一. sql映射文件
1. 模糊查询
public interface UserMapper {List<User> findAllUsers();/** TODO 模糊查询 : 查询名字包含 '关键字' 的所有用户* -- like 关键字: 模糊查询-- % 表示0个或多个-- _下划线 表示1个* sql :* select * from user where username like ?* 参数:* keyword = 王 , 拼接之后: %王%* 返回值: List<User>* */List<User> findUserByKd1(String keyword);List<User> findUserByKd2(String keyword);List<User> findUserByKd3(String keyword);List<User> findUserByKd4(String keyword);}
userMapper.xml
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.itheima01.dao.UserMapper"><select id="findAllUsers" resultType="user">select * from user</select><!--TODO 模糊查询有4种做法,但是大家只要掌握一种1. 第一种:传参的时候指定通配符 -> %王%不好: java中使用了sql的符号,耦合--><select id="findUserByKd1" resultType="user">select * from user where username like #{keyword}</select><!--模糊查询,方式二【了解】mysql5.5版本之前,此拼接不支持多个单引号oracle数据库,除了别名的位置,其余位置都不能使用双引号'%'空格#{keyword}空格'%'--><select id="findUserByKd2" resultType="user">select * from user where username like '%' #{keyword} '%'</select><!--模糊查询,方式三【此方式,会出现sql注入...】${} 字符串拼接,如果接收的简单数据类型,表达式名称必须是value${} : 没有预编译的引用(sql注入风险)#{} : 有预编译的引用--><select id="findUserByKd3" resultType="user">select * from user where username like '%${value}%'</select><!--TODO 模糊查询,方式四【掌握!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!】使用concat()函数拼接 : mysql函数可以多参数注意:oracle数据库 concat()函数只能传递二个参数... 可以使用函数嵌套来解决concat(concat('%',#{username}),'%');--><select id="findUserByKd4" resultType="user">select * from user where username like concat('%',#{username},'%')</select></mapper>
测试类
public class Demo01 {@Testpublic void method01(){SqlSession sqlSession = MyBatisUtil.openSession(true);UserMapper mapper = sqlSession.getMapper(UserMapper.class);//第一种实现: 不用!// List<User> list = mapper.findUserByKd1("%三%");// List<User> list = mapper.findUserByKd2("三");// List<User> list = mapper.findUserByKd3("三");List<User> list = mapper.findUserByKd4("三");for (User user : list) {System.err.println(user);}sqlSession.close();}}
重点: ${} 与 #{} 区别【面试题】
**${}**:底层 Statement
- sql与参数拼接在一起,会出现sql注入问题
- 每次执行sql语句都会编译一次
**#{}**:底层 PreparedStatement
- sql与参数分离,不会出现sql注入问题
- sql只需要编译一次
${}在mybatis核心配置文件中使用, 而#{}在sql配置中使用
2. 主键回填
public interface UserMapper {/*主键回填:单参无需参数映射返回值: 被影响行数*/int addUserReturnId(User user);}
userMapper.xml
<!--
方案一: 这表的主键必须是自增长的 auto_increment (了解)
useGeneratedKeys="true" 让自增长的主键开启返回功能
keyColumn="id" user表中主键列
keyProperty="id" 参数user实体主键属性
注意:支持主键自增类型的数据库 MySQL 和 SqlServer , oracle不支持
含义: 将新增记录中的主键id值赋值user对象的id属性!!!
