随着程序开发,代码会越积越多,有些能写成函数被复用,有些则散落在各个角落。
但如果只用一个文件来保存这些代码,我们会陷于混乱,最后可能连你自己都无法准确描述代码功能。
我们需要一种比函数粒度更大的代码隔离方法,就是模块(Module)。
有了模块,我们就能把代码分门别类存储于不同的文件,需要的时候就可以引入使用。
比如,Python内置了很多常用的标准模块,之前我们接触过一些:
- math:数学计算模块
- os/pathlib/shutil:操作系统和文件管理模块
- random:伪随机模块
- string:字符串处理模块
Python标准模块还有300多个,适用于不同工作需要。
我们不必记住全部模块,当遇到问题时,用搜索来学习。
第三方模块,指Python标准模块之外的模块。
任何人都可以创造自己的Python模块,按PyPi要求格式打包好后上传,这样别人就能用pip命令安装你的模块。
我们之前使用的pillow模块就是由三方开发人员提供的模块。
不管是标准模块还是三方模块,只要被安装在Python中,就能用import语句引用它们。
模块,让我们可以更大粒度地组织管理和共享代码。
本节主要内容:
- 模块和包:代码组织管理方式
- 模块使用:变量作用域
- 如何快速掌握新模块
- 有哪些实用模块
1、模块和包
在Python中,一个.py文件就是一个模块,比如abc.py文件对应的模块名就是abc。
如果有同名文件出现,可以用包(Package)来组织模块,Python中的包就是层级目录结构,目录中包含一个特殊的文件:__init__.py。
比如,你可以这样组织你的代码: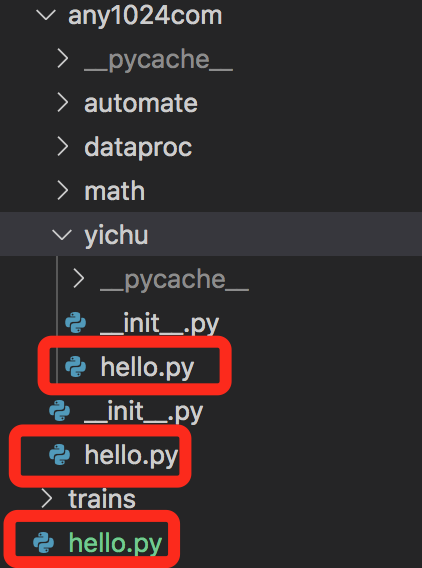
不同目录中的文件,哪怕名字一样,也是不同的模块。
其中__init__.py可以是个空文件,里面不含任何内容,但文件夹下必须有这个文件,表示该文件夹是包的一部分。比如上图中:
- 第1个hello.py属于any1024com.yichu包下。
- 第2个hello.py属于any1024com包下。
- 第3个hello.py不属于任何包,是一个独立的脚本。
你可以按上图组织文件结构,分别在两个hello.py文件中定义同一个函数,输出不同内容,然后在any1024com目录之外建一个Python脚本测试使用。比如:
any1024com > yichu > hello.py:
# coding=utf-8def hello():"""some notes"""print('Hello Python!')
any1024com > hello.py:
# coding=utf-8def hello():"""some notes"""print('Hello World!')
然后在最外层文件夹创建hello.py脚本测试:
# coding=utf-8from any1024com.yichu import hellofrom any1024com import hello as Hellohello.hello() # Hello Python!Hello.hello() # Hello World!
2、模块使用
在前面章节我们已经知道,通过import语句可以引入模块:
import math # 引入整个模块from math import sqrt, pi # 引入模块中的某个函数或常量from math import * # 把模块内所有函数和常量都引入进来from math import pi as PI # 引入后改名
引入后,我们就可以在代码中使用它们了。
导入模块时,Python解析器会依次从多个路径寻找模块,可以通过sys标准模块查看当前Python环境中有哪些模块路径。
import syssys.path
返回结果是一个list,元素从前到后,就是当前Python解析器寻找的路径顺序。所以你可以完全可以用列表的append()往里面添加寻找的路径,或者调整顺序,以此改变一些模块的优先级。或者也可以通过修改操作系统PYTHONPATH环境变量调整模块搜寻优先级。
但一般情况下不建议这样动态修改python的路径,会让调试更加复杂。 通过pip安装的包都会包含在Python安装目录下的site-packages下,已包含在搜索范围。
sys标准模块代表当前的Python运行环境,比如你可以通过它查看当前递归层级的最大极限,并可以设置极限值:
sys.getrecursionlimit()sys.setrecursionlimit(1000)
在使用模块时,虽然我们每次用类似from math import *这样的形式,很方便引入模块所有函数,但这样也可能引起难以察觉的问题。
比如你自己定义了一个平方根的函数sqrt(),结果因为引入math模块下所有的函数,不小心把自己的函数覆盖了。
def sqrt(n):"""平方根"""return int(n**0.5)print(sqrt(8)) # 2from math import *print(sqrt(8)) # 2.8284271247461903
也许你只想引入一个pi常量或者其他函数,却并不知道math模块下有一个和你一样名字的sqrt()函数,结果出现了预想不到的错误。这就会给你增加额外的错误排查成本。
所以,引入模块时建议按“够用”原则,即不引入不必要的内容。具体使用顺序如:
import math,直接引入模块,因为模块重名可能性更小些。from math import sqrt, pi,当某个函数或常量经常被调用,可以直接引入。from math import pi as PI,引入时如果和函数或变量重名,则可以用as给引入的函数一个别名。from math import *,当你仅仅想快速测试下某个功能时可以“偷懒”,其他任何时候不建议用。
有两个模块比较有意思,在交互式环境中import之后就会有反应:
import this:出来的就是Python之禅(The Zen of Python)了。import antigravity:会用浏览器打开一个Python的漫画网站。
3、如何快速掌握新模块
Python模块有很多,除了300多个标准模块外,PyPi上目前有20多万项目,没有人能掌握所有模块。

但就像定位错误一样,我们得掌握一套方法,快速找到适用模块并学会它。
遇到问题,我们首先要考虑的,还是那句话:“你不是第一个遇到问题的。”
所以,很多时候,我们并不需要从零开始,也就是俗称的DRY(Don’t Repeat Yourself)原则。
我们可以先去搜索引擎寻找答案,看看有没有人遇到过同类的问题,带着问题观察:
- 他们是如何解决同类问题的?
