目标:
1:掌握怎么把Chrome以及firefox浏览器设置为无头模式!
2:掌握selenium打开的浏览器怎么执行javascript脚本
3:利用selenium配合浏览器抓取数据的注意事项
一:怎么把Chrome以及firefox浏览器设置为无头模式!
为什么要设置为无头浏览器?
答:无头浏览器性能更好一些,可以在不打开浏览器窗口的情况下进行数据的抓取
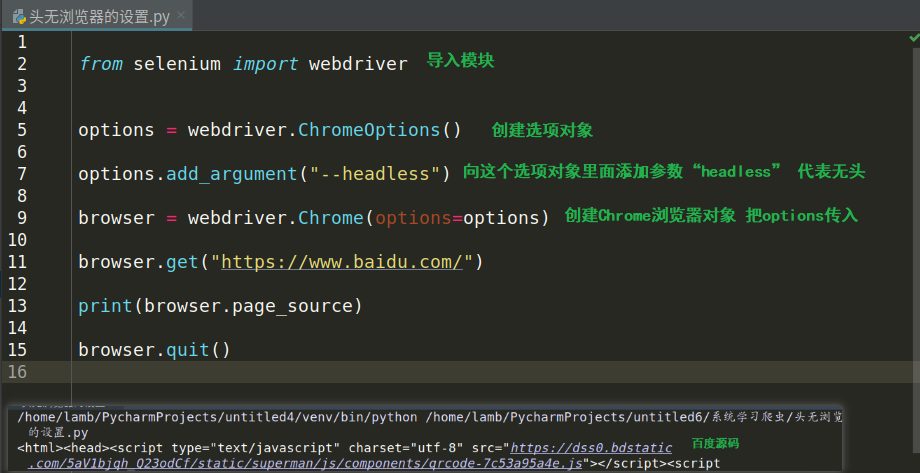
设置语法:
from selenium import webdriver 导入模块
options = webdriver.ChromeOptions( ) 创建选项对象,注意ChromeOptions( ) 中的O是大写
options.add_argument(“—headless”) 向这个选项对象中添加“headless”参数,代表无头
Browser = webdriver.Chrome(options = options) 创建浏览器时,将设置好的options参数传入
图示:
二:selenium打开的浏览器怎么执行javascript脚本
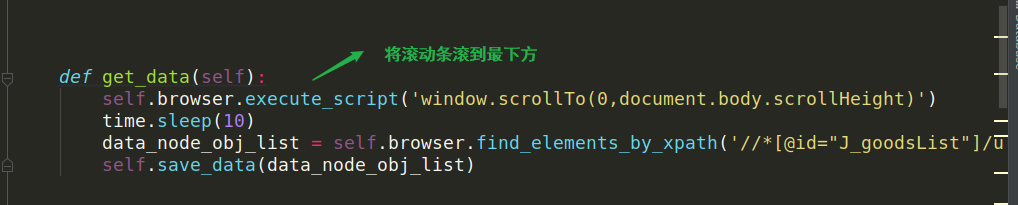
语法:浏览器对象.excute_script(“javascript脚本代码)
实例:browser.excute_script ( “ window.scrollTo (0,document.body.scrollHeight )” )
浏览器执行 window.scrollTo (0,document.body.scrollHeight)这段javascript代码,将滚动条滚到最下方
图示:
三:selenium配合浏览器抓取数据的注意事项
1:执行网站换页操作时,如果网站有输入第几页跳转,尽量用那个进行换页,因为如果程序在某一页报错,可以很容易知道在那一页报错

2:抓取动态网页时,浏览器对象需要执行javascript脚本代码(将滚轮滑到最底部!)
3:利用find_enements_by_xpath抓取的结点对象集合,然后再循环遍历,调用结点的text属性,获取当前节点以及后代节点的所有文本数据,如果数据不容易被处理,可以在当前节点下调用find_enement_by_xpath方法,在查找具体的数据结点,然后调用text属性获取数据!!

4:如果在前端页面源码内复制结点的xpath查找不到数据!!!!,记得要自己在写一下xpath语句试一试

若有收获,就点个赞吧
0 人点赞