-->
<!-- <insert id="addUserReturnId" useGeneratedKeys="true" keyColumn="id" keyProperty="id">
insert into user
values(null,#{username},#{birthday},#{sex},#{address});
</insert>-->
<!--
方案二: <selectKey> (掌握)
keyColumn="id" user表中主键列
keyProperty="id" 参数user实体主键属性
resultType="int" user实体主键属性类型 (int或string)
order="AFTER" 表示此标签内部sql语句在insert执行之前(执行),还是之后执行(执行)
AFTER 之后执行【在自增主键时】
BEFORE 之前执行【使用指定主键时】
# SELECT LAST_INSERT_ID()
查询上一条新增数据的主键字段
这个函数必须跟在insert语句之后
# 理解
在insert语句之后,执行SELECT LAST_INSERT_ID(),要返回主键字段的值
这个主键字段名为id,填充给参数(user对象)的int类型属性id
-->
<insert id="addUserReturnId">
<selectKey keyColumn="id" keyProperty="id" resultType="int" order="AFTER">
SELECT LAST_INSERT_ID()
</selectKey>
insert into user values(null, #{username},#{birthday},#{sex},#{address})
</insert>
测试类
//主键回填
@Test
public void method02(){
SqlSession sqlSession = MyBatisUtil.openSession(true);
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
//主键回填: 新增一条数据之后, 数据库会将这条数据的主键字段填充回来
User user = new User();
user.setUsername("饺子3");
user.setBirthday("1995-01-01");
user.setSex("男");
user.setAddress("杭州");
//User{id=null, username='饺子4', birthday='1995-01-01', sex='男', address='杭州'}
System.err.println(user); // id=null
int count = mapper.addUserReturnId(user);
System.err.println("被影响的行数:" + count);
//User{id=18, username='饺子4', birthday='1995-01-01', sex='男', address='杭州'}
System.err.println(user); // id有东西
Integer id = user.getId();
System.err.println(id);
sqlSession.close();
}
3.动态sql
3.1 where和if标签
public interface UserMapper {
/*
动态sql: sql会根据实际情况动态变化
1. name有可能没有,表示用户没有输入搜索用户名
2. sex有可能没有,表示用户没有输入搜索性别
*/
List<User> findUserByDynamicCondition(@Param("name") String name,
@Param("sex")String sex);
}
userMapper.xml
<!--
TODO: 动态sql
1. where标签
1). 作用: 动态添加where关键字
有条件添加where,没有条件不添加
还会对后续关键字适当调整
2. if标签
test属性: (sql语句判断: 对参数映射的取值)
1). 结果返回boolean类型,如果是true,if标签内部的sql将保留,如果为false,就不保留
2). name != null and name != ''
排除两种情况, name不能是null且不能为空字符串,如果返回true,name一定有东西
-->
<select id="findUserByDynamicCondition" resultType="user">
select * from user
<where>
<if test="name != null and name != '' ">
username = #{name}
</if>
<if test="sex != null and sex != '' ">
and sex = #{sex}
</if>
</where>
</select>
测试类
//动态搜索
@Test
public void method03(){
SqlSession sqlSession = MyBatisUtil.openSession(true);
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
/*
TODO:
场景1: 用户在搜索的时候,既没有输入用户名,又没有输入性别 -> 查询所有
select * from user
场景2: 用户在搜索的时候,输入用户名,但是没有输入性别 -> 根据用户名查询用户
select * from user WHERE username = ?
场景3: 用户在搜索的时候,输入用户名,又输入性别 -> 根据用户名和性别查询用户
select * from user WHERE username = ? and sex = ?
场景4: 用户在搜索的时候,不输入用户名,但是输入性别
select * from user WHERE sex = ?
*/
// List<User> list = mapper.findUserByDynamicCondition(null, null);
// List<User> list = mapper.findUserByDynamicCondition("饺子", null);
// List<User> list = mapper.findUserByDynamicCondition("饺子", "男");
List<User> list = mapper.findUserByDynamicCondition(null, "男");
for (User user : list) {
System.err.println(user);
}
sqlSession.close();
}
3.2 set标签
public interface UserMapper {
int updateUserByDynamicCondition(User user);
}
userMapper.xml
<!--
update user
set uname = ?,birthday=?,sex=?,address=? where id = ?;
set标签: 会自动调整内部的sql
-->
<update id="updateUserByDynamicCondition">
update user
<set>
<if test="username != null and username != '' ">
username = #{username},
</if>
<if test="birthday != null and birthday != '' ">
birthday = #{birthday},
</if>
<if test="sex != null and sex != '' ">
sex = #{sex},
</if>
<if test="address != null and address != '' ">
address = #{address}
</if>
</set>
where id = #{id};
</update>
测试类
@Test
public void method04(){
SqlSession session = MyBatisUtil.openSession(true);
UserMapper mapper = session.getMapper(UserMapper.class);
/*
sql:
1). 一条记录所有字段全修改
update user set username=?,birthday=?, sex=?,
address = ? where id = ?;
2). 动态sql
update user set username=? where id = ?;
update user SET username = ?, sex = ? where id = ?;
*/
User user = new User();
user.setId(18);
user.setUsername("天津饭2");
user.setSex("女");
mapper.updateUserByDynamicCondition(user);
session.close();
}
3.3 foreach标签
public interface UserMapper {
List<User> findUserByIds(@Param("ids") ArrayList<Integer> ids);
}
userMapper.xml
<!--
动态sql :
1. where
2. if标签的判断: 排除ids没有元素的情况
3. foreach标签
1). collection : 被遍历的集合
2). item : 遍历出来的每个元素
3). open : 开始循环之前拼接的符号
4). close : 结束循环之后拼接的符号
5). separate :分隔符
注意: foreach的collection指定的集合变量必须要指定参数映射!!!!
