在“基础语法”章节,我们已经学会了命令行终端下的输入输出。
其实,整个计算机都是由输入输出组成的。
比如,你打开一个网页,浏览器这个程序就开始忙起来:
- 浏览器会从远处的服务器那获得内容数据,计算机的网卡灯开始闪烁;
- 获取的数据会被输入到内存,大一点的被保存在磁盘;
- 浏览器根据数据格式解析数据,有些输入CPU,有些输入显卡;
- 根据计算结果,最后你会在屏幕上看到文字、图像等信息。
当然,这是一个非常非常粗略的描述,主要是让你感受到数据的流动。
程序的每一个环节,计算机主板上的每一个部件,都在接收数据、加工数据、输出数据。
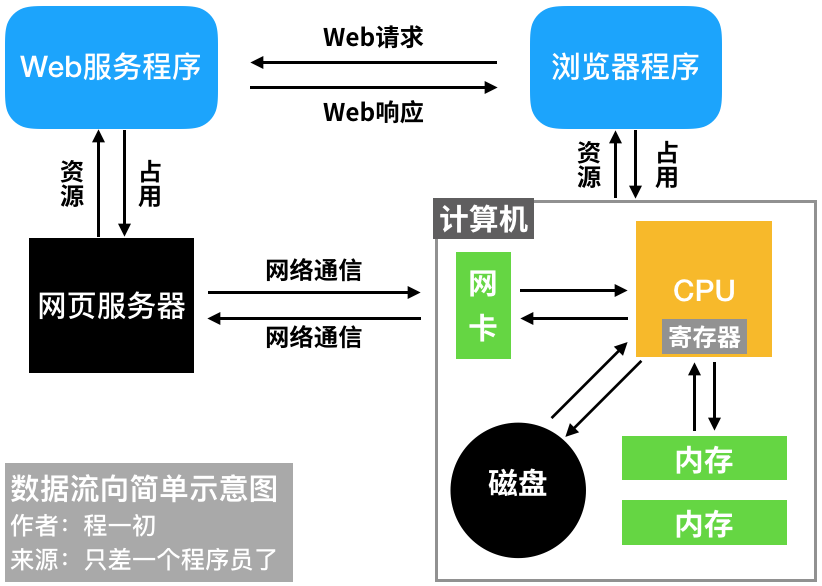
数据流向简单示意图
程序中的数据,比如我们之前用过的那些变量,都在内存中,当程序退出或计算机关机,这些数据就会消失。所以,我们会把一些重要数据保存到磁盘,俗称“数据持久化”。
磁盘操作,是早期计算机最主要也是最重要的功能。
微软Windows操作系统的前身,是“DOS”(“Disk Operating System”),即磁盘操作系统。
直到现在,我们依旧可以通过命令行来管理文件,只不过大部分人已经习惯了图形界面操作。
但在一些情况下,命令行方式,会远远比操作图形界面更方便、高效。
举个最简单的例子:批量文件重命名。
在Windows系统的图形界面,如果你想批量修改一批文件名,可以全选文件,然后按F2进行修改,这时候所有选择文件会按你输入的文件名,以名字(1)的形式命名。
但也只能以XX(n)这种形式修改,如果想要更个性化的命名方式,就得安装额外辅助软件,比如微软”PowerToys”系列中的“PowerRename”工具(你可以在github上找到它)。
但如果用命令行方式,就简单多了:用一个循环遍历所有文件名并修改。
比如,写一个Windows的BAT脚本文件:
@echo offsetlocal enabledelayedexpansionset a=1for %%n in (*.png) do (ren "%%n" "hello_world_!a!.png"set /a a+=1)
MacOS和Linux中相对容易,直接在终端中执行:
a=1;for i in *.png;do mv "$i" "hello_world_"$a".png";((a++));done
你可以看到,在不同操作系统上,“命令行”长得也不一样,尤其是Windows上的CMD,谁用谁知道。
就算是MacOS和Linux上的命令,很多调用方式也不同,这里就不展开了。
举这个案例只想说明两点:
- 在批量处理文件时,命令行比图形化界面更灵活方便。
- 不同操作系统间命令行不兼容,对于普通人的门槛高。
不少跨平台的语言能解决兼容问题,但Python无疑是最受欢迎的选择。
所有文件处理,都建立在现代操作系统之上。我们首先要掌握的就是如何处理操作系统的文件。
本文主要内容包括如下:
- 文件和目录:操作系统标准概念
- 文本文件读写:字符文档处理
- 图片文件读写:二进制图片处理
- 应用案例:批量生成手机海报
1、文件和目录
操作系统给了我们一套标准方法,来有效利用磁盘保存数据,那就是“文件”。
首先,理清3个关键概念,可以帮助更好学习文件管理。
- 文件:内容数据的载体,如图片文件,根据类型不同有对应后缀名(
png、jpeg)。 - 目录:就是“文件夹”,方便文件分类整理,可以层层嵌套,第一层叫“根目录”,如Windows上以
C:表示,MacOS和Linux上以/表示。 - 路径:文件或目录的访问地址,比如
/home/yichu/hello.txt、../a.txt、b.txt。第一类以根目录为开头,通常叫“绝对路径”,第二类以..开头叫“相对路径”,第三类只写文件名表示在当前目录下的某文件,也是相对路径。
