其实我们已经接触过函数。
比如,之前使用过的那些Python内置函数。
- 判断数据类型和地址的
type()和id() - 用于输入输出的
input()和print() - 列表元素打包和累加的
zip()和sum() - 生成序列获取长度的
range()和len() - 计算序列最小和最大值的
min()和max()
还有一些被用于类型转化、比较、排序等场景,全部的内置函数如下。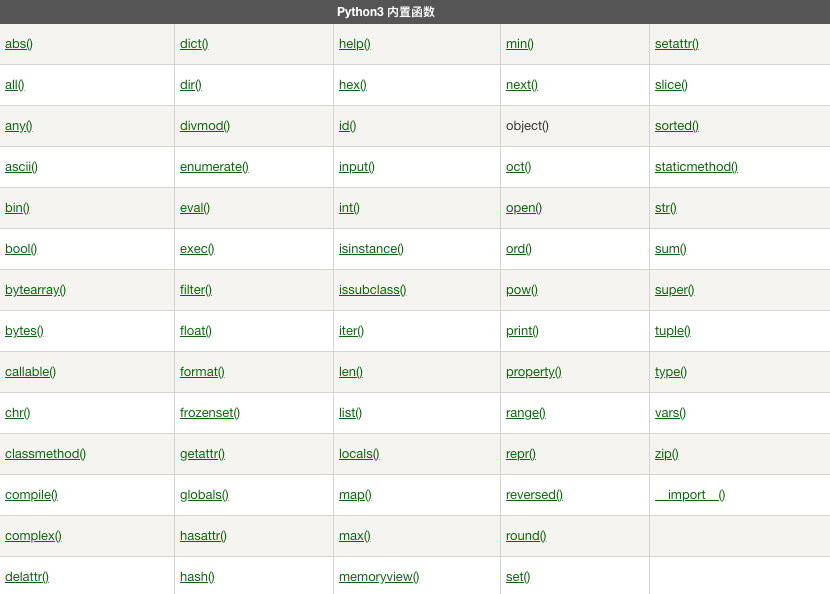
Python3内置函数表
我们没有必要去记住所有的内置函数,关键是在遇到问题时,能想起好像有那么一个函数可以帮助解决问题。因为这些函数的具体用法,随处可查。
为什么要函数?
虽然上面说了不少函数的价值,但得亲身感受一下才能体会。
比如,还是拿之前计算从1到100累加的问题。
最早我们用循环的方式来计算。
total = 0for i in range(101):total += iprint(total) # 5050
后来我们学会了利用Python内置函数sum(),一句话解决问题。
sum([i for i in range(101)]) # 5050
再增加一些工作量,计算下方各整数序列的累加之和。
[70, 76, 6, 45, 26, 39, 51, 83, 34][63, 3, 50, 78, 58, 50, 5][66, 85, 45, 66, 74][45, 94, 94, 2, 71, 23, 43, 20][58, 25, 88, 78, 50, 57, 91, 10, 72][46, 0, 8, 78, 75, 74, 13, 9, 79, 83][12, 65, 43, 66, 47, 18, 53, 99][48, 100, 53, 61, 63, 50, 44, 8, 59, 98][68, 33, 60, 91, 3][47, 45, 9, 29, 16]
如果用第一种方式,你就得复制拷贝很多次for-in代码,把一个个列表贴近去计算。
或者聪明一些的你会选择改成两层循环结构,但不得不修改原来程序的代码。
改代码次数越多,犯错几率也越大。当情况越来越复杂,最后你可能连自己写的代码都认不出。
用内置函数sum()求解问题,它至少保证了行为的确定性,即:
输入一个整数序列给它,它一定给你返回这个序列所有元素之和。
“风雨无阻,使命必达”,只要你不改变它,它就能保证完成任务。
本节内容主要包括:
- 函数的结构:定义函数与调用函数
- 变量作用域:变量的生命周期与可用范围
- 参数返回与异常:参数类型与传递、返回值、异常处理
- 特殊函数:递归函数,匿名函数
1、函数结构
定义一个函数,需要遵守几个约定:
- 函数代码以
def关键词开头,函数名建议用小写英文 - 名字后接小括号
(),包含传递的参数,以:结尾 - 函数代码块需要缩进,建议在首行添加函数注释文档
- 如需返回结果给调用方,用
return结束并返回值
基本结构如下:
def function_name( params ):"""函数文档注释可以在这里说明函数接收什么参数也可以告诉调用者作用及返回内容"""# do_something...return something
我们也自定义一个sum()函数,为了不和Python内置函数重名,我们用my_sum来命名。
注:也可以用sum()命名覆盖内置函数,如果想重新调用内置函数时,可以用
del命令从内存中删除自定义函数,比如:del sum,再调用sum()时就是内置函数了。
def my_sum( nlist ):""":params nlist: 提供一个整数list:return 返回序列内所有整数之和"""n = 0for i in nlist:n += ireturn nprint(my_sum([1,2,3])) # 6