-->
<select id="findUserByIds" resultType="user">
select * from user
<where>
<if test="ids != null and ids.size != 0">
id in
<foreach collection="ids" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</if>
</where>
</select>
测试类
@Test
public void method05(){
SqlSession session = MyBatisUtil.openSession(true);
UserMapper mapper = session.getMapper(UserMapper.class);
ArrayList<Integer> ids = new ArrayList<>();
Collections.addAll(ids,15,16,17,18);
// ids.add(16);
// ids.add(17);
// ids.add(18);
/*
select * from user WHERE id in ( ? , ? , ? );
-> 等价select * from user WHERE id = 16 or id = 17 or id = 18;
场景: 批量操作(批量搜索,批量删除...)
*/
List<User> list = mapper.findUserByIds(ids);
for (User user : list) {
System.err.println(user);
}
session.close();
/* String result = "";
result += "(";
for (Integer item : ids) {
result += item + ",";
}
result += ")";
System.out.println(result);*/
}
4.4 sql片段
userMapper.xml
<select id="findUserByIds" resultType="user">
<include refid="xx"/>
<where>
<if test="ids != null and ids.size != 0">
id in
<foreach collection="ids" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</if>
</where>
</select>
<!--
TODO: sql片段
1). 封装的思想
在sql映射文件中,可以使用sql标签抽取重复出现的sql
2). 使用
I. sql标签包含重复的sql,用id给自己作个标识
II. 别的地方要用
<include refid="xx"/>
referenceid 关联sql标签
-->
<sql id="xx">
select * from user
</sql>
二. 多表查询
数据准备
create database if not exists `day09`;
-- 如果不存在day09数据仓库,则创建
USE `day09`;
-- 切换day09仓库
/*Table structure for table `user` */
DROP TABLE IF EXISTS `user`;
-- 如果存在user表则删除
CREATE TABLE `user` (
`id` int(11) NOT NULL auto_increment,
`username` varchar(32) NOT NULL COMMENT '用户名称',
`birthday` datetime default NULL COMMENT '生日',