1.1 操作系统命令
在操作系统的命令行里,我们可以用类似下面的命令来管理文件夹和文件。
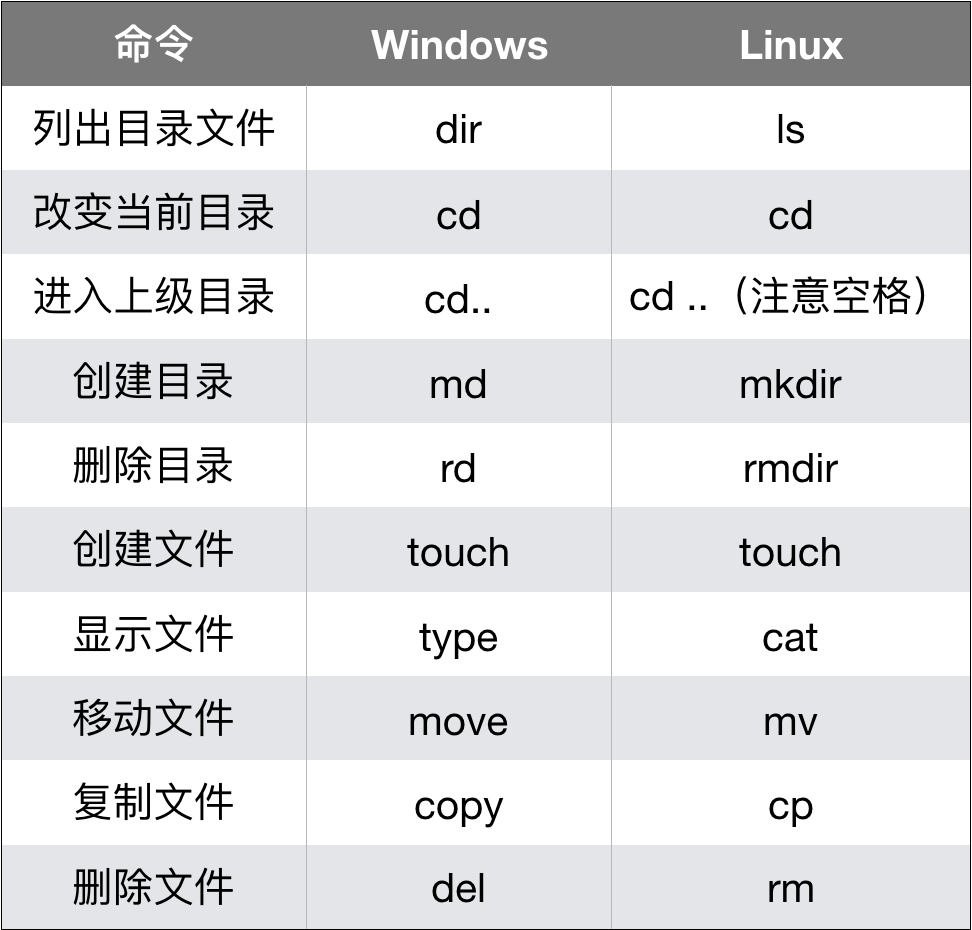
常用操作系统文件管理命令
而在应用程序中,我们可以通过调用操作系统定义好的接口,执行读取文件、写入数据、保存文件等操作。
接口:是一套标准的调用方法,比如我们手机充电线,有苹果线接口、Type-C接口。
1.2 Python文件管理模块
Python内置了三个模块方便程序调用操作系统的文件管理能力:os、shutil、pathlib。
通过它们就能用Python管理文件了,使用时只需把模块引入程序即可使用。其中,pathlib在Python的3.4版本时加入,在版本3.6后基本成熟,它在处理文件路径等方面比os更有优势。
比如我们可以查看所用操作系统的名称:
import osprint(os.uname())
如果是MacOS,就会输出类似下面的内容。
posix.uname_result(sysname='Darwin', nodename='ichengplus', release='17.7.0', version='Darwin Kernel Version 17.7.0: Wed May 27 17:00:02 PDT 2020; root:xnu-4570.71.80.1~1/RELEASE_X86_64', machine='x86_64')
对照上面操作系统的命令,模块调用方式如下。
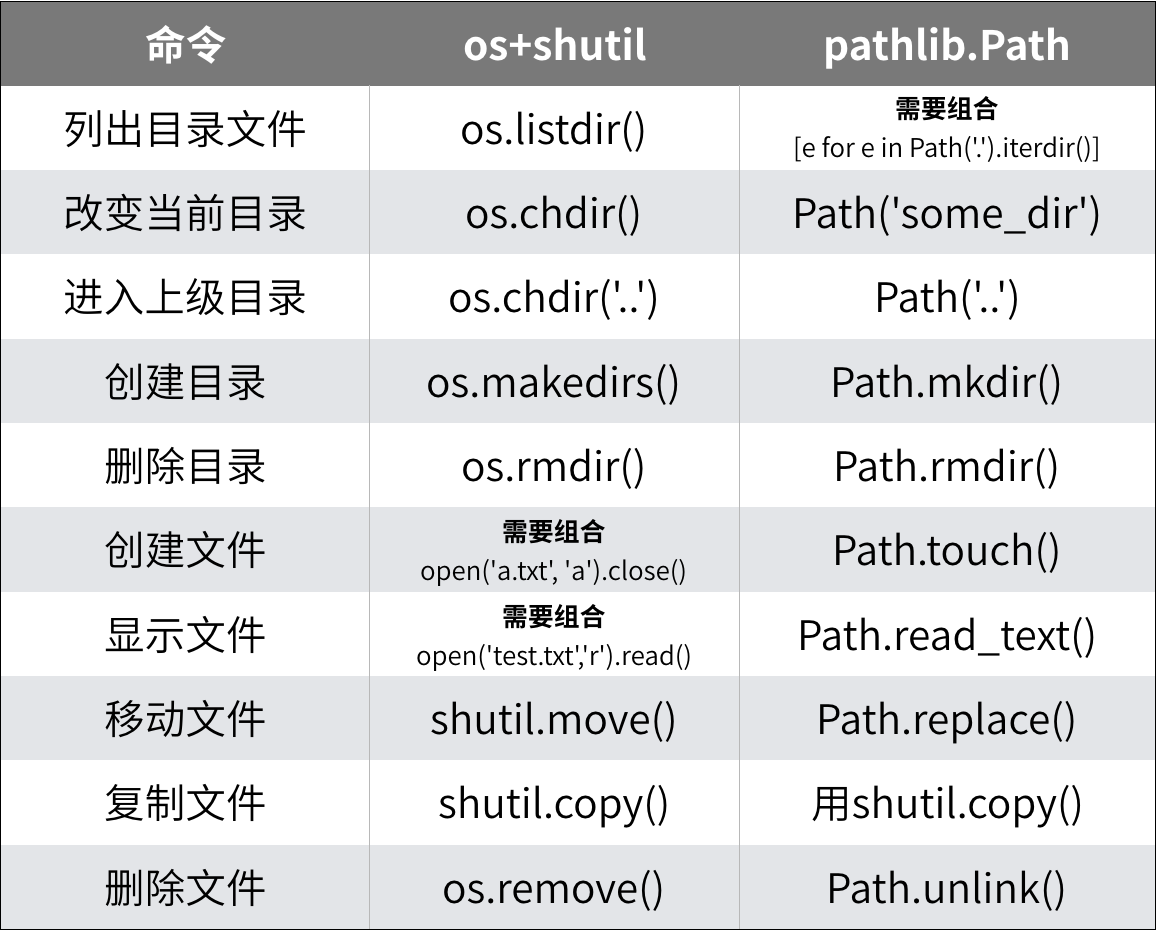
Python文件和目录处理方法
比如上面“批量重命名文件”这个案例,用Python可以这么写:
# 为了安全演示,先临时创建一个文件夹和一批临时文件from pathlib import Patht = Path('temp_dir')t.mkdir()for i in range(10):a = t.joinpath('a_{}.png'.format(i))a.touch()# 以下为批量重命名代码for i, p in enumerate(t.glob('*.png')):name = p.with_name('hello_{:02d}.png'.format(i+1))p.rename(name)
简单说明下:
- 为了让你测试代码时不至于把正常文件替换,先临时创建一个目录
temp_dir,然后在里面创建10个空的png文件; - 批量改名只需一个循环,把所有文件按统一格式重命名;
- 其中
with_name()可以辅助生成包含路径的新名字;glob('*.png')表示所有.png结尾的文件;rename()用来重命名文件。
操作系统通过文件和目录的管理,实现磁盘存储空间利用以及数据组织。
但,如何理解数据,以及如何处理数据,并不是文件和目录的管辖范围,而是由各个应用程序来定义。
每一种文件都有自己的格式,比如
- 文本文件,除了内容字符外,还有表示换行、结尾等格式信息。
- 图片文件,有
png、jpeg、gif等格式,之间不兼容。 - 视频文件,有
avi、mov、mpeg等格式,之间也不兼容。
我们能在操作系统上打开这些内容的前提,是安装好了对应的处理程序。比如系统自带的文本编辑器、图片查看器,以及视频播放器等。
这些软件本身就是通过编程实现的,Python通过三方模块也支持大部分格式文件处理。
文件格式,就是一种数据组织形式,用这套格式把数据存储到磁盘上,下次想访问时,就按同样的格式读取即可。所以,理论上你完全可以自己定义格式,实现一套自己的文件存储方法。当然,这不是我们现在想讨论的话题。
2、文本文件
最普通的文件就是文本文件,它的数据内容就是字符文本,字符通过编码保存到文件。