看,是不是挺简单。
其实就是把我们之前的代码,搬到一个函数结构体内,头部是函数名和定义,尾部是返回。
n = 0nlist = [1, 2, 3]for i in nlist:n += iprint(n)
2、变量作用域
当代码搬到了函数结构体内,变量如n就不能在函数之外被访问了。
因为变量有它自己的”生存空间”:
- 你在函数内定义的变量,就活在函数里,当函数结束它也就消失了,我们通常叫它“局部变量”。
- 如果你是在函数外部定义的变量,比如直接在某个脚本文件里,它就能在脚本任何地方被访问到,我们通常叫它“全局变量”。
举个例子:我们想定义一个函数,在给它传递的参数(整数)基础上加1。
n = 99def add_one():n += 1add_one()print(n)
你觉得会输出多少呢?99还是100?
答案是出错!
UnboundLocalError: local variable 'n' referenced before assignment
解释器在提醒你:局部变量n还没定义就使用了。
你可能会觉得诧异,明明已经定义了全局变量,为什么会变成局部变量?
因为Python约定在函数内使用的都是局部变量,除非你“特别说明”它是一个全局变量,比如:
n = 99def add_one():global n # 特别标注n += 1add_one()print(n)
这时候,函数内的n就是我们在外面定义的那个全局变量了。
但,一般情况下,我都不建议你用全局变量,因为它会让代码更难理解,也可能会出现意想不到的错误。
传递数据给函数,应该通过参数。
3、参数返回与异常
比如一开始,我们给sum()函数指定了接收一个整数list的参数nlist。
然后我们在调用时,把一个整数列表[1,2,3]传递给了函数sum([1,2,3])。
函数就可以根据定义,在内部通过nlist这个变量来访问整数列表[1,2,3]了。
我们通常称nlist是一个参数变量,它也是属于函数内的局部变量。
当我们计算出结果,就可以通过return语句,把结果返回给调用者,赋值给了变量x。
看起来似乎一些正常,但却隐藏着2个危机:
- 我们传递给
sum()的整数列表,会不会被改动? - 调用时,如果不小心写成了
['1', '2', '3']的形式,会怎样?
3.1 参数传值
关于第一个问题,我们以Python内置函数min()做一个演示。
我们都知道min()可以帮我们获得一个序列中的最小值。
假设我们现在自己来设计这个函数,就叫它my_min。
现在有这么个场景:我们要简单计算一下自己的绩效,但计算前想先看看自己最差的成绩。
绩效的计算和上一节的应用类似,按权重把成绩累加即可。
我们一开始可能并不会最小值算法,但我们已经知道list有一个排序方法叫sort。
于是就想:不管它性能咋样,从小到大排个序,取第一个不就是最小元素了嘛。
说干就干:
def my_min( nlist ):"""用于找出整数列表中最小的那个整数:params nlist: 一个整数list:return: nlist中最小的那个整数"""nlist.sort()return nlist[0]l = [8, 5, 3, 9, 4] # 成绩表m = my_min(l) # 最差的成绩print(m)w = [1.0, 1.2, 1, 1, 1] # 权重表score = sum([ a * b for a,b in zip(l,w) ])# 我们预期的是:8+6+3+9+4=30print(score)
数字很简单,我们预期的输出应该是30,结果输出的是29.8!哪里错了呢?