`sex` varchar(10) default NULL COMMENT '性别',
`address` varchar(256) default NULL COMMENT '地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
--
/*Data for the table `user` */
insert into `user`(`id`,`username`,`birthday`,`sex`,`address`) values (41,'老王','2019-05-27 17:47:08','男','北京'),(42,'王小二','2019-03-02 15:09:37','女','北京金燕龙'),(43,'老李','2019-03-04 11:34:34','女','北京修正'),(45,'传智播客','2019-03-04 12:04:06','男','北京金燕龙'),(46,'王小二','2018-09-07 17:37:26','男','北京TBD'),(48,'小马宝莉','2019-03-08 11:44:00','女','北京修正');
DROP TABLE IF EXISTS `orders`;
-- 创建订单表
CREATE TABLE `orders` (
`id` int(11) NOT NULL AUTO_INCREMENT, -- 订单编号,主键
`uid` int(11) DEFAULT NULL, -- 订单所属的用户编码,外键
`ordertime` datetime DEFAULT NULL, -- 订单时间
`money` double DEFAULT NULL, -- 订单总价
PRIMARY KEY (`id`),
KEY `uid` (`uid`),
CONSTRAINT `orders_ibfk_1` FOREIGN KEY (`uid`) REFERENCES `user` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
/*Data for the table `orders` */
insert into `orders`(`id`,`uid`,`ordertime`,`money`) values (1,41,'2019-05-20 02:58:02',999.5),(2,45,'2019-02-14 07:58:00',1399),(3,41,'2019-06-01 21:00:02',1666);
DROP TABLE IF EXISTS `role`;
-- 创建角色表
CREATE TABLE `role` (
`id` int(11) NOT NULL COMMENT '编号',
`role_name` varchar(30) default NULL COMMENT '角色名称',
`role_desc` varchar(60) default NULL COMMENT '角色描述',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `role` */
insert into `role`(`ID`,`role_name`,`role_desc`) values (1,'院长','管理整个学院'),(2,'总裁','管理整个公司'),(3,'校长','管理整个学校');
/*Table structure for table `user_role` */
DROP TABLE IF EXISTS `user_role`;
-- 用户角色中间表
CREATE TABLE `user_role` (
`uid` int(11) NOT NULL COMMENT '用户编号',
`rid` int(11) NOT NULL COMMENT '角色编号',
PRIMARY KEY (`uid`,`rid`), -- 联合主键