2.1 字符编码
字符编码在Python2是个灾难,Python3最重大的变化就是str数据类型默认使用Unicode编码,这是一种全球主要语言的编码。
你可以不用理会编码是如何实现的,只需记住在程序所有地方使用UTF-8编码,比如在Python程序文件的首行,添加编码提示# coding=utf-8,保存代码文件时也选择UTF-8。
如果你用比较新的工具编辑Python代码,如VSCode,就不必太担心,它默认也用UTF-8 。
2.2 读写文件
Python提供了open()内置函数帮我们打开一个文件,每次打开文件,都会占用操作系统的资源。
由于操作系统同一时间能打开的文件是有限的,在我们处理文件后,不管成功与否,需要用close()内置函数关闭文件。
上一节“函数”中我们介绍过try-except-else的异常处理结构,我们这次借用它的“变种结构”演示:
try:f = open('hello.txt', 'w')f.write('Hello Python')finally:if f:f.close()
异常处理的完整体是try-except-else-finally,这里的finally指的是不管是否出现错误,都会执行的分支。也就是,不管我们写入文件是否成功,都尝试把文件关闭。
打开文件时,我们需要指明打开的模式,常用的包括:
'w':写文件,如果已存在就会覆盖内容'a':写文件,如果已存在会在最后追加内容'r':读文件'rb':以二进制读文件'wb':以二进制写文件
读取本文文件,我们用'r'的打开模式:
try:f = open('hello.txt', 'r')print(f.read())finally:if f:f.close()
每次读写文件都得加上try-finally有点麻烦,好在Python给我们提供了一种语法:with。
with open('hello.txt', 'r') as f:print(f.read())
这样的写法,效果和上面一致,在with中的代码块执行完毕后,会自动调用close()方法,代码更简洁。read()函数返回的是一个str数据类型。
如果想分行读取文件,可以用readlines():
with open('hello.txt', 'r') as f:d = f.readlines()for i in d:print(i, end='')
其中,变量d是一个list,每一行文本是一个str元素。
文本文件是最基础的一类文件,它的内容由字符组成。
其实HTML网页文件也是一种文本文件。只不过在字符之上,我们还增加了一些规则,形成了html格式,并用浏览器去读取内容。
可以做个小实验:用Python写一个最简单的网页。
html_code = ['<html>','<title>','Hello from Python','</title>','<body>','<h1>', 'Hello HTML!','</h1>','</body>','</html>']with open('hello.html','w') as f:f.writelines(html_code)
其中writelines()方法可以把一个列表中所有字符串都按行写入文件。
然后,你可以用浏览器打开这个文件hello.html,这就是一个最简单的网页了。
3、图片文件
文本文件很常见,因为很多数据都是以字符形式存在,比如网页、程序代码等。
但更通用文件形式,是二进制文件。文本文件也不过是用字符编码表示的二进制文件。
想要准确解析文件内包含的数据,必须遵循文件格式的定义。比如头部多少个字节表示什么图片类型、多少字节表示图像数据,多少字节表示相机类型或拍摄时间等等。
一般文件都会在头部包含大部分格式信息,程序读取头部信息后,就知道该怎么处理后面的二进制数据了。只要掌握了格式结构信息,就可以按格式读写它这个类型的文件。