如果在调用my_min(l)后我们再查看下列表的数据,就会发现已经被排序了。
也就是说,函数my_min()内执行的排序操作,最终也反映到了我们的原始数据上。
但你可能会想,明明一个叫l,一个叫nlist,排序是在nlist上操作的,为啥l也会变化?
不知道你是否还记得,在“基础语法”中我讲过一句话:变量本质是指向了数据的内存位置,是一个地址。
如果你想起来了,我们一起设计一个实验,看看l和nlist到底是怎么回事。
def func(sth):print(id(sth))a = [1,2,3]print(id(a))func(a)
这个实验中,我们做了这几件事:
- 首先定义一个函数
func(sth),它只做一件事,就是把参数变量sth的内存地址打印出来。 - 然后,我们定义了一个列表,赋值给了变量
a,并打印了a的内存地址。 - 最后我们把
a作为参数调用了函数func(a)
结果,你会发现,打印出来的两行数字,一模一样!
也就是说,变量a和参数变量sth,其实背后代表的是同一个东西,那就是列表[1,2,3]。
所以,不管是对a操作,还是对sth操作,都会反映到列表[1,2,3]上。
比如,你可以参考上面的方法,也设计一个实验,在函数内往
sth里添加元素,函数执行完毕后,外面的变量a也可以访问到你新添加的元素。
这时候,你是否想起,Python的数据类型和数据结构,有分“可变”和“不可变”两种:
- 不可变:
int、float、str、tuple - 可变:
list、set、dict
如果你分别用上面这些数据类型和数据结构放入实验,就能深刻体会到“不可变”数据类型的重要和好处了。
Python函数调用中,参数以“引用”方式传递值,即传递的是一个内存地址,通常我们叫它“浅拷贝”。
这样,你就能明白,传递参数,其实就是把变量名字复制了一份,数据还装在它代表的那块内存里躺着。
搞明白参数是怎样传递数据很重要,不过只要你能正确理解变量的本质,其实也不是很难。
3.2 参数类型
我们已经知道:
- 通过写一个变量名,放在函数名后面的小括号中,就可以接收数据。
- 参数变量代表的数据,和调用时传入变量代表的数据,是同一份。
接下来,我们看看函数定义参数的其他形式。
如果只有一个参数,调用起来也不会麻烦,但如果参数有一堆,怎么办?
比如,你在录入全班学生健康信息,有身高、体重、性别、视力、健康状况等等。
也许你能很快写出录入信息的函数:
def collect_stu_info(height, weight, sex, vision, health):"""收集学生健康信息:param height: 身高, float:param weight: 体重, float:param sex: 性别, male, female:param vision: 视力, (左, 右), eg. (2.0, 2.0):param health: 健康等级,Good, Normal, Bad"""# do some stuff like store to databaseprint(height, weight, sex, vision, health)collect_stu_info(160.5, 60.5, 'female', (1.5, 2.0), 'Good')collect_stu_info(170.5, 70.5, 'female', (1.5, 1.0), 'Good')
但你会发现调用函数的时候,非常麻烦,每次都得写一堆数据。
尤其是当整个班同学都很健康,但我们调用时还得写上健康状况,不然无法成功调用函数。
3.2.1 默认参数
好在,我们可以借助“默认参数”来省力,即在定义时给参数一个默认值。
def collect_stu_info(height, weight, sex, vision, health='Good'):"""同上"""print(height, weight, sex, vision, health)collect_stu_info(170.5, 70.5, 'female', (1.5, 1.0))collect_stu_info(170.5, 70.5, 'female', (1.5, 1.0), 'Normal')
这样,除非我们发现一些特例,就把全部参数值都写上,平时可以省点力。
当心!!!
但需要注意的是,如果你的参数代表一个“可变”数据结构,比如list,那你就得当心了。
虽然你可以给它提供一个默认值如[],但这个[]会一直成为该参数的默认值,也就是参数变量始终代表[]所在内存里的数据。同样,我们设计一个实验方便理解。
def func(l = []):l.append('x')print(l)func()func()
我们连续调用了两次函数,第二次调用时,默认参数值已经有两个字符了。
所以,一般建议只用“不可变”数据类型作为默认参数。比如我们案例中的健康值health就是一个不可变的字符串。
此外,我们还发现大部分同学都是女同学(也许是女子高校),那性别能否也省掉呢?
def collect_stu_info(height, weight, sex='Female', vision, health='Good'):"""同上"""print(height, weight, sex, vision, health)collect_stu_info(170.5, 70.5, (1.5, 1.0))
调用后,我们发现出错了!