KEY `FK_Reference_10` (`rid`),
CONSTRAINT `FK_Reference_10` FOREIGN KEY (`rid`) REFERENCES `role` (`id`),
CONSTRAINT `FK_Reference_9` FOREIGN KEY (`uid`) REFERENCES `user` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `user_role` */
insert into `user_role`(`uid`,`rid`) values (41,1),(45,1),(41,2);
2.1 多表关系回顾
# sql多表关系
1. 一对多
1). 建表原则:
在多方添加一方的主键作为外键
2). 一方: user表 (主表)
3). 多方: orders表 (从表)
一个user可以下多个订单
一个订单只属于一个user
2. 多对多
1). 建表原则:
创建一张中间表,关联两张主表的主键作为外键
2). 多方: user表 (主表)
3). 多方: role表 (主表)
一个user可以拥有多个角色身份
一个角色可以属于多个user
4). 中间表: user_role表 (从表)
3. 一对一
1). 建表原则:
在任意一方添加另一方的主键作为外键,外键需要唯一约束
2.2 mybatis多表查询
# myabtis多表查询
0. 在myabtis眼里,所有的多表关系只需要两种表达
1. 一对一
2. 一对多
# 举例
1. sql中的一对多 (user表 : orders表)
0). mybatis眼里: 主体是谁
1). user对orders : 一对多(一个用户可以下多个订单)
2). orders对user : 一对一(一个订单只属于一个用户)
2. sql中的多对多(user表: role表)
0). mybatis眼里: 主体是谁
1). user对role : 一对多(一个用户可以拥有多个角色)
2). role对user : 一对多(一个角色可以被多个用户所扮演)
3. sql中的一对一
0). mybatis眼里
1). 就是两个一对一
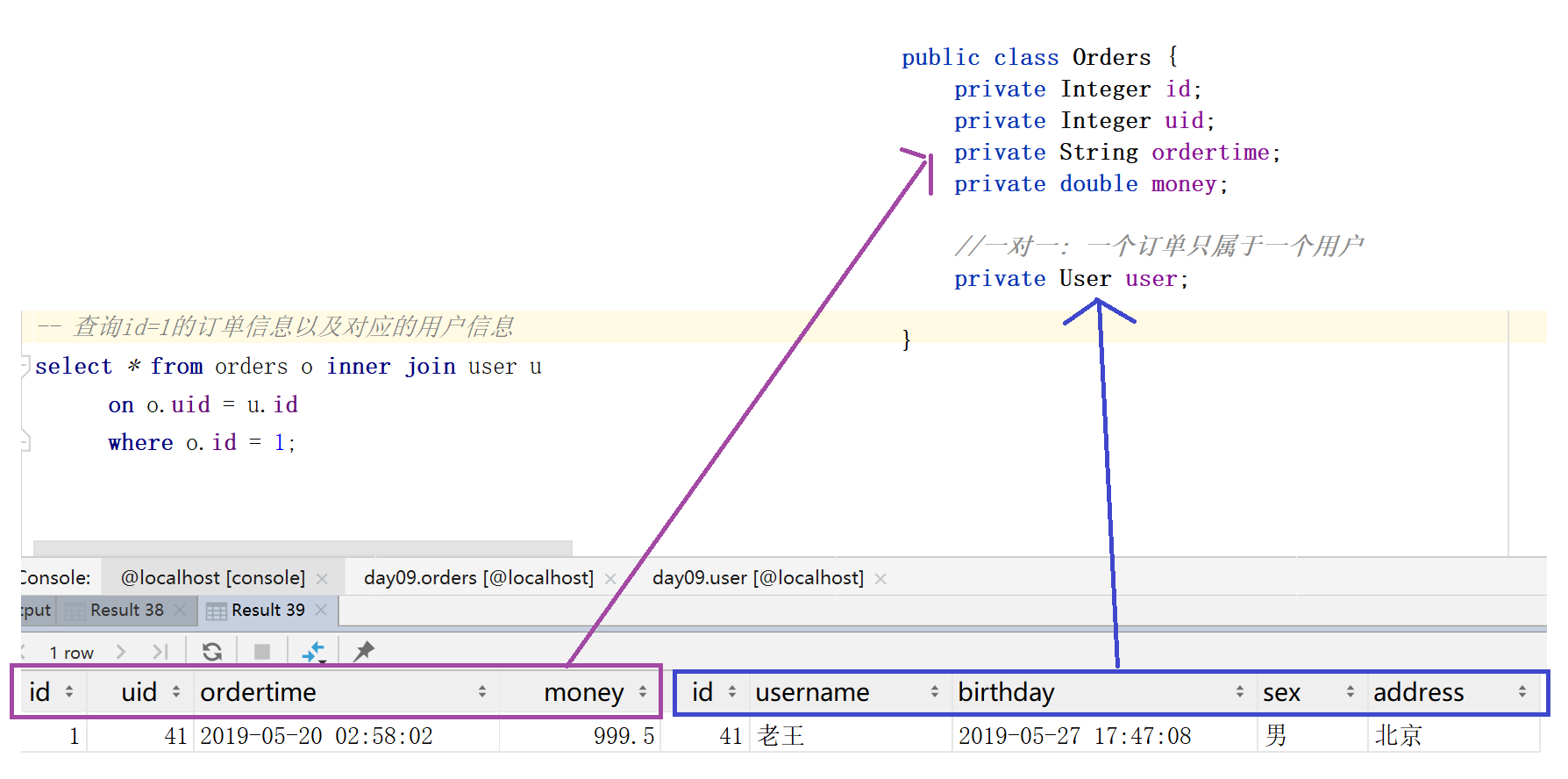
2.3 一对一
# mybatis的一对一
0. 需求:
1). 查询id=1的订单信息以及对应的用户信息
每个订单只属于一个用户(一对一)
2). sql :
select * from orders o inner join user u
on o.uid = u.id
where o.id = 1;
1. mybatis代码编写
1). 编写pojo
I. User类
II. Orders类 (重点)
2). 接口
Orders findOrderAndUserByOid(Integer oid);
3). sql映射文件
2. 练习: 查询所有的订单信息以及对应的用户信息
1). sql :
select * from orders o inner join user u
on o.uid = u.id;
2). 编写pojo
3). 接口
List<Orders> findOrdersAndUser();
4). sql映射文件
pojo
public class User {
private Integer id;
private String username;
private String birthday;
private String sex;
private String address;
// 省略get/get 和 toString方法,自己补上
}
public class Orders {
private Integer id;
private Integer uid;