不过在实践中,我们没必要自己去实现文件类型的读写,因为早已有人为Python编写了三方模块,我们只要掌握其调用即可。
3.1 Pillow
最受欢迎的Python图片处理三方模块是 Pillow,它是PIL(Python Imaging Library)的一个分支,但使用最为广泛。我们可以用pip命令安装它:
pip install pillow
然后,我们就可以在程序中调用它的功能了。
处理图片的过程,其实和你用其他软件操作没有本质区别,只不过那些操作,被替换成了Python代码实现。比如图片拉伸、缩小、裁剪、合并、通道颜色变换等等。
我们可以用代码生成一张图片:
from PIL import Image, ImageDraw# 创建背景mode, size = "RGB", (200, 200)width, height = size # 宽, 高bg_color = (32, 64, 128) # 背景色彩im = Image.new(mode, size, bg_color)# 开始绘图draw = ImageDraw.Draw(im)draw.arc((50, 50, 150, 150), start=45, end=300, fill='red', width=5)# 保存图像文件im.save('hello.png', 'PNG')
这里,我们用Image类管理图片文件,用ImageDraw类管理绘图。
类,是面向对象中的基本元素,可以简单理解为模板,约定有哪些数据和行为(方法)。 对象,是从类这个“模板”中生成的“实例”,诞生之初就具备了约定的行为能力。 类和对象在后面章节会完整介绍。
绘制过程如下:
- 首先,用
Image.new()创建了一个对象im; - 其次,用
ImageDraw.Draw()创建了一个绘画对象draw; - 然后,调用绘画对象的绘图方法
draw.arc(),绘制一条红色弧线; - 最后,我们调用图像的保存方法
im.save()来存储图像。
当然,ImageDraw还可以让你绘制椭圆(ellipse)、直线(line)、长方形(rectangle)等各种图形,只需要调用不同的方法即可,方法的参数可以参考其说明。
3.2 应用案例:动态验证码
我们再来看一个案例:
早期互联网应用经常被攻击,其中一种典型方式是批量生成账号,通过写一个脚本就可以批量发起注册请求。所以,直到现在我们经常被要求填写验证码,其实就是为了判断我们是一个“真人”。
看看怎样用Python生成验证码。先整理思路:
- 生成一个图片
- 用一些随机颜色的点覆盖整个图片
- 随机生成4个字符
- 在图片上画出字符
- 把图片做一些特殊处理比如模糊
- 保存图片
参考代码:
import randomfrom random import randintimport stringfrom PIL import Image, ImageDraw, ImageFont, ImageFiltermode, size = "RGB", (320, 80)width, height = sizebg_color = (255, 255, 255)im = Image.new(mode, size, bg_color)draw = ImageDraw.Draw(im)# 创建字体font = ImageFont.truetype('Arial.ttf', 48)# 绘制混淆点for x in range(width):for y in range(height):draw.point((x, y), fill=(randint(64, 255), randint(64, 255), randint(64, 255)))# 