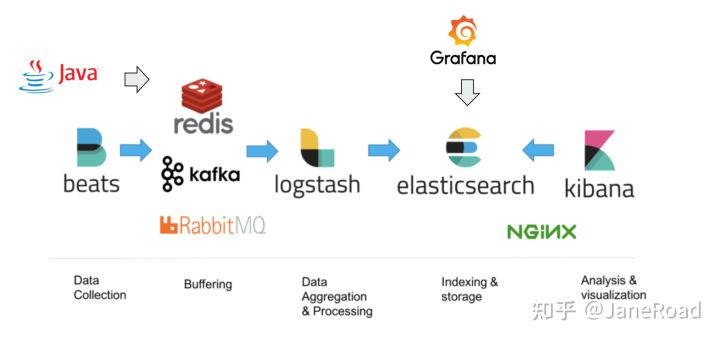
1 type,是一个index中用来区分类似的数据的,类似的数据,但是可能有不同的fields,而且有不同的属性来控制索引建立、分词器
2 field的value,在底层的lucene中建立索引的时候,全部是opaque bytes类型,不区分类型的
3 lucene是没有type的概念的,在document中,实际上将type作为一个document的field来存储,即_type,es通过_type来进行type的过滤和筛选
4 一个index中的多个type,实际上是放在一起存储的,因此一个index下,不能有多个type重名,而类型或者其他设置不同的,因为那样是无法处理的
(3)一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成。
(4)在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
(5)在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET.
本地部署与水平扩展

其中主要有如下几个核心术语需要理解:
- 词条(Term): 索引里面最小的存储和查询单元,对于英文来说是一个单词,对于中文来说一般指分词后的一个词。
- 词典(Term Dictionary): 或字典,是词条 Term 的集合。搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
- 倒排表(Post list): 一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过以及出现的位置。每条记录称为一个倒排项(Posting)。倒排表记录的不单是文档编号,还存储了词频等信息。
- 倒排文件(Inverted File): 所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
从上图我们可以了解到倒排索引主要由两个部分组成:
- 词典
- 倒排文件
词典和倒排表是 Lucene 中很重要的两种数据结构,是实现快速检索的重要基石。词典和倒排文件是分两部分存储的,词典在内存中而倒排文件存储在磁盘上

若有收获,就点个赞吧
0 人点赞