SyntaxError: non-default argument follows default argument
解释器提示我们:在默认参数后面,有非默认参数存在,案例中就是vision这个参数。
所以,在使用默认参数时,一定要把默认参数放在最后面。
于是,我们尝试把最后三个都变成默认参数,改成了这样:
def collect_stu_info(height, weight, sex='Female', vision=(1.5,1.5), health='Good'):"""同上"""print(height, weight, sex, vision, health)collect_stu_info(170.5, 70.5, (1.0, 1.0))
在录入数据时,我们想修改下某个学生的vision,却得到了这样的结果:
170.5 70.5 (1.0, 1.0) (1.5, 1.5) Good
很明显这不是我们想要的。如果有多个默认参数存在,当我们提供了“足够多”值时,会从前到后满足参数传递。
3.2.2 关键词参数
这时候,我们可以用关键词参数来指定传递给的是哪个参数,即在调用时明确指出传递给谁。
def collect_stu_info(height, weight, sex='Female', vision=(1.5,1.5), health='Good'):"""同上"""print(height, weight, sex, vision, health)collect_stu_info(170.5, 70.5, vision=(1.0, 1.0))collect_stu_info(160.5, 50.5, health='Normal')collect_stu_info(170.5, 80.5, sex='male')collect_stu_info(weight=60, height=175, health='Normal', sex='male')
使用关键词指定参数,我们就可以不用关心提供参数的顺序,因为它是明确的。
3.2.3 可变长参数
还有一种情况,当我们在设计时,并不知道要接收多少个参数,怎么办?
比如,收集健康信息时,部分同学还有额外信息需要收集,比如更详细的检查。
因为无法预测有多少科目,所以我们事先无法确定有哪些参数,甚至无法知道有几个参数。
这时候,我们就需要“可定长”参数来定义函数。
def collect_stu_info(height, weight, sex='Female', vision=(1.5,1.5), health='Good', * options):"""同上"""print(height, weight, sex, vision, health, * options)collect_stu_info(170.5, 70.5)collect_stu_info(170.5, 70.5, 'Female', (1.5, 1.5), 'Bad', '血液检测正常', '心电图正常')
其中* options是可变长参数,如果你再仔细留意,会发现options其实是个tuple。
在函数内通过
type(options)就可以观察到它的数据类型了。
也就是说,当调用时传递的参数超过了指定需要的参数后,剩下的可以通过可变参数来收集,Python会把那些剩下的打包成tuple后传入函数内。
还有一种方法来实现可变长参数,就是利用dict:
def collect_stu_info(height, weight, sex='Female', vision=(1.5,1.5), health='Good', ** options):"""同上"""print(height, weight, sex, vision, health, options)collect_stu_info(170.5, 70.5, option1='血液检测正常', option2='心电图正常')collect_stu_info(170.5, 70.5, 'Female', (2.0, 1.0), 'Bad', option1='血液检测正常', option2='心电图正常')
输出的结果如下:
170.5 70.5 Female (1.5, 1.5) Good {'option1': '血液检测正常', 'option2': '心电图正常'}170.5 70.5 Female (2.0, 1.0) Bad {'option1': '血液检测正常', 'option2': '心电图正常'}
可以看到,用** options实现可变长参数后,调用时我们可以随意指定成对的参数名-值,Python会帮我们把那些没有写在函数定义的参数,打包到一个dict中。
做个小结,函数定义参数有5种基本形式:
- 无参数,即函数不接受任何参数
- 位置参数,即必须提供的参数,可以按顺序或关键词指定
- 默认参数,为参数指定一个默认使用值(指定后不变)
- 可变长参数:接收调用时传入的额外参数
- 可变长命名参数:接收额外参数的同时,给出参数名字
3.3 返回”多个值”
到这里,我们已经了解了函数的定义和调用。
正常情况下,当函数执行结束,它要么直接退出,要么通过return语句返回数据。
通常我们只能返回一个数据,但如果恰好这个数据是个tuple,我们就可以省去小括号,看上去像返回了多个数据一样。
还记得多个变量的赋值情况么?
x, y = 1, 2x, y = (1, 2)(x, y) = (1, 2)
上面三种赋值效果一样。
所以,我们也可以让函数返回一个tuple,比如:
def get_point():"""some notes"""return 1, 2x, y = get_point() # 1, 2(1, 2) == get_point() # True
4、异常处理
但是,如果函数没有成功结束,会怎么样?
