目标:
1:掌握多进程以及多线程的适用场景
2:掌握创建多线程的步骤以及常用语法
3:掌握多线程爬虫的工作原理
4:掌握Python中队列的一些操作!
5:掌握多线程对全局变量加线程锁的目的
一:多进程以及多线程的适用场景
多进程适用场景:计算机密集型的操作(CPU密集型),比如说计算大量数据时,多进程可以保证同一时间多个进程同时工作,就是比较消耗内存
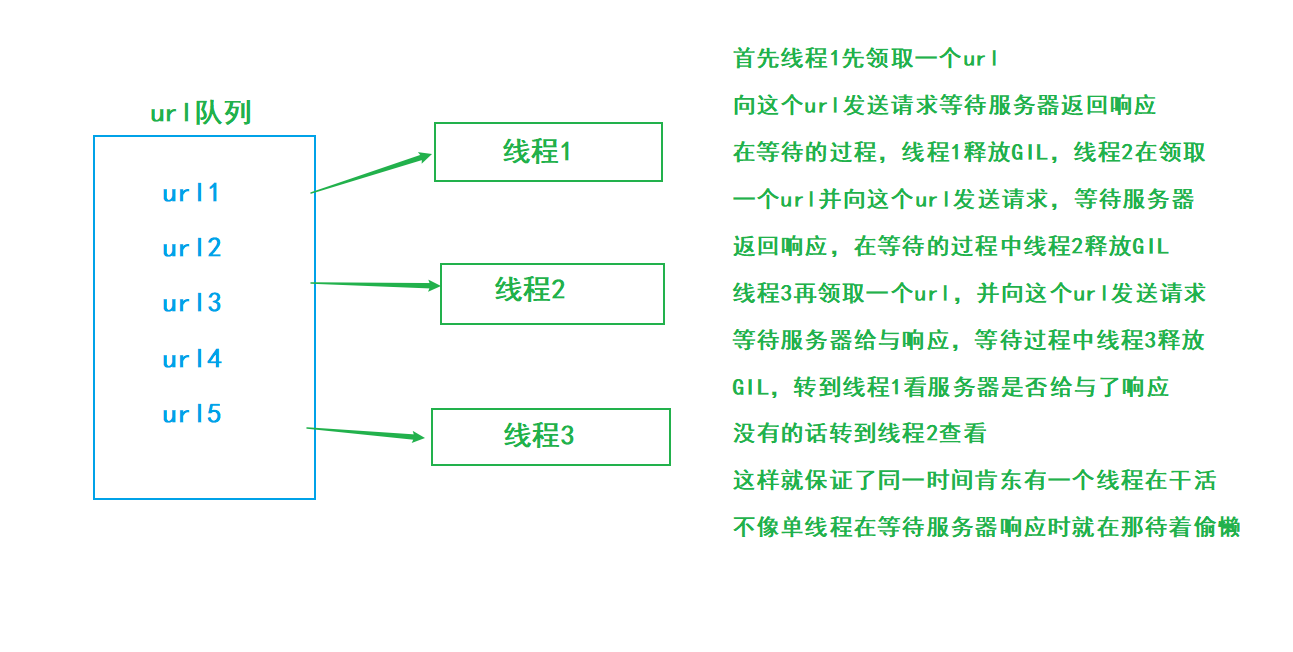
多线程适用场景:I/O密集型操作,比如说网络I/O、本地磁盘I/O,爬虫就是网络I/O与本地磁盘I/O(存储数据)结合体,多线程因为GIL的存在同一时间只能保证有一个线程在工作,但是也能保证同意时间肯定有一个线程在工作
二:创建多线程的步骤以及常用语法
步骤:
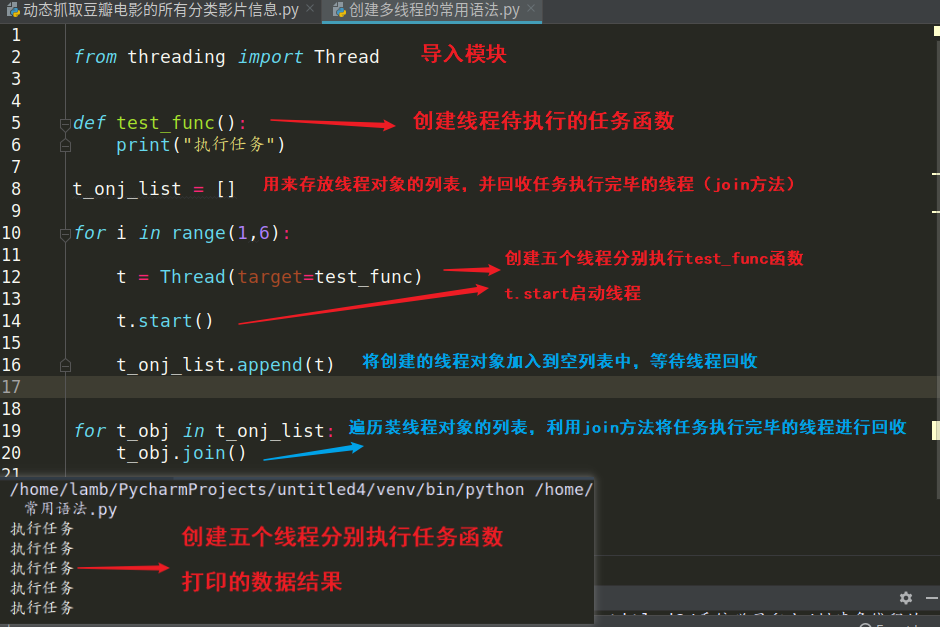
第一步:from threading import Thread 导入模块
第二步:t = Thread(target=任务函数名,args=()) 创建线程对象 args = (),是元组给任务函数传参,相当于位置传参
第三步:t.start() 启动线程
第四步:time.sleep(1) 等待线程任务执行完毕
第五步:t.join() 当 t 线程任务执行结束后 回收 t 这个线程(防止死线程的产生)
注意事项:
1:join()方法功能是等待创建的某线程执行任务函数结束后进行线程的回收
2:利用join 方法时程序会进入阻塞状态,回收完执行任务完毕的线程后才解除阻塞!
