目标:
1:掌握正则模块 re 抓取数据的两种方法形式
2:掌握正则模块 re 方法的 re.S参数的作用
3:掌握正则表达式贪婪模式以及非贪婪模式的注意事项
4:掌握正则表达式单个分组以及多个分组的用法
一:正则模块 re 抓取数据的两种方法形式
第一种形式(直接使用findall(查找数据)方法):
data_list = re.findall(正则表达式,待匹配字符串,re.S)
第二种形式(先创建正则编译对象在调用findall等方法):
pattern = re.compile(正则表达式,re.S)
data_list = pattern.findall(待匹配字符串)
注意事项:一般大佬都用第二种形式,因为正则写好一个可以多次调用
图示:

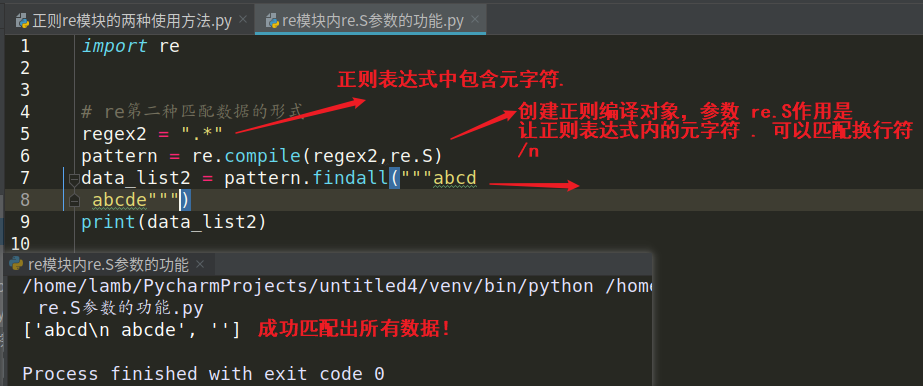
二:正则模块 re 方法的 re.S参数的作用
作用:正则表达式中的元字符 . 可以匹配任意字符(除了换行符/n),在findall等方法内部加上参数re.S后 元字符 . 就可以匹配换行符/n啦
注意:在抓取 html 代码时一定不要忘记写 re.S参数,因为 html 代码有很多换行符
图示:
三:正则表达式贪婪模式以及非贪婪模式的注意事项
元字符 ?功能: ? 前一个字符出现1次或者0次
贪婪模式:在满足匹配规则的前提下尽可能多的匹配数据
非贪婪模式:在满足匹配规则的前提下尽可能少的匹配数据
注意事项:
1:贪婪模式与非贪婪模式说的都是在匹配多个字符时才适用,即元字符 + ?
2:python程序默认是贪婪模式匹配数据
3:在匹配多个数据的元字符( +?)后面加上 ? 就可将贪婪模式转变为非贪婪模式,注意一定是在匹配多个元字符后面加才管用!!!
四:正则表达式单个分组以及多个分组的用法
用法【单个分组】:如果在正则表达式的一部分加上单个分组,也就是一个() 那么在调用 findall方法时,只将符合分组内的数据提取到列表内!
用法【多个分组】:如果在正则表达式的一部分加上多个分组,也就是多个() 那么在调用 findall方法时,将符合多个分组内的数据先保存到一个元组内,然后在匹配其他符合分组的数据,再次存放到另一个元组内,然后在将多个元组存放至列表中【列表内嵌套元组】
图示【单个分组】 【多个分组】:


若有收获,就点个赞吧
0 人点赞