private String ordertime;
private double money;
//一对一: 一个订单只属于一个用户
private User xx;
// 省略get/get 和 toString方法,自己补上
}
接口
public interface OrdersMapper {
/*
查询id=?的订单信息以及对应的用户信息
1). 参数: 订单编号
2). 返回值: 订单对象(内含下此订单的用户)
*/
Orders findOrderAndUserByOid(Integer oid);
List<Orders> findOrdersAndUser();
}
sql映射文件: ordersMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima01.dao.OrdersMapper">
<!--
TODO 结果集映射
1. 自动映射 : resultType
1). 前提: 结果集的字段名和pojo类的属性名一致
2). 单表查询时用
2. 手动映射 : resultMap
1). 手动建立 结果集字段和pojo类属性 之间的映射关系
2). 多表查询时用
resultMap标签:
子标签:
1). id子标签: 指定主键字段的映射关系
2). result子标签: 指定非主键字段的映射关系
column指的是结果集中的字段,符合最左匹配原则(如果结果集中有多个同名字段,优先用左边的那个)
property指的是pojo类的属性
匹配规则有个省略写法:
主键字段的映射必须要写,其他字段如果一致, autoMapping
3). association子标签 (关联)
property属性: 指的是当前pojo类的属性名
javaType属性: 此属性的类型
-->
<resultMap id="ordersMap" type="orders" autoMapping="true">
<id column="id" property="id"/>
<result column="uid" property="uid" />
<result column="ordertime" property="ordertime" />
<result column="money" property="money" />
<association property="xx" javaType="User" autoMapping="true">
<id column="uid" property="id"/>
<result column="username" property="username"/>
<result column="birthday" property="birthday"/>
</association>
</resultMap>
<select id="findOrderAndUserByOid" resultMap="ordersMap">
select * from orders o inner join user u
on o.uid = u.id
where o.id = #{oid};
</select>
<select id="findOrdersAndUser" resultMap="ordersMap">
select * from orders o inner join user u
on o.uid = u.id;
</select>
</mapper>
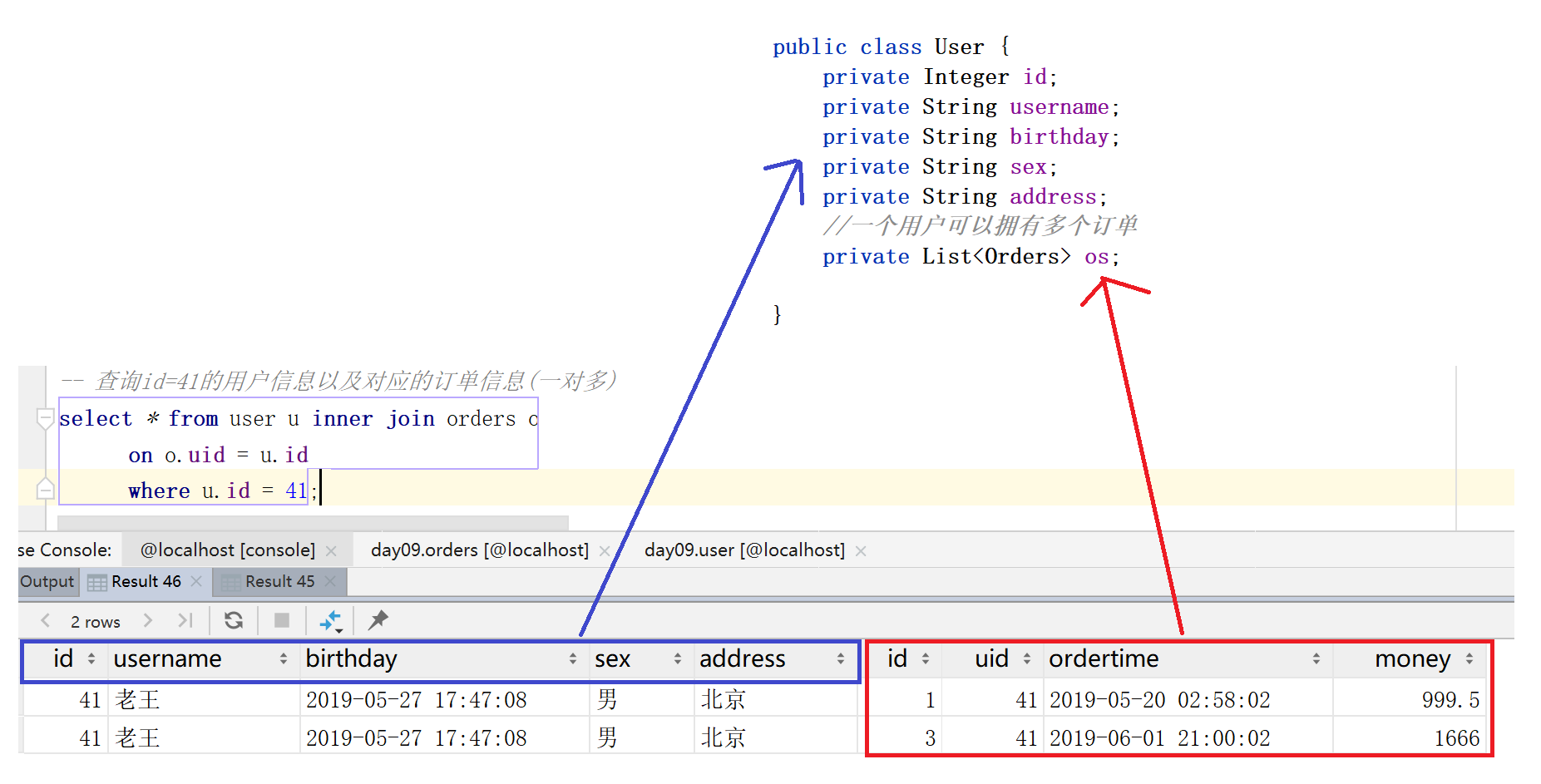
2.4 一对多
# mybatis的一对多
0. 需求:
1). 查询id=41的用户信息以及对应的订单信息(一对多)
一个用户可以下多个订单
2). sql :
select * from user u inner join orders o
on o.uid = u.id
