目标:
1:掌握 python 的第三方库 lxml 搭配 xpath 语法在 html 文档内提取数据的使用方法!
2:掌握for 循环的另外一种用法以及怎么将列表内元素拼接为一个字符串
一:python 的第三方库 lxml 搭配 xpath 语法在 html 文档内提取数据的使用方法!
lxml库功能:与 xpath 语法搭配使用从而在 html 或者 xml 文档中提取出自己想要的数据
lxml库安装(unubtu):pip3 install lxml
lxml库在html文档代码内提取数据使用步骤:
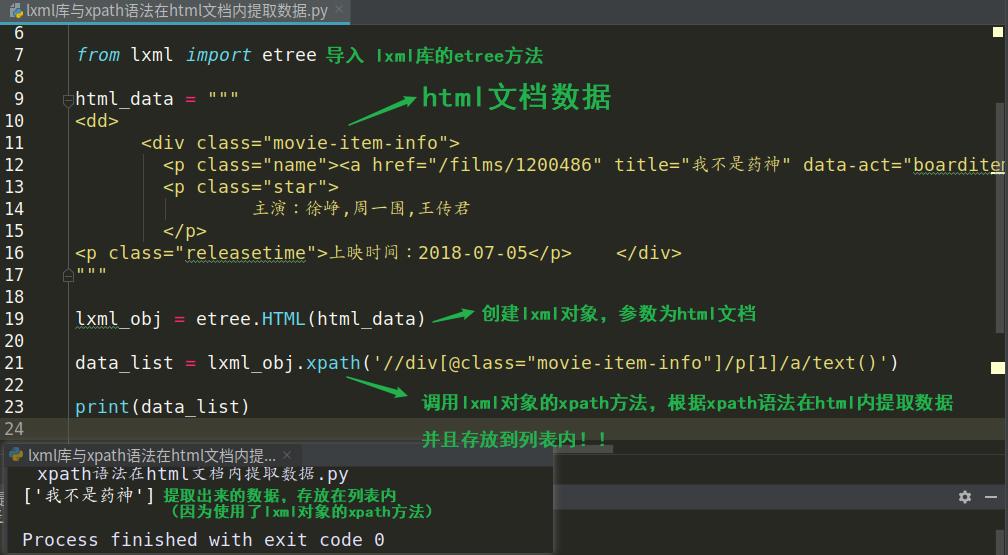
from lxml import etree 导入模块
lxml_obj = etree.HTML( 网页的html源代码 ) 创建 lxml 对象用于提取数据
data_list = lxml_obj.xpath(xpath语法) 利用 xpath 语法从网页的html源代码中提取数据
lxml库搭配xpath语法在html文档中提取数据(电影、汽车等)最常用法如下:
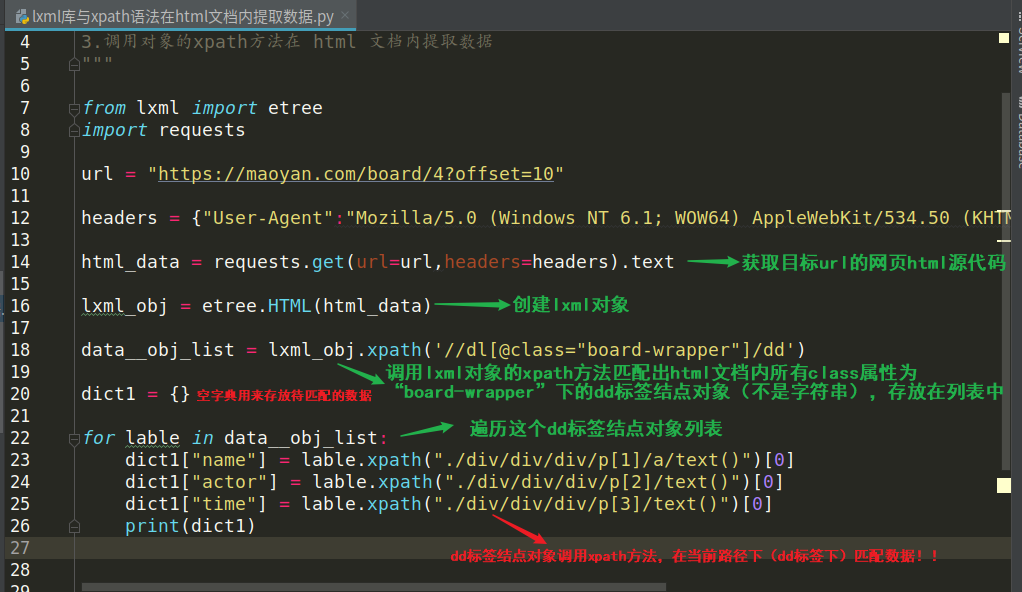
from lxml import etree 导入模块
lxml_obj = etree.HTML( 网页的html源代码 ) 创建 lxml 对象用于提取数据
lable_obj_list = lxml_obj.xpath(xpath语法) 利用 xpath 语法从网页的html 源代码中 提取 数据存在的 标签结点对象
for lable in data_list: for循环遍历这个标签结点对象
data_list = lable.xpath(xpath语法) 调用这个标签结点对象的xpath方法,在当前路径下匹配数据
print(data_list) 打印数据
注意事项:
1:只要lxml 对象调用了 xpath 方法,那么获取的数据类型一定是列表!!!!