我们知道,当我们执行1+'1'时,会出现如下错误:
TypeError: unsupported operand type(s) for +: 'int' and 'str'
那如果这个错误出现在函数中时会怎样?
比如,我们调用一开始写的my_sum()函数:
my_sum(['1','2','3'])
结果解释器也报出了TypeError的错误,因为我们不小心把数字写成了字符串。
4.1 设计错误代码
我们可以自己设定一些错误代码,让函数在最后返回给调用者。
def my_sum( nlist ):"""同上"""n = 0if not isinstance(nlist, list):return -1 # 代表nlist不是列表for i in nlist:if not isinstance(i, int):return -2 # 表示有一个数不是整数n += ireturn nprint(my_sum(['1',2,3]))
简单情况下,这样的方式也足够应付错误。
但实际情况往往更复杂,如果每个函数都要定义一套自己的返回码,不仅难用,也易与正常功能混淆。
所以,我们需要更通用的错误解决办法,它就是“异常处理”。
4.2 异常机制
你之前看到的TypeError、UnboundLocalError、SyntaxError等,都是Python事先定义好的异常类型,它们的出现说明程序在执行中发生了对应类别的错误,所以你也就可以跟随着这些信息去找错误的源头。
异常处理,就是我们提前估计可能会出现的错误,提前想好应对策略。
比如,我们可以把my_sum()函数修改如下:
def my_sum( nlist ):"""同上"""n = 0try:for i in nlist:n += iexcept TypeError as e:print('类型错误', e)else:return nprint(my_sum(['1',2,3]))
程序不再出现TypeError,而是输出了我们自己定义的内容。
这里我们用到了Python的try-except-else异常处理结构:
try里面放我们需要执行的代码,需要缩进except指出可能有什么类型错误,可选择接as访问错误- 如果没发生异常,则执行
else分支。
我们再看Python内置的sum()函数,如果执行sum(['1',2,3])也会报错。
那是否就说明它设计不好呢?其实不是。
异常的意义在于:辅助错误处理。
但如果滥用异常处理,会隐藏错误信息,让排查问题更困难。
TIP:异常处理在软件设计中经常被用到,暂时可以不用考虑如何设计,掌握基本使用即可。
5、特殊函数
Python中的函数可以非常灵活,比如可以内嵌,支持闭包(closure)等等。
但从实用角度,我们主要介绍2种特殊点的函数,一个是“递归函数”,一个是“匿名函数”。
这部分内容可以当了解来学习,因为你可能会在不少地方看到这样的写法,至少能看懂什么意思。至于是否使用,可以按自己的理解程度来尝试实践。
5.1 递归函数
我们之前介绍过Python实现循环的2个主要方式:for-in和while,其实还有一种方式。
还以从1~100的整数之和作为案例:
def func(n):"""some notes"""if n==0:return 0return func(n-1) + nprint(func(100))
在案例中,我们定义了一个函数func(),它接收一个整数作为唯一参数。
但是它返回的数据,需要再一次调用自己,这就是一种最简单的递归函数。
递归函数也是一种循环,它借助了函数“调用栈”来完成,所以它能完成的循环次数,与栈大小有关,比如默认的函数调用栈最大值是1000,超过后,就会提示如下错误:
RecursionError: maximum recursion depth exceeded in comparison
注:“栈”也是一种数据结构,它的特点是:“先进后出”,就像你叠衣服,最先叠好的会被放在下面,最容易拿的是最后放在上面的那件。
函数在被调用时,程序就会先执行函数内部的代码,等到执行完毕,才会继续执行外部其他剩余代码。
同样的,如果函数内调用其他函数,也会先进入其他函数执行完毕后,再执行本函数内剩余代码。
def h():print('h', end=' ')def e():print('e', end=' ')def l():print('l', end=' ')def o():print('o', end=' ')def hello():h()e()l()l()o()print('python')hello() # h e l l o python