where u.id = 41;
1. mybatis代码编写
1). 编写pojo
I. User类 (重点)
II. Orders类
2). 接口
3). sql映射文件
pojo类
public class User {
private Integer id;
private String username;
private String birthday;
private String sex;
private String address;
//一个用户可以拥有多个订单
private List<Orders> os;
//自己补上get/get和toString方法
}
接口
public interface UserMapper {
/*
查询id=?的用户信息以及对应的订单信息(一对多)
1. 参数: 用户编号
2. 返回值: 结果集映射的pojo对象
*/
User findUserAndOrdersByUid(Integer uid);
}
sql映射文件
userMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima01.dao.UserMapper">
<!--
resultMap
1). association子标签 : 一对一
2). collection子标签 : 一对多
I. property属性: pojo类集合的属性名
II. ofType属性: pojo类
-->
<resultMap id="userMap" type="user" autoMapping="true">
<id column="id" property="id"/>
<result column="username" property="username"/>
<collection property="os" ofType="orders" autoMapping="true">
<id column="oid" property="id"/>
<result column="money" property="money"/>
</collection>
</resultMap>
<select id="findUserAndOrdersByUid" resultMap="userMap">
select *,o.id oid from user u inner join orders o
on o.uid = u.id
where u.id = #{uid};
</select>
</mapper>
三. 注解配置
# 配置方式
1. properties文件
1). 配置语法: key=value
2). 解析: Properties类/ResouceBundle类
2. xml文件
1). 配置语法: 标签
2). 解析: sax/dom -> dom4j
3. 注解配置
1). 配置语法: @注解名(属性赋值)
2). 解析: 反射
# 框架
1. 底层设置配置方案的规范
1). properties
2). xml : xml约束
3). 注解 : 元注解(作用范围,生命周期), 属性
2. 底层将解析写好了
# 配置的作用: 解耦
将变化部分从框架底层代码中解耦出去, 让调用者去设置
# mybatis的配置
1. properties文件
jdbc.properties
2. xml文件
1). 写mybatis核心配置文件
2). 写myabtis的sql映射文件
3. 注解
1). 但凡可以xml配置的, 都可以注解来配置
2). 目前: 掌握单表的增删改查注解配置
多表的操作和动态sql用注解编写,阅读性太差,几乎不用
单表的增删改查
pojo类
public class User {
private Integer id;
private String username;
private String birthday;