从字母和数字中随机生成4个字符text = "".join(random.sample(string.ascii_letters + string.digits, 4))# 绘制字符,随机取4个字符for i, c in enumerate(text):draw.text((80 * i + 20, 20), c, font=font,fill=(randint(0, 128), randint(0, 128), randint(0, 128)))# 模糊处理im = im.filter(ImageFilter.BLUR).filter(ImageFilter.EDGE_ENHANCE_MORE)im.save('code.png', 'PNG')
这里我们用到random和string两个Python标准模块,它们的作用如下:
random用于伪随机生成,randint(x,y)用于生成x~y之间的随机整数,sample(l,n)用来从l序列中随机挑选n个样本;string专门用于处理Python字符串,在内置str基础上增加了更多方法,这里我们用到了它的两个常量ascii_letters和digits,表示英文字符和数字。
从PIL模块中,除了Image和ImageDraw,我们也用了ImageFont和ImageFilter,它们一个用来制定绘图所用字体,另一个用来做图像后期处理,比如模糊和边缘增强。
在绘制字符时,根据每个字符大小和图片整体大小,做些调整让字符显示在中间,这样就完成了验证码的生成。
在实际应用中,所生成的4个随机字符会被存起来,当用户提交数据时,就可以判断是否准确。
应用案例:批量手机海报生成
最后,我们看另外一个实践案例:批量手机海报生成。
自媒体和教育行业,经常需要生成一些定制的海报,提供给用户分享传播。
刚开始只能通过PPT或者PS手工绘制,后来有了很多在线海报设计工具后,省力不少。
可如果遇到需要批量生成不同大小规格的海报时,哪怕用在线工具一个个导出,也得花不少时间。
同样的内容不同的规格,或者局部内容的替换,对于程序而言只是参数变动而已。
一般手机海报上,除了主要内容外,还会有额外信息,如用户头像、二维码、价格、时间等。
问题分析思路
我们暂时忽略需要依赖外部系统的部分,只专注在图像文件处理部分,即:
- 有一个主标题和副标题
- 个性化定制的姓名
- 主要内容如毕业证书内容
- 右下角颁发者签名及日期
参考代码
主要的代码工作量在绘图,参考代码如下:
from PIL import Image, ImageDraw, ImageFontimport datetime# 定义一些内容和参数大小student_name = '张三'text_content = '恭喜你已经成功毕业!再接再厉!'author = '程一初'title_font_size = 64text_font_size = 30comment_font_size = 20title_cn = '毕业证书'title_en = 'Graduate Certificate'# 创建一个空白的黑底图片mode, size = "RGB", (640, 1024)width, height = sizebg_color = (38, 38, 38)im = Image.new(mode, size, bg_color)draw = ImageDraw.Draw(im)# 中间画2个长方形shape_rect = [(40, 40), (width - 40, height - 40)]draw.rectangle(shape_rect, fill="white", outline="gray")shape_rect_inner = [(60, 60), (width - 60, height - 60)]draw.rectangle(shape_rect_inner, fill="white", outline="gray")# 定义字体: 标题, 正文, 标注font_title = ImageFont.truetype('STHeiti Medium', title_font_size)font_title_en = ImageFont.truetype('Arial.ttf', text_font_size)font_text = ImageFont.truetype('STHeiti Light', text_font_size)font_small = ImageFont.truetype('STHeiti Light', comment_font_size)# 绘制标题draw.text((width/2-100, 200), title_cn, 'black', title_font)draw.text((width/2-150, 300), title_en, 'black', font_title_en)draw.line((width/2-180, 350, width/2+150, 350), fill='orange', width=3)# 绘制学员姓名draw.text((width/2-50, 500), student_name, 'black', font_text)draw.line((width/2-80, 550, width/2+50, 550), fill='orange', width=2)# 绘制内容draw.text((100, 700), text_content, 'black', font_text)# 右下角颁发者及时间draw.text((width-250, height-200), author, 'black', font_small)now_date = datetime.datetime.now().strftime('%Y年%m月%d日')draw.text((width-250,height-150), now_date, 'black', font_small)# 生成图片im.save('post.png', 'PNG')# 重新打开图片im_src = Image.open('post.png')w, h = im_src.size# 压缩成1/2, 1/3, 1/4多种尺寸for i in range(2, 5):im_dest = im_src.resize((w//i, h//i), Image.ANTIALIAS)im_dest.save('post_small_{}.png'.format(i),'PNG')
其中,我们通过 datetime模块用于生成当前日期。
可以把这个代码写成函数形式,再通过定义一些参数,就可以完成批量手机海报生成了。
当然,实际应用中,我们需要更美观的图片处理,可以把一些固定不变的内容,做成底版。再读取底版图像,在其基础上绘制动态部分数据,效果更佳。
总结
本文我们学习了操作系统文件和目录管理。
文件以二进制形式存在于磁盘,我们通过约定文件的格式来保存数据。特别当数据是字符时,我们会把字符编码(最常用UTF-8)后保存。
由于操作系统同时打开的文件数有上限,在文件使用后需要关闭它,使用Python的with as语句可以简化代码。最后,我们以图片文件读写,展示了2个实战中的场景:验证码和手机海报生成。
文件读写最基本是磁盘的操作,但数据的多样化,让文件读写有了更多更广泛的用途。
除了文本文件和图像,视频剪辑、数据表格处理、PPT生成等,都可以通过已有的第三方模块方便解决。
作者:程一初
更新时间:2020年8月

若有收获,就点个赞吧
0 人点赞