常用建立多线程语法截图
三:多线程爬虫的工作原理
四:Python中队列的一些操作【数据存入、取出、取数据阻塞等问题】!
队列存入数据的优先级:队列中的数据是先进先出,从队尾进入,队首取出
操作队列的步骤:
第一步:from queue import Queue 导入队列模块
第二步:q = Queue() 创建q这个队列
第三步:q.put(存入队列的数据) 向q这个队列存入数据
第四步:q.get() 从q这个队列中取出存入的数据
第五步:q.empty() 判断队列中数据是否为空,是返回True,不是返回False
队列取数据出现的问题:当利用 get 方法从队列中取数据时,队列数据为空,那么程序就会进入阻塞状态,有什么办法让程序不阻塞嘛?
解决办法:
1:q.get(timeout=2) 设置阻塞时间,当超过两秒钟还未从队列中取得数据,程序直接报错
2:q.get(block=False) 在队列取不到数据直接报错,block默认值为True,也就是取不到数据程序一直处于阻塞状态
3:q.get_nowait() 利用get_nowait方法取数据,队列内没有数据直接报错!!
4:while not q.empty( ): 判断队列内是否有数据,有数据才取,没数据不取
q.get( )
五:多线程对全局变量加线程锁的目的以及加锁步骤
加线程锁目的:多个线程共享(共同操作)一个全局变量时(全局文件变量、全局变量、全局队列变量),可能会产生资源竞争问题,这时就要对全局变量进行加线程锁,等一个线程对全局变量操作完全结束后,在进行线程锁的释放!,可避免多线程间资源的竞争
加线程锁步骤:
第一步: from threading import Lock 导入线程锁模块
第二步:l_obj = Lock() 创建一个线程锁
第三步:l_obj.acquire( ) 某一个线程在对全局变量操作之前进行加锁
第四步:l_obj.release() 某一个线程在对全局变量操作完全结束后进行开锁
注意事项:对某个全局变量上线程锁,在线程锁未开锁之前,又给这个全局变量上了一把锁,这是程序会进入阻塞状态
图示:
不加线程锁造成的多线程间资源竞争问题
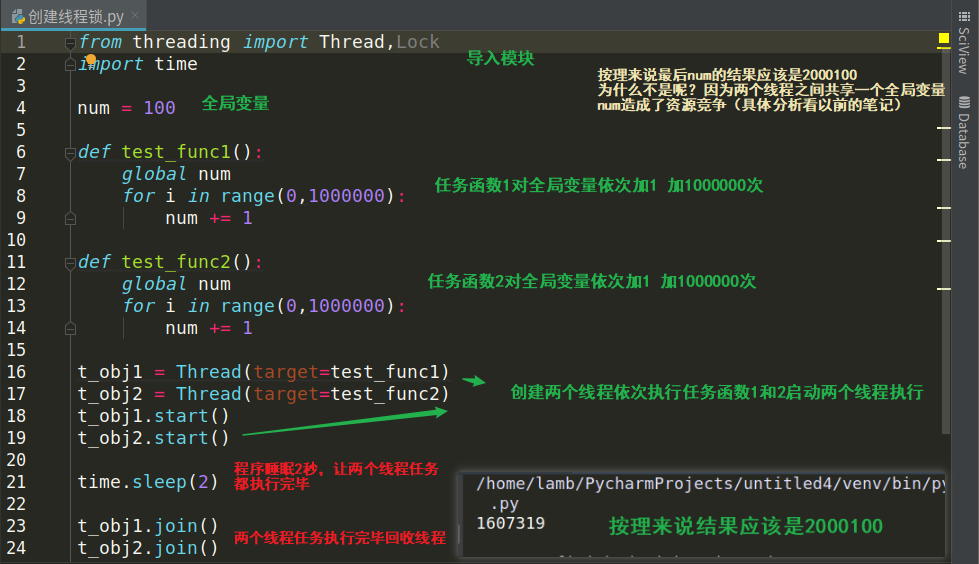
加线程锁解决多线程之间的资源竞争

多线程爬虫共同操作全局变量【同一个资源】(文件变量、队列变量等)的注意事项:只要是线程对全局变量(同一个资源)进行了操作都要加上一把线程锁!!!
注意事项:全局变量(全局队列等)有几个,那么就要创建几把线程锁

若有收获,就点个赞吧
0 人点赞