每一次调用函数,都会把当前代码位置保存在’栈’中,等函数执行结束,再返回到当初的现场。
关于递归函数,只需要了解函数调用方式即可。递归函数有两个要点:
- 必须在某个时刻能结束,比如上面当
n=0就直接返回0 - 必须在调用中形成循环,比如自己调用自己是最简单的形式。
最后,递归函数都可以被写成for-in或者while的循环方式。
5.2 匿名函数
上面我们看到函数定义时都有一个名字,比如sum、my_sum。
当我们需要重复使用时,通过名字可以方便调用函数。
但有一些情况,我们并不需要隆重地写一个函数,我们要的只是个计算组合过程。
比如,给出一堆点坐标(x, y),要求计算出它们与原点(0, 0)间的直线距离。
两点间直线距离的计算公式:

其中(x2, y2)是原点(0, 0)。
我们可以定义一个函数来解决问题。
其中根号计算可以借助Python标准库math里的函数,通过import语句使用第三方代码库。
import mathdef distance( plist ):"""计算所有点与原点(0,0)的直线距离平方:param plist: 点的列表,点坐标如(x, y):return: 直线距离平方的列表"""l = []for x, y in plist:d = math.sqrt(x**2 + y**2)l.append(d)return lp = [(1,1),(2,2),(3,3)]ds = distance(p)
当然,我们也可以直接用Python生成器完成:
import mathp = [(1,1),(2,2),(3,3)]ds = [ math.sqrt(x**2+y**2) for x, y in p ]
当表达式越来越复杂时,我们可以利用匿名函数把计算过程抽取出来,方便阅读的同时不必专门定义一个函数。
import mathf = lambda x, y : math.sqrt(x**2 + y**2)p = [(1,1),(2,2),(3,3)]ds = [ f(x, y) for x, y in p ]
可以看到,匿名函数的3个特点:
- 用
lambda开头,接着可以有参数也可以没有,:后接代码 - 不需要
def声明,也不需要指定特定名字 - 不需要
return关键词也可以返回值
匿名函数相比普通函数更快捷,非常适合临时的数据计算。
此外,它和下面2个Python内置函数一起用时,能解决很多快速数据统计的工作。
filter():把一个序列根据某个函数过滤出出新序列map():把一个函数应用到序列中每一个元素,返回新序列
我们用3个案例来了解下它们的用法:
# Case1: 过滤出所有偶数nlist = [ i for i in range(10) ]f1 = lambda x: x % 2 == 0l1 = filter(f1, nlist)print(list(l1))# [0, 2, 4, 6, 8]# Case2: 所有元素都变成它们的平方数f2 = lambda x: x**2l2 = map(f2, nlist)print(list(l2))# [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]# Case3: 只获得偶数的平方数l3 = map(f2, filter(f1, nlist))print(list(l3))# [0, 4, 16, 36, 64]
从第3个案例可以看到,函数之间可以方便地叠加运算。
对应生成器的写法:
l3 = [ i**2 for i in range(10) if i%2==0 ]
相比生成器,匿名函数更通用。
但在实战中,我们没必要刻意使用匿名函数,生成器更方便时,为什么不用呢?
总结
本节中,我们重点介绍了Python函数的用法,包括其结构定义方式、参数及值传递方式、返回及异常处理,最后也介绍了递归和匿名2种特殊函数写法。
在实践中,跟我们打交道更多的是普通函数,这部分一定要掌握牢固,尤其是参数及传递值。有时候,资深程序员也免不了犯一些基本错误,比如参数里包含了可变数据,结果花了不少时间调试后才发现。
特殊函数,作为了解即可,因为掌握Python生成器更“实惠”,能更方便应用于实践。讲特殊函数的目的,是展示思考问题的一种角度。
作者:程一初
更新时间:2020年8月

若有收获,就点个赞吧
0 人点赞