private String sex;
private String address;
@Override
public String toString() {
return "User{" +
"id=" + id +
", username='" + username + '\'' +
", birthday='" + birthday + '\'' +
", sex='" + sex + '\'' +
", address='" + address + '\'' +
'}';
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getBirthday() {
return birthday;
}
public void setBirthday(String birthday) {
this.birthday = birthday;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}
接口
public interface UserMapper {
// @Select("select * from user")
List<User> findAllUsers();
/*
TODO: 单表的增删改查注解配置
1. 很方便
1). 此注解放在哪个方法上,注解中的sql就跟哪个方法关联
2). 此注解所在的方法返回值,默认自动映射
2. 注意
一个接口方法要么用xml配置,要么用注解配置,不可两者同时使用
3. 后续
1). 单表crud : 用注解配置 (方便)
2). 复杂sql : 用xml配置 (阅读性好)
I. 动态sql
II. 结果集手动映射
III. 多表操作
*/
// @Select(value = "select * from user where id = #{uid}")
@Select("select * from user where id = #{uid}")
User findUserById(Integer uid);
@Insert("insert into user values(null,#{username},#{birthday},#{sex},#{address})")
int addUser(User user);
@Update("update user set username=#{username},birthday=#{birthday},sex=#{sex},address=#{address} where id=#{id}")
int updateUserById(User user);
@Delete("delete from user where id = #{id}")
int deleteUserById(Integer id);
}
userMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima01.dao.UserMapper">
<select id="findAllUsers" resultType="user">
select * from user;
</select>
<!-- <select id="findUserById" resultType="user">
select * from user where id = #{uid};
</select>-->
</mapper>
操作
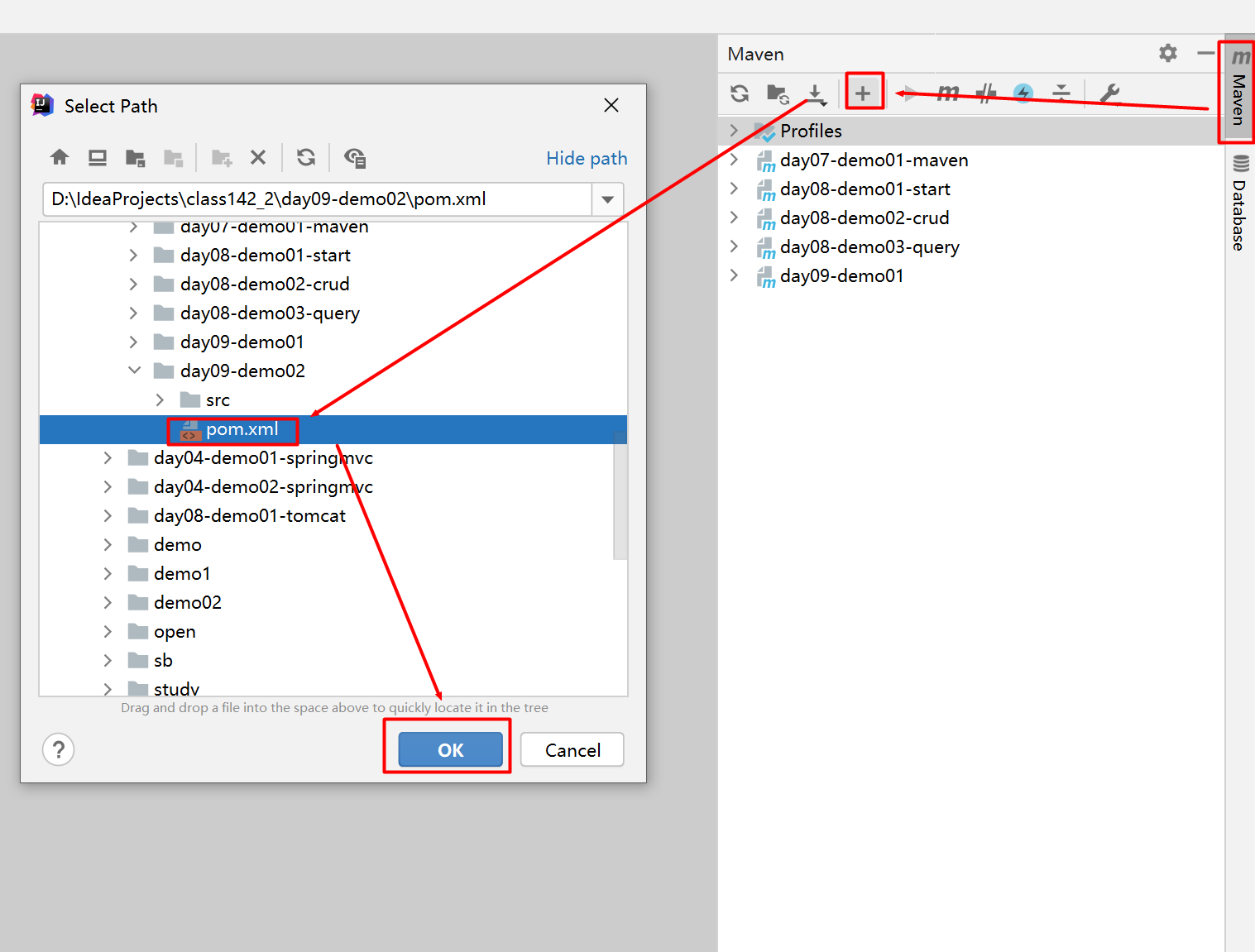
1. 复制maven工程
1. 把maven的模块复制到project下
2. 将此模块的内容进行删除: 只保留src文件夹和pom文件
3. 修改pom文件中的artifactId (跟模块文件夹名字一样)
4. 在idea中导入此模块

若有收获,就点个赞吧
0 人点赞