2:在 html 文档中提取数据最常用法中通过 for 循环遍历数据结点对象里面那个xpath语法(第二个xpath)开头要以 . 开头,表示在当前标签结点下查找标签数据!
代码体验(提取数据使用步骤):
————————————————————————————————————————————
最常用法截图:
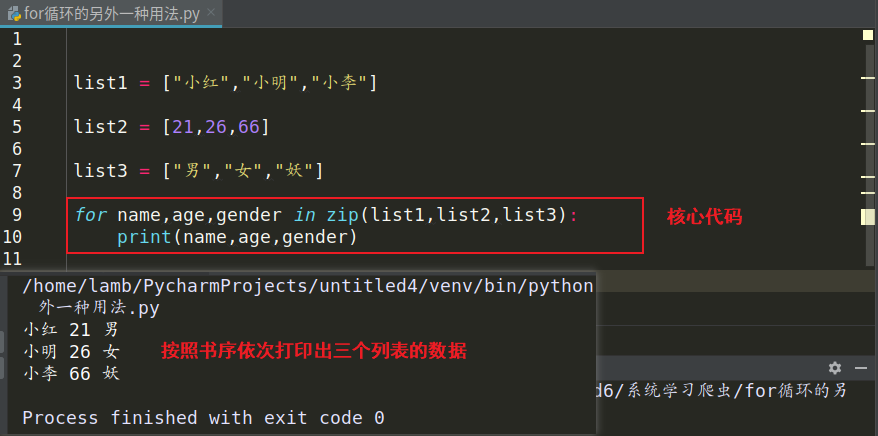
二:for 循环的另外一种用法以及怎么将列表内元素拼接为一个字符串
for循环的另外一种用法(截图):
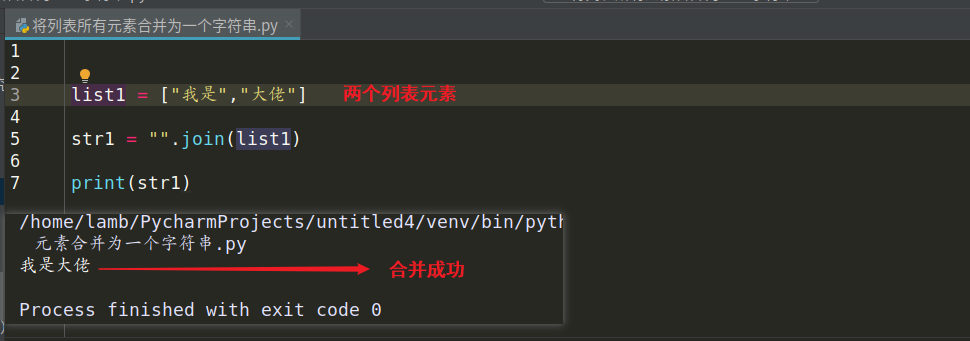
将列表所有元素合并为一个字符串:
语法:“”. join(待合并元素的列表)
截图:

若有收获,就点个赞吧
0 人点赞
