爬虫工程师基础
白天
夜间
首页
下载
阅读记录
书签管理
我的书签
添加书签
移除书签
爬取民政部行政区号遇到的反爬【目标】
浏览
176
扫码
分享
2023-11-23 19:57:10
重点:掌握在爬取民政部行政区号遇到的反爬怎么解决
一:爬取民政部行政区号遇到了怎样的反爬
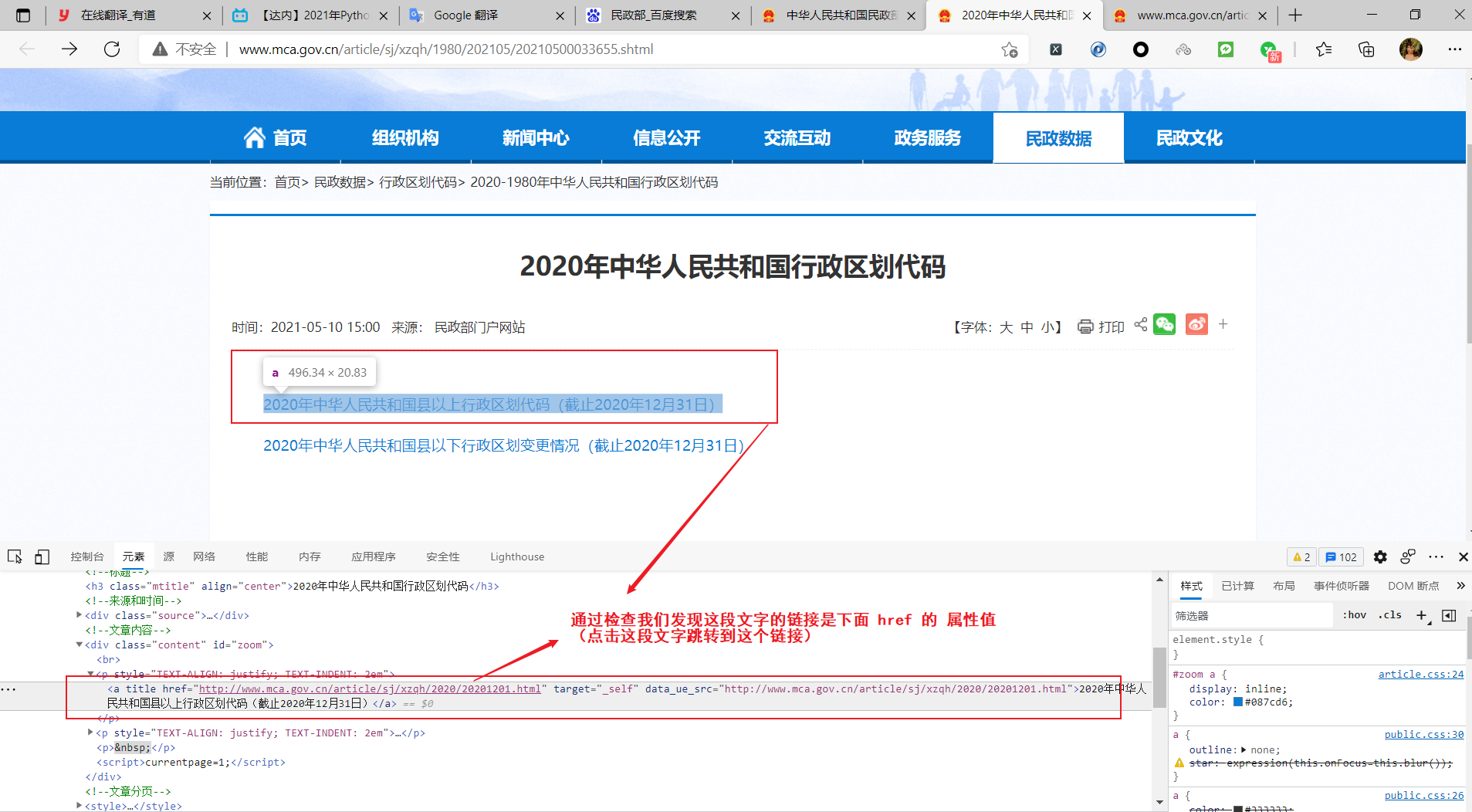
检查发现还他娘真有这段js跳转脚本代码
若有收获,就点个赞吧
0 人点赞
上一篇:
下一篇:
孜孜以求
什么是爬虫及其分类!
爬虫爬取数据的步骤!
urllib.request库的方法及功能【重点】
urllib.parse模块的方法功能解析【重点】
简单爬虫的构架【重点】
正则模块(re)的使用【重点】
正则表达式匹配 html 数据的技巧【重点】
爬取数据持久化存储(csv)【重点】
数据持久化存储(mysql)【重点】
mongoDB 数据库基本操作1【重点】
mongoDB数据库基本操作2【重点】
数据持久化存储(mongodb)【重点】
random模块的uniform方法【重点】
简单的二级爬虫框架【重点】
精进不休
MySQL实现增量式爬虫(md5加密)【重点】
MySQL增量式爬虫框架【重点】
redis数据库基本操作【重点】
redis数据库的常用指令【重点】
redis数据库与python交互【重点】
redis实现增量爬虫【重点】
requests模块的使用【重点】
requests模块抓取图片、视频等【重点】
User-Agent库随机生成用户代理【重点】
安装爬虫相关的浏览器插件【重点】
xpath语法详解【重点】
lxml库搭配xpath语法实现数据提取【重点】
requests模块的高级参数【重点】
代理IP的使用【重点】
搭建IP代理池【重点】
requests的post请求【重中之重】
关于js加密【重中之重】
爬取民政部行政区号遇到的反爬【目标】
字符串、列表、字典之间的相互转化【重点】
精益求精
爬取动态网页的操作流程!【重中之重】
爬取动态网页【重中之重】
json解析模块的使用【重中之重】
多线程爬虫1【重中之重重】
单级页面的多线程爬虫框架【重中之重】
多级页面的多线程爬虫框架【重中之重】
Cookie模拟登陆【重点】
selenium环境安装【重点】
selenium应用1【重点】
selenium高级应用1【重中之重】
selenium高级应用2【重中之重】
selenium高级操作3【重中之重】
初识Scrapy框架【重中之重、面试】
白话释义
刮骨去毒
获取响应数据出现编码的问题
向网站服务器发送请求时错误(捕获异常)【网络问题】
写正则的技巧【重中之重】
字符串、列表、字典之间的相互转化【重点】
暂无相关搜索结果!
让时间为你证明
分享,让知识传承更久远
×
文章二维码
×
手机扫一扫,轻松掌上读
文档下载
×
请下载您需要的格式的文档,随时随地,享受汲取知识的乐趣!
PDF
文档
EPUB
文档
MOBI
文档
书签列表
×
阅读记录
×
阅读进度:
0.00%
(
0/0
)
重置阅读进度
×
思维导图备注