Redis 是 Remote Dictionary Service(远程字典服务)的首字母缩写。
string(字符串)
Redis 的字符串是可以修改的字符串,内部实现类似于 Java 的 ArrayList,会预分配空间。
扩容机制为加倍扩容,超过1MB 最多扩容1MB。
最大长度512MB。
list(列表)
类似于 Java 的 LinkedList,它是双向链表而不是数组,意味着索引定位慢,插入删除相对快。
在列表元素较少的情况下,会使用一块连续的内存存储,结构是 ziplist,即压缩列表,省去了 prev 与 next。
当元素多时,再用双向指针把多个 ziplist 连接,组成了 quicklist。
这样既满足了快速插入删除的性能,又不会出现太大的空间冗余。
ziplist <-> ziplist <-> ziplist <-> ziplist <-> ziplist <-> ziplist
hash(字典)
类似于 Java 的 HashMap,也是数组与链表的结构,当 hash 在数组位置碰撞时,就会将该元素用链表连接。
不同的是,
Redis 的字典值只能是字符串!
rehash 的方式不同
- Java 的 HashMap 字典很大时比较耗时,会一次性全部 rehash。
- Redis 为了高性能,采用渐进式 rehash。
- 渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个 hash 结构,在后续的定时任务以及 hash 操作指令中,渐进地将旧内容一点点迁移到新结构中。
存储对象信息是用 Hash 还是 String
建议是大部分情况下使用 String 存储就好,毕竟在存储具有多层嵌套的对象时方便很多,占用的空间也比 Hash 小。当我们需要存储一个特别大的对象时,而且在大多数情况中只需要访问该对象少量的字段时,可以考虑使用 Hash,可以节约流量资源。
set(集合)
类似于 Java 的 HashSet,无序、唯一的键值对。
内部实现相当于特殊的字典,字典中所有的 value 都是 NULL。
zset(有序列表)
类似于 Java 的 SortedSet 和 HashMap 的结合。
value 唯一,每个 value 有一个 score,代表排序权重。
内部实现是 跳跃列表 的结构。
skiplist 跳跃列表
基本结构
zset 需要支持随机插入和删除,所以不宜使用数组来实现,
需要一个 hash 结构来存储 value 与 score,
需要按照 score 进行排序,这意味着有新元素插入时,要定位插入点,
需要能够指定 score 的范围来获取 value 列表
这里就要 skiplist 来实现。
下图只有4层,redis 的跳跃表共有64层
所有的 kv 包括 kvheader 都是下面的结构:
struct zslnode {string value;double score;zslnode*[] forwards; // 多层连接指针zslnode* backward; // 回溯指针}
跳跃表:
struct zsl {zslnode* header; // 跳跃列表头指针int maxLevel; // 跳跃列表当前的最高层map<string, zslnode*> ht; // hash 结构的所有键值对}
kv 之间通过指针形成双向链表,它们是有序的从小到大。
forwards 有多少元素,代表着该 kv 有多少层,
同一层的 kv 通过指针相连,每一层元素的遍历都是从 kvheader 出发。(kvheader的 score 为 Double.MIN_VALUE,最小)
查找过程
如果跳跃列表只有一层,插入、删除操作需要定位的复杂度是 O(n),有了多层结构后为 O(lg(n))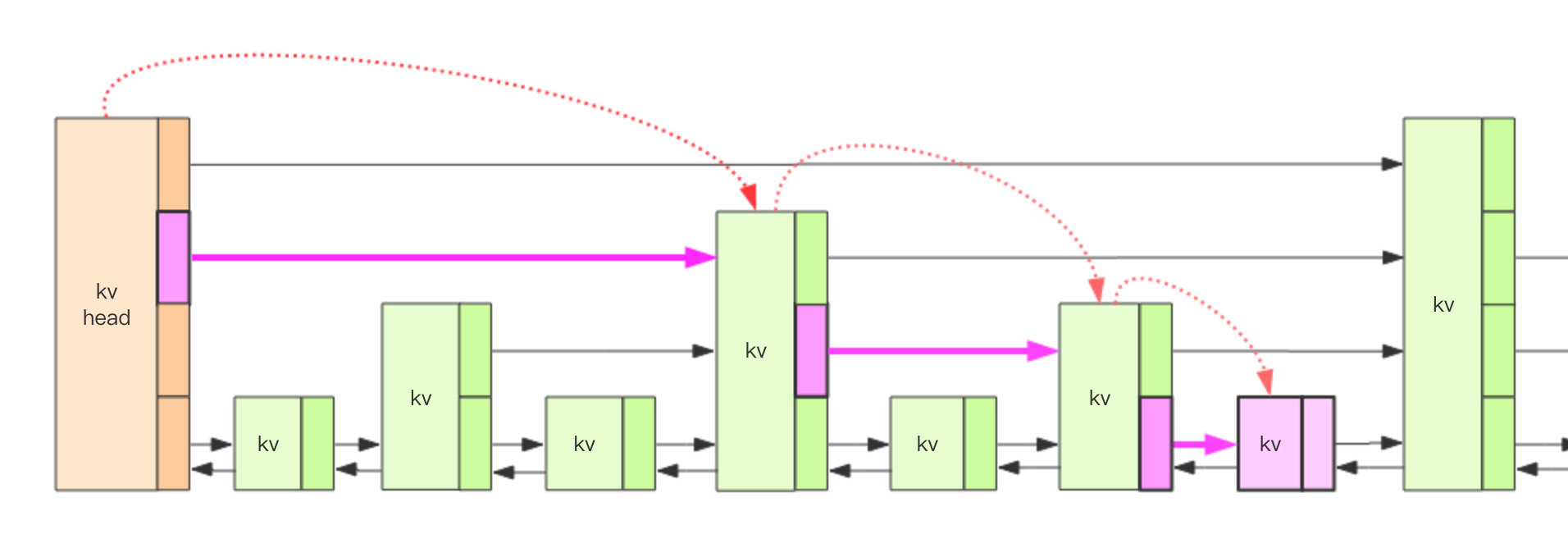
随机层数
对于每一个新节点,都要调用一个随机算法给它分配一个合理的层数。
Redis 标准源码中晋升率只有25%,这样层高相对较低,跳跃列表会记录一个 maxLevel,每次从此层开始遍历
插入过程
找出”搜索路径”,
创建新节点,随机分配层数,再将搜索路径上的节点和这个新节点通过前后指针串起来。
如果分配的高度大于最大高度,更新最大高度。
删除过程
找出”搜索路径”,
对每个层的相关节点更新一下前后指针,
根据情况更新最高层数。
更新过程
调用 zadd 方法时,如果对应 value 不存在,就是插入过程,存在就是更新一下 score 的值。
如果更新后 score 的值不影响排序,那么只更改 score 值,
如果影响排序,那么调整位置,
redis 是 先删除这个元素,再插入这个元素。
元素相同
元素排名如何计算
Redis 给每一个 forward 指针都增加了 span 属性,表示从前一个节点沿着当前层的指针跳到该节点中间有多少节点。Redis 在插入、删除操作时都会更新 span 值的大小。
struct zslforward {
zslnode* item;
long span; // 跨度
}
struct zsl {
String value;
double score;
zslforward*[] forwards; // 多层连接指针
zslnode* backward; // 回溯指针
}
这样只需要将”搜索路径”的所有节点的 span 相加,就可以得出该元素的 rank 值。
容器性数据结构通用规则
list、set、hash、zset 都是容器型数据结构,具有一下通用规则:

若有收获,就点个赞吧
0 人点赞