- 他们用到了哪些函数或者模块?
- 这些已有的模块运行效果如何?
- 判断:它们能否解决你的问题?
当你感觉这个模块可能就是你想要的时候,就开始去接触了解它,方式有两种:
- 通过搜索引擎查找使用过的人
- 从模块开发作者的官方主页开始了解
第一种方法,对于那些比较成熟的模块非常有效,可以快速从别人的使用经验中获得帮助。
比如,搜索关键词:python pillow 使用,你就会看到一堆别人使用pillow模块时留下的经验笔记,以及一些三方的教程。
第二种方法,更通用,适用于所有模块。因为模块开发作者一般都会把使用说明专门放在网页上供人参考,常见的比如github、readthedocs。你可以用关键词和站点过滤快速搜索到官方介绍。如:
pillow 官网 site:github.com、pillow 官网 site:readthedocs.io。
找到官方介绍后,一般可以按下面的顺序开始了解:
- 阅读Readme,这也是大部分Github项目的首页,在这里你可以对模块有个通用了解,比如创建它的背景、它的功能、适用范围、安装配置说明、使用手册地址等等。
- 大概浏览完后,就可以按着它的安装配置说明,着手安装模块,对于大部分模块,安装比较容易,
pip命令即可搞定。对于一些需要依赖操作系统支持的模块,比如视频处理等,则需要安装一些额外的软件包。 - 安装完成后,可以先运行官方提供的样本代码,由此观察自己是否安装成功。如果有
Example章节,也可以运行多几个样例,看看效果。 - 体验过后,就可以开始跟着学习,找找看有没有提供
Quickstart或Tutorial的章节,那里就是官方提供的标准教程了。跟着里面的说明练习即可。 - 开始尝试自己建立一些小项目练习时,可以通过
Reference章节来找到具体函数的用法,相当于查词典。 - 此外,在练习时,也可以通过搜索引擎去看看有没有其他人也学过这个模块,找找经验笔记,可以帮助加速学习过程。
当你发现想用的某个模块,并没有提供官方指引,怎么办?
- 大部分Python项目,都是可以直接查看源代码的,甚至有时候读代码会比读文档更快更清楚。
- 用搜索引擎在论坛上搜索有没有相关资料。
- 尝试联系作者,比如在Github上留言,或者发邮件等。一般很少会用到这一步,优秀的项目代码从不缺文档,没文档的代码很少会好用。
4、实用的模块
Python提供的标准模块中,除了之前提到的,常用的还有:
- datetime:时间处理
- collections:集合处理,在内置数据类型基础上扩充了不少
- base64:用64个字符来表示任意二进制数据的方法,比如一幅图片
- json:json数据格式处理
- hashlib:常用摘要算法,比如MD5,SHA1等
- itertools:生成通用对象的迭代
- re:正则表达式
- csv:csv文件读写
- threading:多线程处理
- logging:日志处理
此外还有一些常用的三方模块:
- pillow:图形图像处理
- PyPDF2:PDF文件处理
- openpyxl:
.xlsx文件处理 - python-pptx:
.pptx文件处理 - python-docx:
.docx文件处理 - moviepy:视频剪辑处理
- requests:互联网URL资源处理
- scrapy:通用爬虫框架
- mitmproxy:网络请求监听处理
- lxml:解析HTML和XML
- pyppeteer:浏览器驱动框架
- jieba:中文分词
- django:Web开发框架
- numpy:科学计算,尤其适合矩阵计算
- scipy:基于numpy提供更多高阶抽象和物理模型
- sympy:数学符号运算,比如求解多项式
- pandas:高效数据分析工具
- matplotlib:绘图工具,常配合数据分析后的可视化
- celery:异步执行框架
总结
本文主要介绍了Python的模块和包,它们是辅助代码隔离的管理工具。
在正式使用模块时,需要注意方式,保持“够用”原则。
Python生态的模块非常丰富,重点不是记住有多少模块,而是掌握了快速新模块学习能力。
最后,Python的应用非常广泛,根据不同应用类型,可以有很多优质的模块使用,比如科学计算、办公自动化、数据分析、Web系统开发等。
作者:程一初
更新时间:2020年8月

若有收获,就点个赞吧
0 人点赞
